







神经网络的发展历程
发展历程
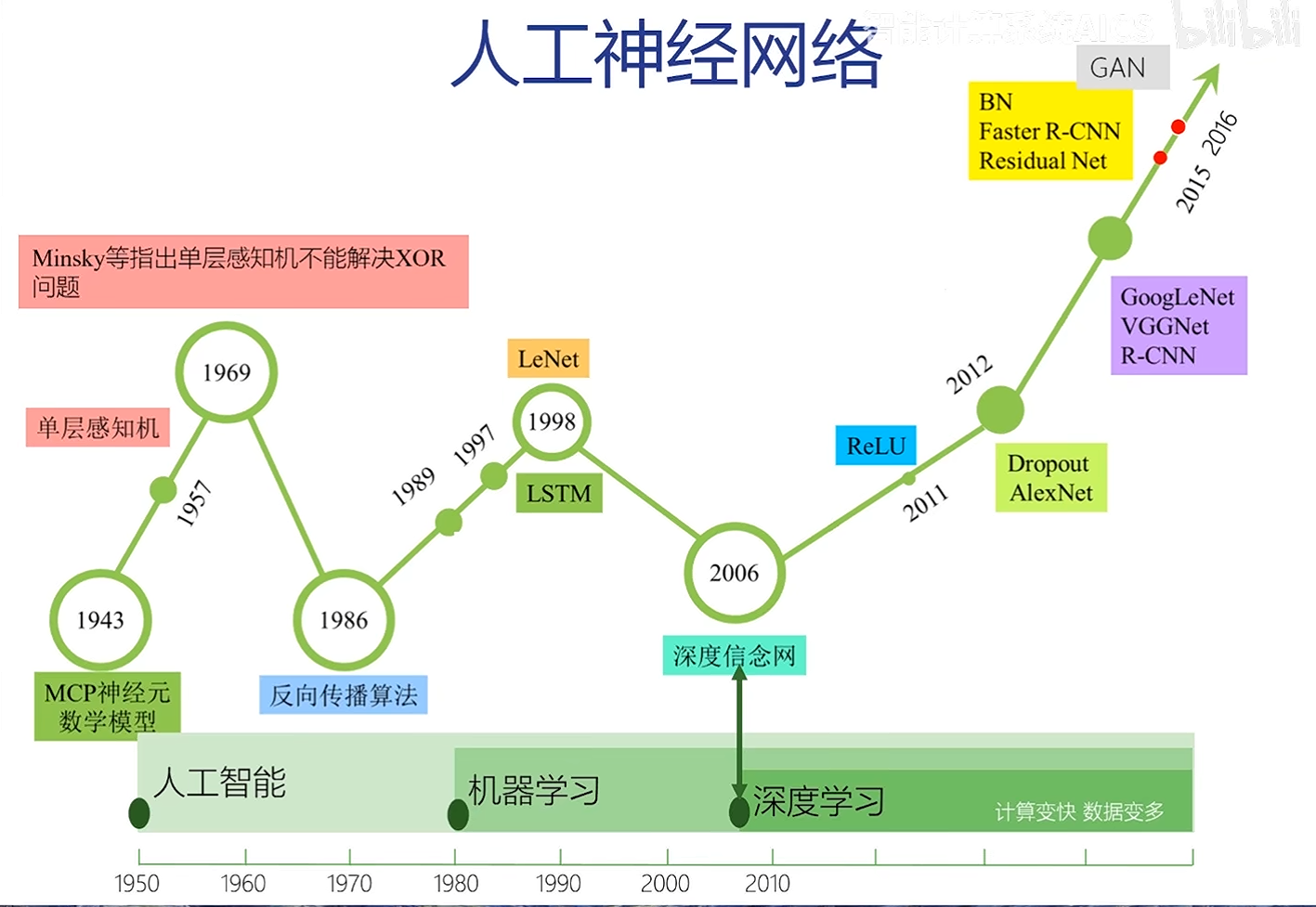
神经网络的发展历程可以分成三个阶段(基本和整个人工智能发展所经历的三次热潮相对应)。
1943年,心理学家 W.McCulloch 和数理逻辑学家 W.Pitts 通过模拟人类神经元细胞结构,建立了M-P神经元模型(McCulloch-Pitts neuron model)
)
[
7
]
)^{[7]}
)[7] ,这是最早的人工神经网络数学模型。
1957年,心理学家 F.Rosenblatt 提出了感知机模型(Perceptron)
[
11
−
12
]
{ }^{[11-12]}
[11−12] ,这是一种基于M-P神经元模型的单层神经网络,可以解决输人数据线性可分的问题。自感知机模型提出后,神经网络成为研究热点,但到 20 世纪 60 年代末时神经网络研究开始进入停滞状态。
1969 年,M.Minsky 和 S.Papert 研究指出当时的感知机无法解决非线性可分的问题
[
37
]
{ }^{[37]}
[37] ,使得神经网络研究一下子跌人谷底。
1986年,D.Rumelhart,G.Hinton 和 R.Williams 在 Nature 杂志上提出通过反向传播(back-propagation)算法来训练神经网络 [ 14 ] { }^{[14]} [14] 。
反向传播算法通过不断调整网络连接的权值来最小化实际输出向量和预期输出向量间的差值,改变了以往感知机收敛过程中内部隐藏单元不能表示任务域特征的局限性,提高了神经网络的学习表达能力以及神经网络的训练速度。到今天,反向传播算法依然是神经网络训练的基本算法。
1998年,Y.LeCun
[
38
]
{ }^{[38]}
[38]提出了用于手写数字识别的卷积神经网络 LeNet,其定义的卷积神经网络的基本框架和基本组件(卷积、激活、池化、全连接)并沿用至今,可谓是深度学习的序曲
2006 年,G.Hinton 基于受限玻尔兹曼机构建了深度置信网络(Deep Belief Network, DBN ),使用贪婪逐层预训练方法大幅提高了训练深层神经网络的效率
[
39
]
{ }^{[39]}
[39] 。同年,G.Hinton和 R.Salakhutdinov 在 Science 杂志上发表了一篇题为"Reducing the Dimensionality of Data with Neural Networks"的论文
[
15
]
{ }^{[15]}
[15] ,推动了深度学习的普及。
随着计算机性能的提升以及数据规模的增加,2012年,A.Krizhevsky 等人提出的深度学习网络 AlexNet
