【Python】科研代码学习:六 ModelOutput,SpecificModel
HF官网API:ModelOutput 所有模型的输出都是 ModelOutput 的子类的实例 ModelOutput与其子类,我们就可以获得许多有用的输出参数先来看如何获取模型的输出的一个例子:tokenizer, model,获取输入和标签后,model(xxx) 的返回结果就是 outputs 了 from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer. from_pretrained( "google-bert/bert-base-uncased" )
model = BertForSequenceClassification. from_pretrained( "google-bert/bert-base-uncased" )
inputs = tokenizer( "Hello, my dog is cute" , return_tensors= "pt" )
labels = torch. tensor( [ 1 ] ) . unsqueeze( 0 )
outputs = model( ** inputs, labels= labels)
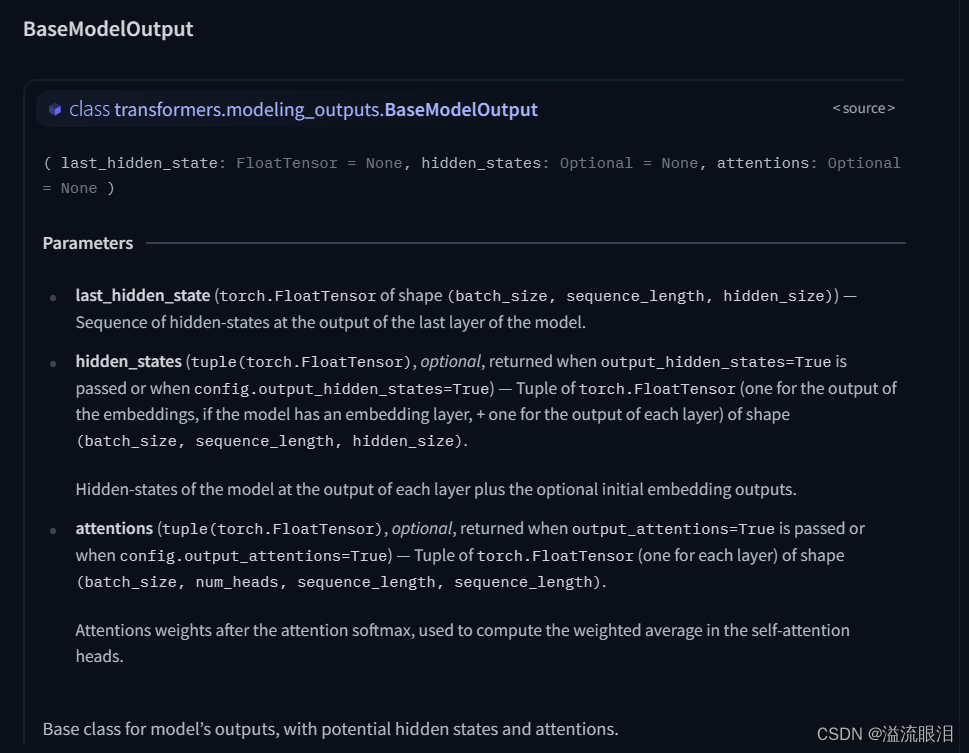
看一下源码:transformers.utils.ModelOutputOrderedDict,且重载了 __getitem__,可以通过字符串 / 下标索引to_tuple() 获取转成tuple类型※ 