









零 阅读基础与可能帮助文档
一 论文摘要与加速背景详解
论文链接:Eagle: Speculative sampling requires rethinking feature uncertainty
自回归解码是指模型逐个生成词元(token)的过程,每个词元的生成都依赖于之前生成的所有词元。在KV Cache推理加速技术出现前,每个词元生成的前向传播过程forward都需要两个关键的运算:自注意力计算(Multi-Head Self-Attention)和前馈网络计算(Feed-Forward Neural Network)。每次forward运算需要词元序列input_ids先进行词元嵌入转化为词向量序列input_hiddens(input embeddings),其中input_ids的形状为(batch_size, seq_len),input_hiddens的形状为(batch_size, seq_len, hidden_size)。对于每个batch,输入的词向量序列构成一个矩阵,形状为(seq_len, hidden_size),比如上下文长度为1024,隐藏向量维度为4096,那么输入的词向量形状即为(1024, 4096)。这样的词向量序列进行自注意力计算和前馈网络计算,实质上就是进行矩阵-矩阵乘法,即一个矩阵与一个矩阵的乘法,算法复杂度为o(n^2),其中n=seq_len。
仔细分析会发现,当n=seq_len=1024计算完毕后,对于n=1025的情况,很多计算结果其实可以从n=1024的计算过程中得到,即n=1025的自注意力计算和前馈网络计算存在冗余过程,由此人们便发明了KV Cache推理加速技术,关于该技术参考这篇文章:大型模型KV Cache机制详解
当使用KV Cache加速技术后,解码阶段的每次矩阵-矩阵乘法运算被简化矩阵-向量乘法,计算复杂度也由o(n^2)降低为o(n)。但是这个改进也带来了另一个问题:矩阵-向量乘法相对矩阵-矩阵乘法,计算访存比更低,传输的数据量只降为原来一半,但是计算的数据量却急剧降为几千分之一,这导致整个运算过程的性能瓶颈卡在数据传输上面。因此,自回归解码这种串行的生成方式是 LLM 推理速度慢的主要瓶颈,下图可以很好地体现这种问题:

针对 Decoding 阶段计算强度比较低的情况,有两种优化的思路:
-
在不同请求间 Batching 的方式(Continuous Batching),可以增大 Decoding 阶段的 Batch Size,进而更充分发挥 GPU 算力,但是其无法降低单个请求的 Latency,而且如果用户请求比较少,比如只有单一用户,那么永远无法实现 Batching。
-