[
16
]
{ }^{[16]}
[16] 获得了 ImageNet 比赛的冠军,其 Top-5 错误率比第二名低
10.9
%
10.9 \%
10.9% ,引起了业界的轰动。
此后深度学习在学术界和工业界蓬勃发展,学术界提出了一系列更先进,更高准确度的深度学习算法,工业界则不断将最新的深度学习算法应用于实际生活的各种应用场景中。
在 2012年到 2017 年间,卷积神经网络和循环神经网络两大类深度神经网络发展迅速,人们根据具体任务特点设计了多种多样的专用卷积神经网络或循环神经网络。
卷积神经网络主要被应用于图像处理领域,如 VGG
[
40
]
{ }^{[40]}
[40] ,GoogLeNet
[
41
]
{ }^{[41]}
[41] ,ResNet
[
42
]
{ }^{[42]}
[42] 等。
循环神经网络则被广泛应用于自然语言处理和语音识别等领域,如
LSTM
[
43
]
\operatorname{LSTM}^{[43]}
LSTM[43] , GRU
[
44
]
{ }^{[44]}
[44] 等。
2017年后,以 Transformer为基础的大模型不断发展,并向着可以处理多种任务,更加通用的方向发展,在多种不同任务上展现出更通用的智能,例如 GPT-4
[
46
]
{ }^{[46]}
[46] 在自然语言处理,图像处理,编写代码等多种任务上展现出非常接近人类的水平。
生物神经元
生物学领域,一个生物神经元有多个树突(dendrite,接受传入信息);有一条轴突(axon),轴突尾端有许多轴突末梢(给其他多个神经元传递信息)。轴突末梢跟其它生物神经元的树突产生连接的位置叫做“突触”(synapse)。
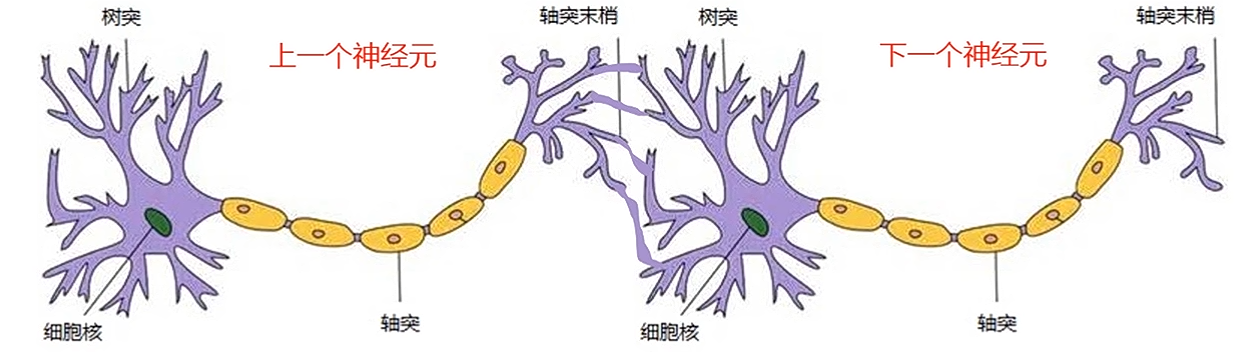
人工神经元
机器学习领域,人工神经元是一个包含输入,输出与计算功能的模型。不严格地说,其输入可类比为生物神经元的树突,其输出可类比为神经元的轴突,其计算可类比为细胞体。
[!NOTE]
早期的神经网络与生物学相关,发展到后期已经有很大区别了。陈老师的形象比喻:老鼠与米老鼠
单层感知机
首先介绍最简单的人工神经网络:只有一个神经元的单层神经网络,即感知机。它可以完成简单的线性分类任务。
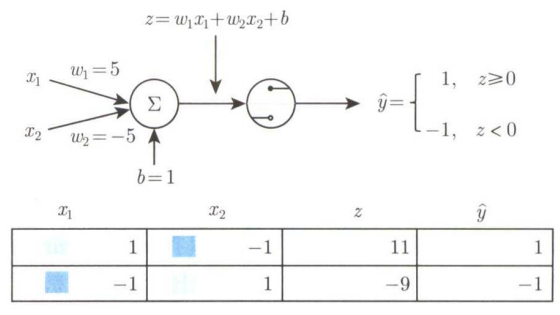
上图是一个两输入的感知机模型,其神经元的输人是
x
=
[
x
1
;
x
2
]
\boldsymbol{x}=\left[x_1 ; x_2\right]
x=[x1;x2] ,输出是
y
=
1
y=1
y=1 和
y
=
−
1
y=-1
y=−1 两类,
w
1
w_1
w1 和
w
2
w_2