另外需要注意的是,传参output_hidden_states=True 以及 output_attentions=True 等,我们才能从 outputs 中获取到更多的参数信息 上面的 ModelOutput 只是定义了基础的格式和转换,接下来这个BaseModelOutput 则是继承自上面的类,并且可以获得更多参数信息 可以看到,它存储了如下参数:last_hidden_state:最终隐藏层状态的张量值hidden_states:每一层的状态的张量值attentions:每一层的注意力的张量值
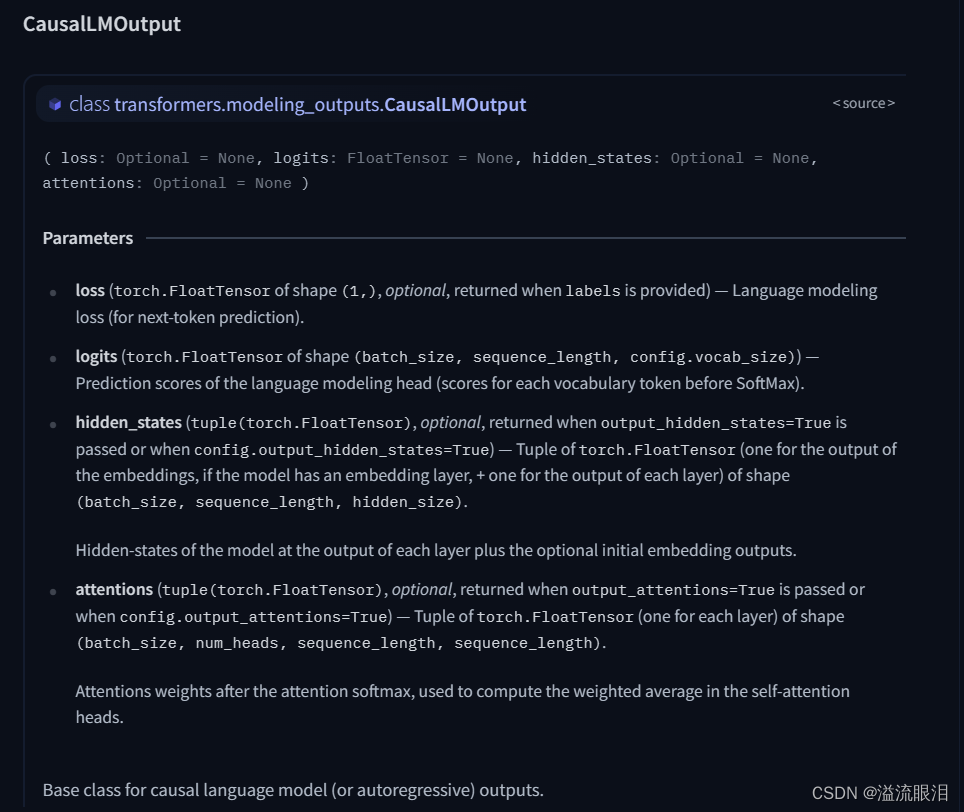
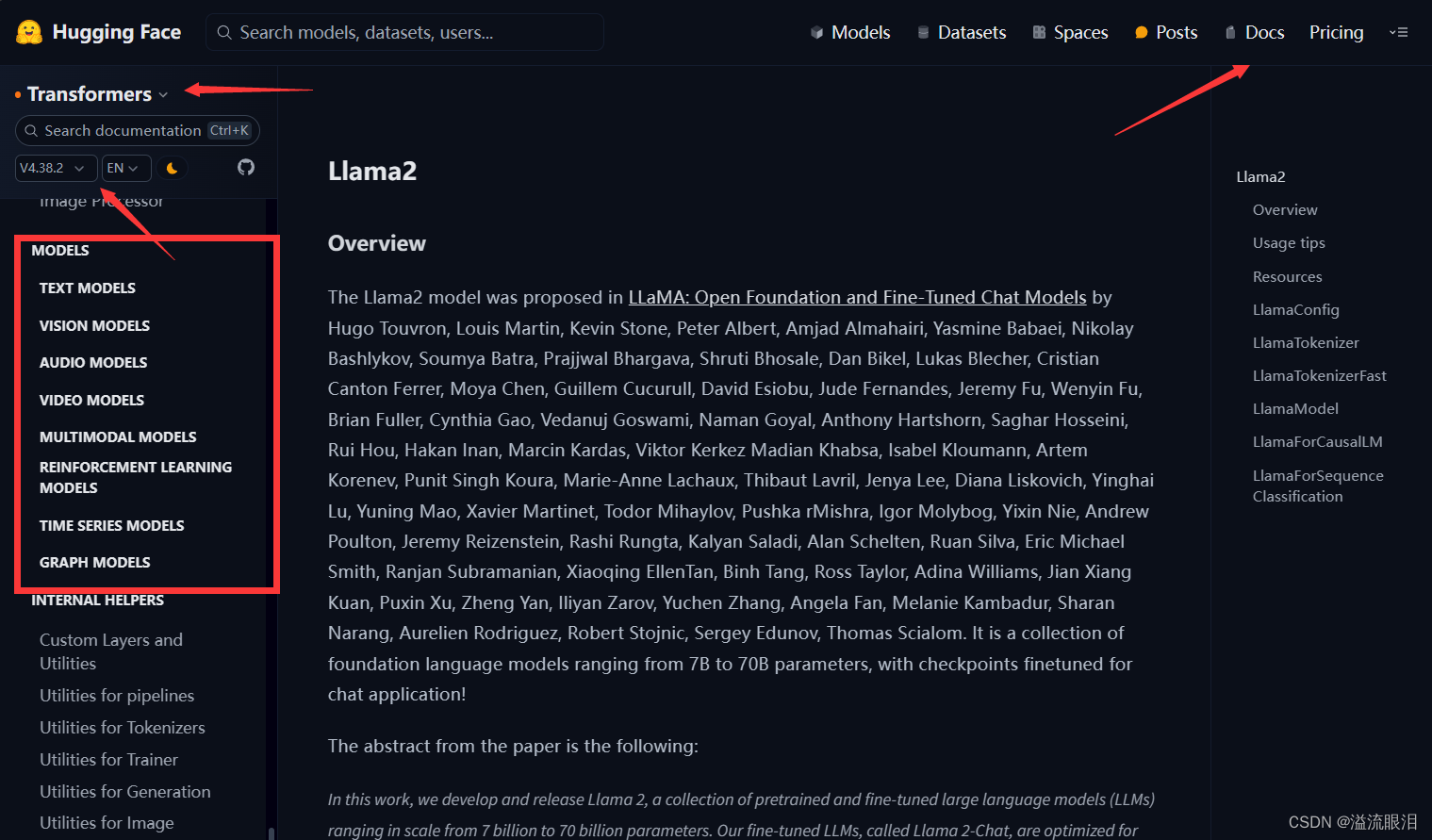
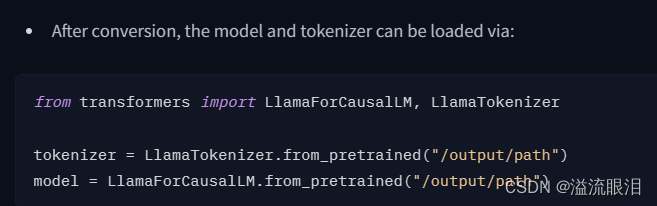
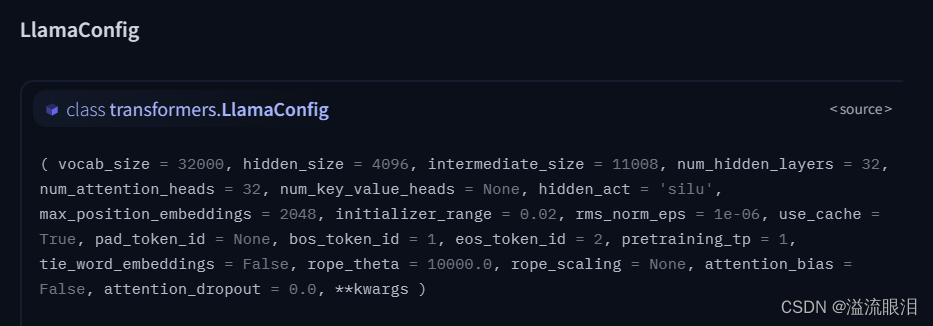
这个比较常用,是专门对因果LM输出用的loss 损失logits:LM头的预测分数,在CausalLM中即为在词汇表vocab中,下一个token的预测分数,并且未经过最后softmax归一之前的分数。 其他还有很多,主要是关注pt 还是 tf 还是 flaxPretrainedModel 比如 BaseModelOutputWithCrossAttentions 就用了交叉注意力的 PretrainedModelSeq2SeqModelOutput 给 s2s 模型的MaskedLMOutput 给 maskedLM的NextSentencePredictorOutput 给 NSP 任务的MultipleChoiceModelOutput 