在单一请求内一次验证多个 Decoding Step(Speculative Decoding),虽然一次 Decoding Step 计算量线性增加,但由于是访存瓶颈,因此计算时间不会明显增加,如果 Decoding Step 数量减少的比例更多,那么就很有可能降低整个请求的时延。
投机采样推理加速就是针对方法2进行的,通俗易懂理解就是尽量一次生成多个token而不是串行一个token一个token地生成,以此进行并行计算加速推理过程。
投机采样就像是玩填字游戏时,你先请一个助手(小模型)快速地、但不一定准确地填一些词,然后你(大模型)再仔细检查这些词是否合适。如果大部分词都正确,你就直接采用,大大节省了自己思考的时间;如果错误较多,你就只保留正确的,然后自己重新填空。这样一来,你就不需要从头到尾自己思考每个词,而是利用助手提供的“草稿”,加速了填字过程,最终达到更快的推理速度。具体来说,小模型先生成一小段文本,大模型评估这段文本的概率,如果概率足够高,就直接接受这段文本,否则就用大模型自己的输出来替换小模型的输出。

如上图所示,从模型开始生成的标志[START]后,绿色部分表示草稿模型被原始模型接受的文本,而红色部分表示草稿模型被原始模型拒绝的文本,蓝色部分表示文本被拒绝后原始模型自己重新生成的正确文本。由于一次性可能接受多个token,所以相对原始的串行一个一个生成的过程会快很多。
投机采样作为加速大型语言模型推理的技术,其发展历程可以概括为从线性到树形的探索。最初的投机采样采用链式结构,即小模型逐个token生成候选序列,大模型逐个验证。这种方法简单直接,但效率受限于小模型生成的序列质量。为了提高效率,研究者们开始探索更复杂的树形结构。树形投机采样允许小模型并行生成多个候选token,形成一棵树,然后大模型对整棵树进行评估,并选择最佳路径。这种方法能够探索更多的可能性,从而提高采样的准确性和效率。过多的投机采样综述可以参考这篇文章:万字综述 10+ 种 LLM 投机采样推理加速方案
前面都是基础知识,下面开始介绍EAGLE投机采样方法。
相对之前的投机采样方法(比如SpecInfer,Medusa等),EAGLE作者观察到如下两个关键idea:
-
在特征级别进行自回归(即预测倒数第二层的隐藏状态)比直接预测词元(token)更简单。这里的特征指的是模型中神经网络的倒数第二层输出的隐藏状态,它比词元更抽象,包含更丰富的语义信息。
-
虽然在特征级别进行自回归更简单,但其固有不确定性会限制性能。因为特征层更加抽象,预测难度更大,更容易出现偏差。这种不确定性限制了其速度优势,降低了加速效果。
第一个点意思大概就是相对直接操作最后一层输出的token,操作倒数第二层的特征表示可以得到更丰富的信息(因为最后一层token输出是基于概率选择可能性更大的,那么被舍弃的可能性就丢失了一部分信息);第二个点的意思大概是利用一个特征表示存在信息不确定性,因为还没有确定输出那个token,文本往各个分支方向都有可能发展,但是利用相邻两个step的特征表示可以凑在一起可以减少不确定性(通俗理解就是相邻step确定了下一步的分支选择在那个方向了),包含更多关于推理的确定性信息。