w2 是突触的权重(也称为神经网络的参数),该感知机可以完成对输入样本的分类。该感知机模型的形式化表示为:
H
(
x
)
=
sign
(
w
1
x
1
+
w
2
x
2
+
b
)
=
sign
(
w
⊤
x
+
b
)
sign
(
x
)
=
{
+
1
x
⩾
0
−
1
x
<
0
\begin{gathered} H(\boldsymbol{x})=\operatorname{sign}\left(w_1 x_1+w_2 x_2+b\right)=\operatorname{sign}\left(\boldsymbol{w}^{\top} \boldsymbol{x}+b\right) \\ \operatorname{sign}(x)= \begin{cases}+1 & x \geqslant 0 \\ -1 & x<0\end{cases} \end{gathered}
H(x)=sign(w1x1+w2x2+b)=sign(w⊤x+b)sign(x)={+1−1x⩾0x<0
其中,
(
w
,
b
)
(\boldsymbol{w}, b)
(w,b) 是模型参数。由于其作用是对输入样本进行二分类,不难理解的是感知机模型训练的目标是找到一个超平面
S
(
w
⊤
x
+
b
=
0
)
S\left(\boldsymbol{w}^{\top} \boldsymbol{x}+b=0\right)
S(w⊤x+b=0) ,将线性可分的数据集
T
T
T中的所有样本点正确地分为两类。
超平面是 N N N 维线性空间中维度为 N − 1 N-1 N−1 的子空间。二维空间的超平面是一条直线,三维空间的超平面是一个二维平面,四维空间的超平面是一个三维体。
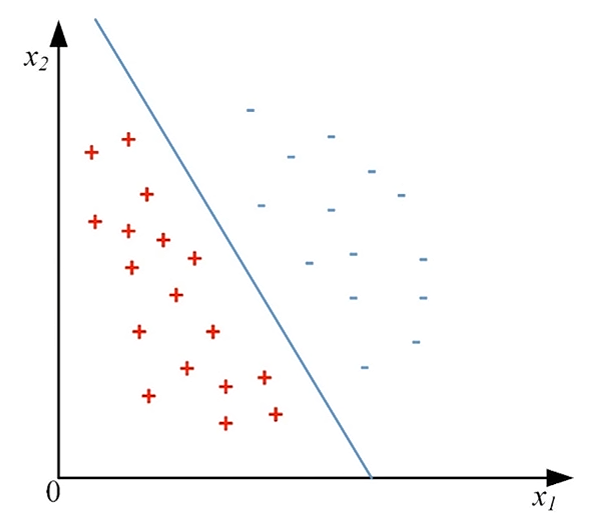
对于上图中的两类点,感知机模型训练时要在二维空间中找到一个超平面(即一条直线)将这两类点分开。为了找到超平面,需要找出模型参数
w
\boldsymbol{w}
w 和
b
b
b 。相对线性回归,感知机模型中增加了
sign
(
x
)
\operatorname{sign}(x)
sign(x) 计算,即激活函数,激活函数的输出也称为激活值。该计算增加了求解参数的复杂性。以后很少用
sign
(
x
)
\operatorname{sign}(x)
sign(x)这种线性激活函数了。
[!NOTE]
单层感知机本质上就是做二分类的超平面,输入二维则直线,输入三维则超平面,输入四维则三维体。
**核心目标:**找到一个最优的模型参数 ( w , b ) (\boldsymbol{w}, b) (w,b),将线性可分的数据集 T T T中的所有样本点正确地
分为两类
