






Python的TextBlob包是执行许多自然语言处理(NLP)任务的便捷方法。例如:

这告诉我们,英语短语“not a very great calculation”的极性约为-0.3.表示它略为负,主观性约为0.6.表示它是相当主观的。
但是这些数字从何而来?
让我们通过查找源代码来查找。(sloria/TextBlob)
深入研究之后,可以发现_text.py中定义了主要的默认情感计算,该功劳归功于模式库。

它引用的词典在en-sentiment.xml中,这是一个XML文档,其中包括“ great”一词的以下四个条目。
除了上面的评论中提到的极性,主观性和强度之外(polarity, subjectivity, and intensity),还有“confidence”,以“great”为例,它是所有相同的语言部分(JJ表示形容词),:

也就是说,textblob内部通过一些字典或者说模板的方式对great进行了如上的定义,应该和nltk类似通过人工等方式来计算得到的一些评价结果;
当计算单个词的时候,textblob进行了简单平均:

可以看到,计算结果就是简单平均。
如果加入否定词,比如not:

则极性默认是乘以-0.5
TextBlob还可以处理修饰词!这是词典中“very”的摘要记录:
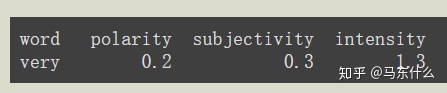
则

这里,当very作为修饰词的时候,它的polarity和subjectivity是忽略的,而是直接使用intensity乘以great的polarity和subjectivity,因为极性最大为1.所以这里舍入了。
再看一个例子:

这里的计算过程是这样的:

TextBlob将忽略其情感语录短语中的一个字母的单词,这意味着类似的事情将以相同的方式起作用:

而且TextBlob会忽略不知道的单词:

TextBlob一直在寻找可以为其指定极性和主观性的单词和短语,并将它们平均在一起,这就是对长文本进行处理的时候的原理,就是简单平均,疯狂的平均。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