基于这两个关键的观察,作者提出了 EAGLE,一个简单但高效的投机采样框架。EAGLE 的目标是解决特征级别自回归中存在的不确定性,从而提升性能。
作者对 EAGLE 进行了全面的评估,包括 Vicuna 和 LLaMA2-Chat 系列的所有模型、MoE 模型 Mixtral 8x7B Instruct,以及对话、代码生成、数学推理和指令遵循等任务。对于 LLaMA2-Chat 70B 模型,EAGLE 实现了 2.7 倍至 3.5 倍的延迟速度提升比率,吞吐量翻倍,同时保持了生成文本的分布。
二 论文引言与基本介绍详解
作者首先介绍了经典的草稿模型方案:SpecInfer 投机采样利用多个小型模型(SSM)快速生成“草稿”(Draft),然后由大型模型(LLM)验证并选择,从而加速文本生成。详细介绍案例可以看这篇文章:推理加速:投机采样经典方法
然后也指出关键问题:首先是小模型不好找(总不能乱搞一个模型就认为是目标模型的小模型,做事还是得有依据),LLaMA2-7B可以作为LLaMA2-70B的小模型,但是LLaMA2-7B就不好找到对应的小模型了;其次是小模型的开销问题也严重,训练成本和推理成本都是问题(作者用自己方法做了一个训练对比:TinyLLaMA is trained on 3,000B tokens,
whereas EAGLE is trained on 2-4B tokens.)
投机采样加速推理的关键在于两个点:第一个点是草稿阶段的计算成本,第二个点是目标模型对草稿token的接受率。
之前业界大量的方法都针对计算成本去优化了,比如Lookahead和Medusa,这两个虽然明显降低了草稿阶段的计算成本,但是目标模型对草稿token的接受率较低,所以整体推理加速效果的改善并不是特别显著。因此作者提出了EAGLE的投机采样方法,既能降低计算成本,又能提高接受率。
然后作者更深入强调摘要里面的两个idea:
- 在特征级别进行自回归(即预测倒数第二层的隐藏状态)比直接预测词元更简单。
- 虽然在特征级别进行自回归更简单,但其固有不确定性会限制整体推理加速性能。
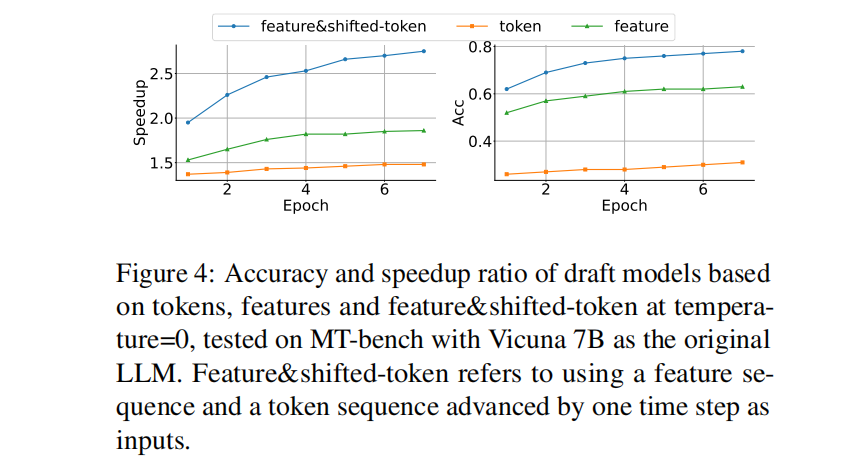
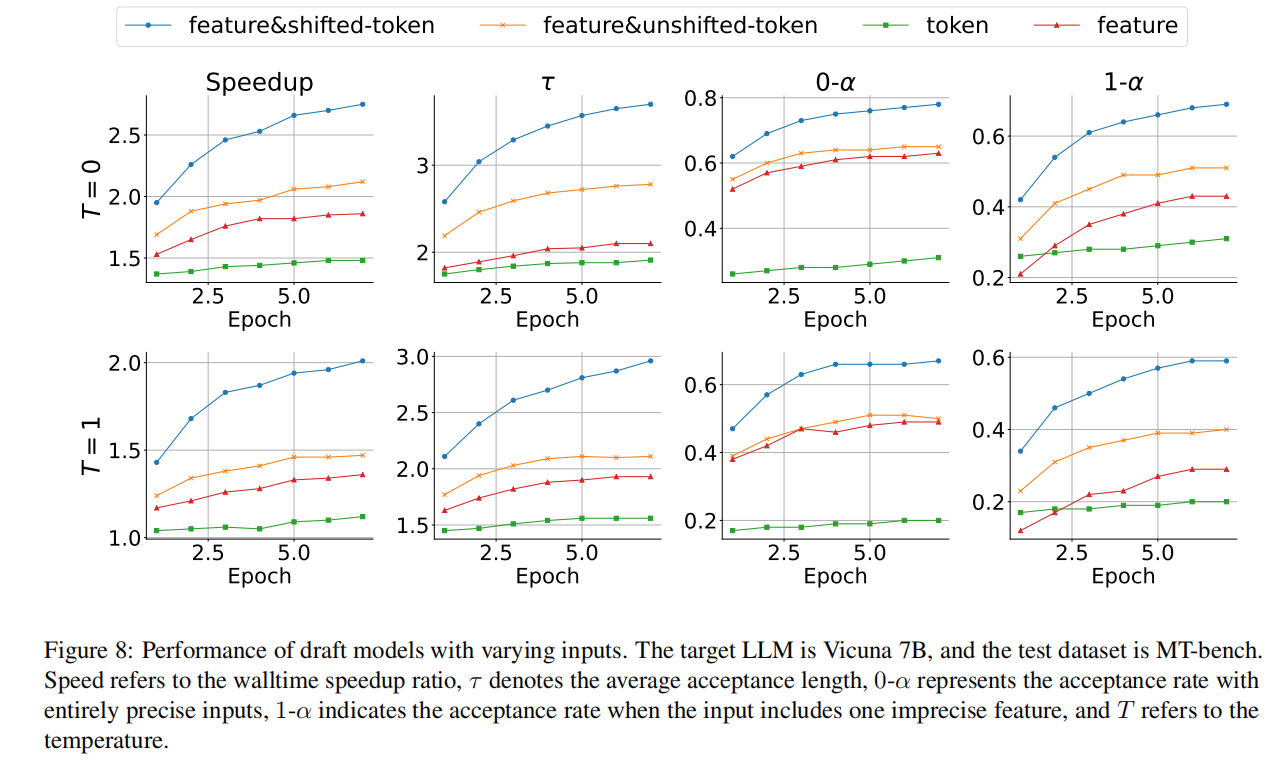
第一个观点可以从下图(图片均来源原始论文)得到印证:token线条是传统方法,feature是特征方法,Feature&shifted-token线条是作者主要采用的方法。