感知机模型训练首先要找到一个合适的损失函数,然后通过最小化损失函数来找到最优的超平面,即找到最优的超平面的参数。
考虑一个训练集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ D=\left\{\left(\boldsymbol{x}_1, y_1\right),\left(\boldsymbol{x}_2, y_2\right), \cdots\right. D={(x1,y1),(x2,y2),⋯ , ( x m , y m ) } \left.\left(\boldsymbol{x}_m, y_m\right)\right\} (xm,ym)} ,其中样本 x j ∈ R n \boldsymbol{x}_j \in \mathbf{R}^n xj∈Rn ,样本的标签 y j ∈ { + 1 , − 1 } y_j \in\{+1,-1\} yj∈{+1,−1} 。超平面 S S S 要将两类点区分开来,即使分不开,也要与分错的点比较接近。因此,损失函数定义为误分类的点到超平面 S ( w ⊤ x + b = 0 ) S\left(\boldsymbol{w}^{\top} \boldsymbol{x}+b=0\right) S(w⊤x+b=0) 的总距离。
[!NOTE]
与线性回归类似,我们需要找到一个合适的损失函数,那么如何找这个损失函数呢,使用点到超平面的距离,希望分错的点与超平面越近越好
样本空间中任意点
x
j
\boldsymbol{x}_j
xj 到超平面
S
S
S 的距离为
d
j
=
1
∥
w
∥
2
∣
w
⊤
x
j
+
b
∣
d_j=\frac{1}{\|\boldsymbol{w}\|_2}\left|\boldsymbol{w}^{\top} \boldsymbol{x}_j+b\right|
dj=∥w∥21
w⊤xj+b
其中, ∥ w ∥ 2 \|\boldsymbol{w}\|_2 ∥w∥2 是 w \boldsymbol{w} w 的 L 2 L^2 L2 范数,简记为 ∥ w ∥ \|\boldsymbol{w}\| ∥w∥ ,其计算为 ∥ w ∥ = ∑ i = 1 n w i 2 \|\boldsymbol{w}\|=\sqrt{\sum_{i=1}^n w_i^2} ∥w∥=∑i=1nwi2 。
[!NOTE]
对某一个点 x j \boldsymbol{x}_j xj其距离某个平面 w T x + b \boldsymbol{w}^{T}\boldsymbol{x}+b wTx+b的距离是有公式的,具体公式推导可参考高数相关知识。
如何构造损失函数呢?