给多选任务的…你会发现,具体是哪一类,取决于你当时是用哪个 PretrainedModel 之前讲过 PretrainedModel 是预训练模型的基类AutoModel 可以自动根据输入的参数,选择最合适的模型AutoModelForCausalLM,可以自动根据输入的参数,选择最合适的因果LM模型AutoModel 呀,他们的导入头文件是从哪里来的呢?HF官网的Doc的最左下角找的:Docs,找到 Transformers 库的 API,然后选择合适的版本号,用英文,左侧滚到底,就可以找到了 我这里是NLP任务,所以选择大类 TEXT MODELSALBERT, BART, BERT, BLOOM, GPT, GPT2, LLaMA, Llama2, REALM, RoBERTa, T5 ……Llama2 为例子吧 步骤一:查看基本信息 步骤二:查看怎么导入 model 和 tokenizerLlamaForCausalLM, LlamaTokenizer 了 步骤三:查看对应的 config, tokenizer, model 的改动PretrainedConfig, PretrainedTokenizer, PretrainedModel 嘛,它肯定自己加了些东西LlamaConfig 中,有如下参数,比较多,还是建议看文档,自己背出来的话也太大佬了 它这里 model 有三个,主要还是看你需要用它来做什么任务,就选择哪个即可。

























 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