假设超平面 S S S 可以将训练集 D D D 中的样本正确地分类:
当 y j = + 1 y_j=+1 yj=+1 时, w ⊤ x j + b ⩾ 0 \boldsymbol{w}^{\top} \boldsymbol{x}_j+b \geqslant 0 w⊤xj+b⩾0 ;
当 y j = − 1 y_j=-1 yj=−1 时, w ⊤ x j + b < 0 \boldsymbol{w}^{\top} \boldsymbol{x}_j+b<0 w⊤xj+b<0 。
对于误分类的点,预测出来的值可能在超平面的上方,但实际位置在下方,因此
y
j
y_j
yj 和预测出来的值的乘积应该是小于0的。即训练集
D
D
D 中的误分类点满足条件:
−
y
j
(
w
⊤
x
j
+
b
)
>
0
-y_j\left(\boldsymbol{w}^{\top} \boldsymbol{x}_j+b\right)>0
−yj(w⊤xj+b)>0
去掉误分类点
x
j
\boldsymbol{x}_j
xj 到超平面
S
S
S 的距离表达式中的绝对值符号,得到
d
j
=
−
1
∥
w
∥
y
j
(
w
⊤
x
j
+
b
)
d_j=-\frac{1}{\|\boldsymbol{w}\|} y_j\left(\boldsymbol{w}^{\top} \boldsymbol{x}_j+b\right)
dj=−∥w∥1yj(w⊤xj+b)
设误分类点的集合为
M
M
M ,所有误分类点到超平面的总距离为
d
=
−
1
∥
w
∥
∑
x
j
∈
M
y
j
(
w
⊤
x
j
+
b
)
d=-\frac{1}{\|\boldsymbol{w}\|} \sum_{\boldsymbol{x}_j \in M} y_j\left(\boldsymbol{w}^{\top} \boldsymbol{x}_j+b\right)
d=−∥w∥1xj∈M∑yj(w⊤xj+b)
由于
∥
w
∥
\|\boldsymbol{w}\|
∥w∥ 是一个常数,损失函数可定义为:
L
(
w
,
b
)
=
−
∑
x
j
∈
M
y
j
(
w
⊤
x
j
+
b
)
\mathcal{L}(\boldsymbol{w}, b)=-\sum_{\boldsymbol{x}_j \in M} y_j\left(\boldsymbol{w}^{\top} \boldsymbol{x}_j+b\right)
L(w,b)=−xj∈M∑yj(w⊤xj+b)
[!NOTE]
综上,上述损失函数是描述的误分类点到超平面的距离,足够理想的情况下是没有任何误分类点,此时 L \mathcal{L} L是等于0的,当 L \mathcal{L} L大于0时,说明一定存在误分类点,此时我们的损失函数的需求就是让误分类点距离超平面足够近
感知机模型训练的目标是最小化损失函数。当损失函数足够小时,所有误分类点要么没有,要么离超平面足够近。损失函数中的变量只有
w
\boldsymbol{w}
w 和
b
b
b ,类似于线性回归中的变量
w
1
w_1
w1和
w
2
w_2
w2 。可以用梯度下降法来最小化损失函数,损失函数
L
(
w
,
b
)
\mathcal{L}(\boldsymbol{w}, b)
L(w,b) 对
w
\boldsymbol{w}
w 和
b
b
b 分别求偏导可以得到
∇
w
L
(
w
,
b
)
=
−
∑
x
j
∈
M
y
j
x
j
∇
b
L
(
w
,
b
)
=
−
∑
x
j
∈
M
y
j
\begin{aligned} \nabla_{\boldsymbol{w}} \mathcal{L}(\boldsymbol{w}, b) & =-\sum_{\boldsymbol{x}_j \in M} y_j \boldsymbol{x}_j \\ \nabla_b \mathcal{L}(\boldsymbol{w}, b) & =-\sum_{\boldsymbol{x}_j \in M} y_j\end{aligned}
∇wL(w,b)∇bL(w,b)=−xj∈M∑yjxj=−xj∈M∑yj
如果用随机梯度下降法,可以随机选取误分类样本
(
x
j
,
y
j
)
\left(\boldsymbol{x}_j, y_j\right)
(xj,yj) ,以
η
\eta
η 为步长对
w
\boldsymbol{w}
w 和
b
b
b 进行更新
w
←
w
+
η
y
j
x
j
,
0
<
η
⩽
1
b
←
b
+
η
y
j
\begin{aligned} & \boldsymbol{w} \leftarrow \boldsymbol{w}+\eta y_j \boldsymbol{x}_j, \quad 0<\eta \leqslant 1 \\ & b \leftarrow b+\eta y_j \end{aligned}
w←w+ηyjxj,0<η⩽1b←b+ηyj
通过迭代可以使损失函数 L ( w , b ) \mathcal{L}(\boldsymbol{w}, b) L(w,b) 不断减小直至为 0 ,即使最终不为 0 ,也会逼近于 0 。通过上述过程可以把只包含参数 ( w , b ) (\boldsymbol{w}, b) (w,b) 的感知机模型训练出来。
多层感知机
20 世纪八九十年代,常用的是一种两层的神经网络,也称为多层感知机(Multi-Layer Perceptron,MLP)。下图的多层感知机由一组输入,一个隐层和一个输出层组成由于该多层感知机包含两层神经网络,其参数比上一节的感知机增加了很多。
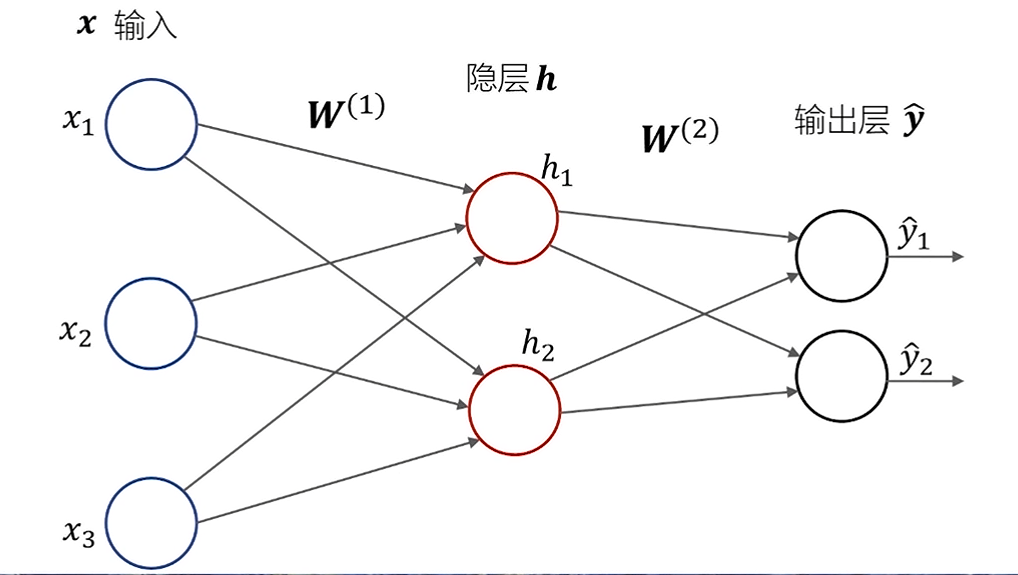 | 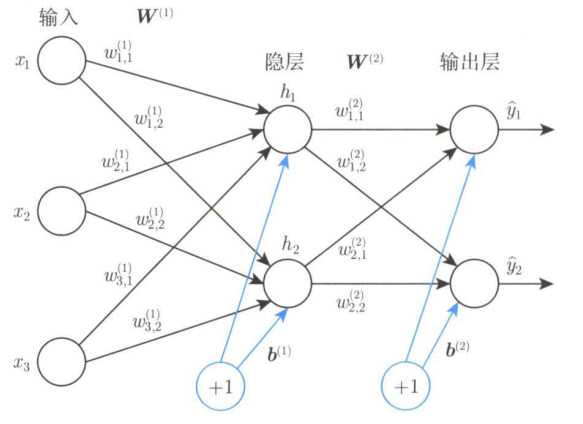 |
|---|
以上图中的多层感知机为例介绍其工作原理。该感知机的输入有 3 个神经元,用向量表示为 x = [ x 1 ; x 2 ; x 3 ] \boldsymbol{x}=\left[x_1 ; x_2 ; x_3\right] x=[x1;x2;x3] ;隐层有 2 个神经元,用向量表示为 h = [ h 1 ; h 2 ] \boldsymbol{h}=\left[h_1 ; h_2\right] h=[h1;h2] ;输出层有 2 个神经元,用向量表示为 y ^ = [ y ^ 1 ; y ^ 2 ] \hat{\boldsymbol{y}}=\left[\hat{y}_1 ; \hat{y}_2\right] y^=[y^1;y^2] 。
每个输入神经元到每个隐层神经元之间的连接对应一个权重,因此输入向量对应 6 个权重,用矩阵表示为
W
(
1
)
=
[
w
1
,
1
(
1
)
w
1
,
2
(
1
)
w
2
,
1
(
1
)
w
2
,
2
(
1
)
w
3
,
1
(
1
)
w
3
,
2
(
1
)
]
\boldsymbol{W}^{(1)}=\left[\begin{array}{ll} w_{1,1}^{(1)} & w_{1,2}^{(1)} \\ w_{2,1}^{(1)} & w_{2,2}^{(1)} \\ w_{3,1}^{(1)} & w_{3,2}^{(1)} \end{array}\right]
W(1)=
w1,1(1)w2,1(1)w3,1(1)w1,2(1)w2,2(1)w3,2(1)
从输入计算隐层的过程为:
1.权重矩阵
W
(
1
)
\boldsymbol{W}^{(1)}
W(1) 的转置乘以输入向量
x
\boldsymbol{x}
x 得到两个数(即隐层没有进行非线性激活之前的值)
2.再加上偏置( bias)向量
b
(
1
)
\boldsymbol{b}^{(1)}
b(1)
3.然后由非线性激活函数 G G G 进行计算,得到隐层的输出 h = G ( W ( 1 ) ⊤ x + b ( 1 ) ) \boldsymbol{h}=G\left(\boldsymbol{W}^{(1)}{ }^{\top} \boldsymbol{x}+\boldsymbol{b}^{(1)}\right) h=G(W(1)⊤x+b(1)) 。
从隐层计算输出层的过程与计算隐层的过程基本类似,权重矩阵为:
W
(
2
)
=
[
w
1
,
1
(
2
)
w
1
,
2
(
2
)
w
2
,
1
(
2
)
w
2
,
2
(
2
)
]
\boldsymbol{W}^{(2)}=\left[\begin{array}{ll} w_{1,1}^{(2)} & w_{1,2}^{(2)} \\ w_{2,1}^{(2)} & w_{2,2}^{(2)} \end{array}\right]
W(2)=[w1,1(2)w2,1(2)w1,2(2)w2,2(2)]
权重矩阵的转置乘以隐层的输出
h
\boldsymbol{h}
h ,再加上偏置
b
(
2
)
\boldsymbol{b}^{(2)}
b(2) ,然后通过非线性激活函数,得到输出:
y
^
=
G
(
W
(
2
)
⊤
h
+
b
(
2
)
)
\hat{\boldsymbol{y}}=G\left(\boldsymbol{W}^{(2)^{\top}} \boldsymbol{h}+\boldsymbol{b}^{(2)}\right)
y^=G(W(2)⊤h+b(2))
上图中多层感知机的模型参数包括 2个权重矩阵和 2个偏置向量:
权重矩阵
W
(
1
)
\boldsymbol{W}^{(1)}
W(1)有 6个变量,偏置
b
(
1
)
\boldsymbol{b}^{(1)}
b(1) 有2个变量,故第一层共有 8个变量;
权重矩阵
W
(
2
)
\boldsymbol{W}^{(2)}
W(2) 有 4个变量,偏置
b
(
2
)
\boldsymbol{b}^{(2)}
b(2) 有 2个变量,第二层共有 6个变量;
综上,该多层感知机总共只有14个变量需要训练,因此训练所需的样本量不太多,训练速度非常快。
[!IMPORTANT]
要时刻培养对参数量的敏感程度,待训练的参数量决定了神经网络的表达能力和对于计算资源的需求。
只有一个隐层的多层感知机是最经典的浅层神经网络。浅层神经网络的问题是结构太简单,对复杂函数的表示能力非常有限。例如,用浅层神经网络去识别上千类物体是不现实的。
但是, 20 世纪八九十年代的研究者都在做浅层神经网络,而不做深层神经网络。其主要原因包括两方面。一方面,K.Hornik 证明了理论上只有一个隐层的浅层神经网络足以拟合出任意的函数 [ 33 ] { }^{[33]} [33] 。这是一个很强的论断,但在实践中有一定的误导性。因为,只有一个隐层的神经网络拟合出的任意函数可能会有很大的误差,且每一层需要的神经元的数量可能非常多。另一方面,当时没有足够多的数据和足够强的计算能力来训练深层神经网络。
现在常用的深度学习可能是几十层,几百层的神经网络,里面的参数数量可能有几十亿个,需要大量的样本和强大的机器来训练。而 20 世纪八九十年代的计算机的算力是远远达不到需求的,当时一台服务器的性能可能远不如现在的一部手机。受限于算力, 20 世纪八九十年代的研究者很难推动深层神经网络的发展。
[!NOTE]
受限于Hornik的强理论论断与实践误差以及当时时代的计算机算力的限制,是否那个时代留下了一些糟粕?但是否会有一些浅层神经网络相关研究留下的遗嘱?无论如何,历史给人启示:用发展的眼光看问题。
深度学习
相对于浅层神经网络,深度学习 (深层神经网络)的隐层可以超过 1层。
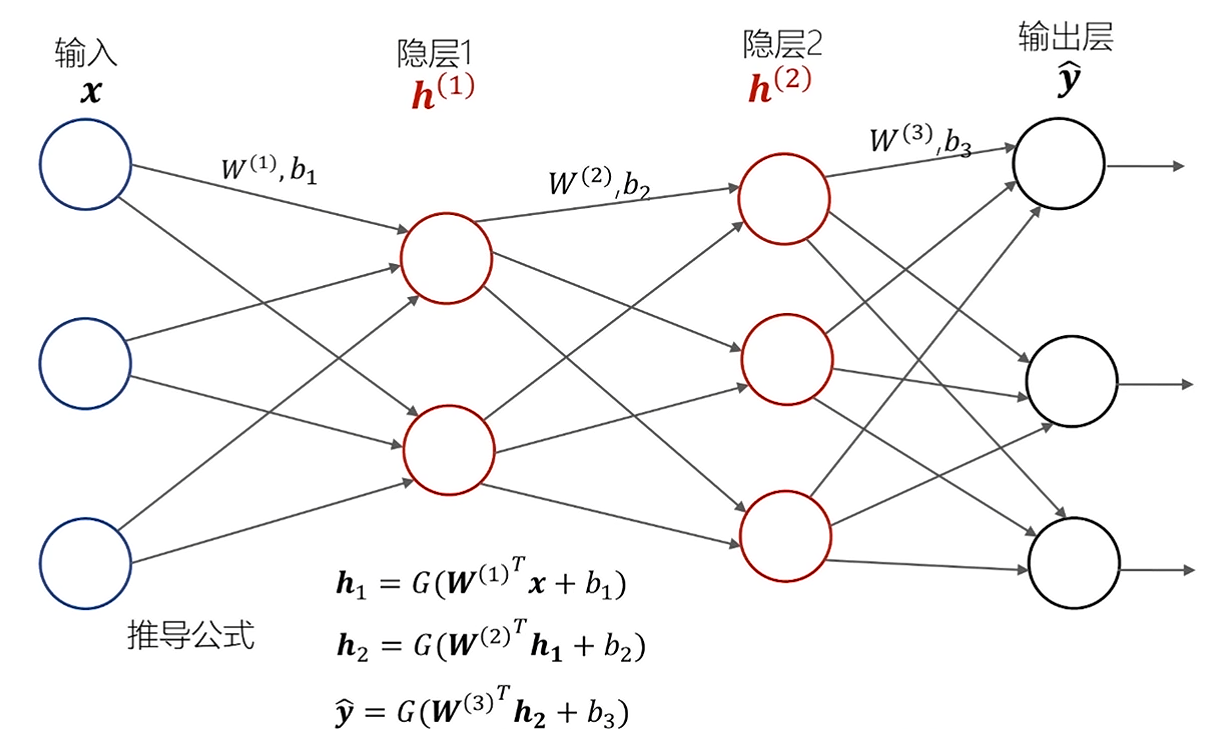
上图的多层神经网络有 2个隐层。该神经网络的计算包括从输入算出第 1个隐层,从第1个隐层算出第 2个隐层,从第 2个隐层算出输出层。
随着层数的增加,神经网络的参数也显著增多该三层神经网络共有 29个参数,包括第一层的6个权重和2个偏置,第二层的 6个权重和3个偏置,第三层的9个权重和3个偏置。
早期深度学习借鉴了灵长类大脑皮层的 6层结构。为了提高图像识别,语音识别等应用的准确率,深度学习不再拘泥于生物神经网络的结构,现在的深层神经网络已有上百层甚至上千层,与生物神经网络有显著的差异。随着神经网络层数的增多,神经网络参数的数量也大幅增长, 2012 年的 AlexNet中有 6000万个参数,现在的大模型中参数数量可以达到上千亿个甚至万亿个 。
深度学习的工作原理是,通过对信息的多层抽取和加工来完成复杂的功能。下图展示了深度学习在不同层上抽取出的特征。
 |  |
|---|
在第一层,深度学习通过卷积提取出局部比较简单的特征,如对角线;在第二层,可以提取到一些稍大范围稍复杂的特征,如条纹状的结构;在第三层,可以提取到更大范围更复杂的特征,如蜂窝网格的结构;最后,通过逐层细化的抽取和加工,可以完成很多复杂的功能。
应该说,从浅层神经网络向深层神经网络发展,并不是很难想象的事情。但是,深度学习(深层神经网络)的真正兴起到 2006 年才开始。
除了 G.Hinton,Y.LeCun 和 Y. Bengio 等人的推动外,深度学习之所以能成熟壮大,得益于 ABC 三方面的影响: A 是 Algorithm(算法),B 是 Big data(大数据),C 是 Computing(算力):
Algorithm:- 算法日新月异,优化算法层出不穷,深层神经网络训练算法日趋成熟,其识别准确率越来越高
- 学习算法→BP算法→Pre-training,Dropout等算法
Big data:- 数据量不断增大,互联网企业有足够多的大数据来做深层神经网络的训练
- 10→10k→100M
Computing:- 处理器计算能力的不断提升,现在的一个深度学习处理器芯片的计算能力比当初100个CPU的还要强。
- 晶体管→CPU→集群/GPU→智能处理器


















 7572
7572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