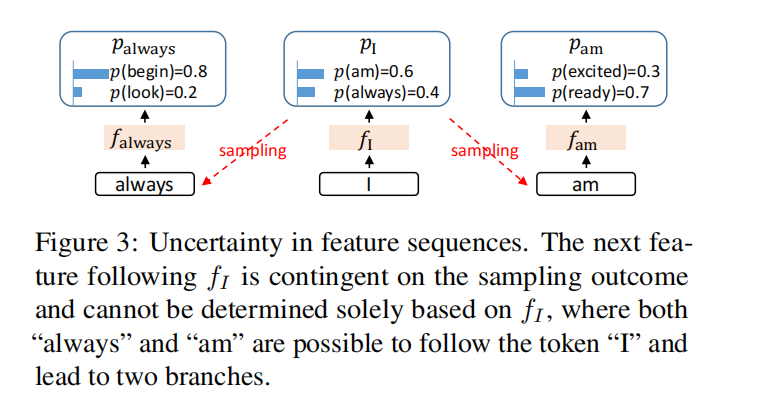
第二个观点大概说固有不确定是指容易产生分支限制加速性能,论文中一个图给出了说明:
最后,作者还介绍了EAGLE方法的其他优势:
- Generality:EAGLE可以部署在几乎所有的大模型上面,而不必担忧找不到对应草稿模型造成的应用困境。
- Reliability:EAGLE的应用不需要原始大模型进行任何额外的微调,保证了方法应用前后模型分布一致。
最后介绍一下token接受的机制:
如何评价一个token生成的不好?如果q(x) > p(x)(p,q表示在大小模型采样概率,也就是logits归一化后的概率分布)则以一定1-p(x)/q(x)为概率拒绝这个token的生成;如果q(x) <= p(x),接受该token。在q(x) > p(x)情形下,需要从一个新的概率分布p’(x) = norm(max(0, p(x) − q(x)))中重新采样一个token。
一个直观的解释,p(x’) > q(x’)说明大模型在token x’上概率大于小模型,则大模型对生成token x’更有把握,说明小模型生成的问题不大可以保留x’。如果p(x’) ≤ q(x’)则小模型更有把握,大模型就以1-p(x)/q(x)为概率概率拒绝,并重新采样。因为接收的概率更偏向q(x)大的位置,重新采样的概率应该更偏向p(x)大的位置,所以是norm ( max(0, p(x)-q(x) ),其中norm表示概率归一化,毕竟使用max函数后概率之和不一定为1。
EAGLE论文附录A1.1中严格证明了对于任意分布p(x)和q(x),通过上述方法从p(x)和q(x)进行投机采样所得到的标记的分布与仅从p(x)进行采样所得到的标记的分布是相同的,保证了生成token序列的质量。
三 论文方法与原理细节详解
和其他投机采样方法一样,EAGLE也是分为草稿阶段和验证阶段两个部分,在原理介绍这里就分为三个部分:草稿阶段介绍,草稿训练介绍,验证阶段介绍。
3.1 草稿阶段介绍
目标模型是原始的大模型,草稿模型是对应的小模型。
其中的 草稿模型( Draft model ) 的 Embedding 层、LM Head 以及 Sampling 都来自原始的 LLM,而 Auto-regression Head 包含一个 全连接层( FC Layer )和若干Decoder layer。简单说就是利用两个词的特征信息预测下一个词的特征,(bs, seq_len, 2 × hidden_dim) --> (bs, seq_len, hidden_dim)。
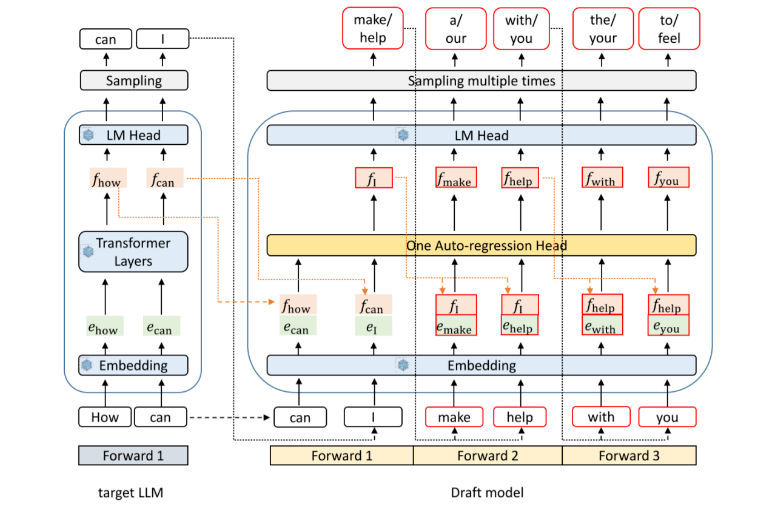
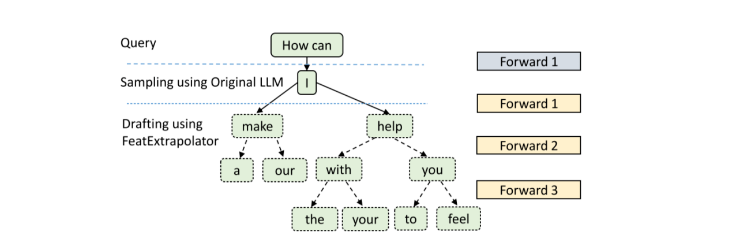
具体过程描述就是:

3.2 草稿训练介绍
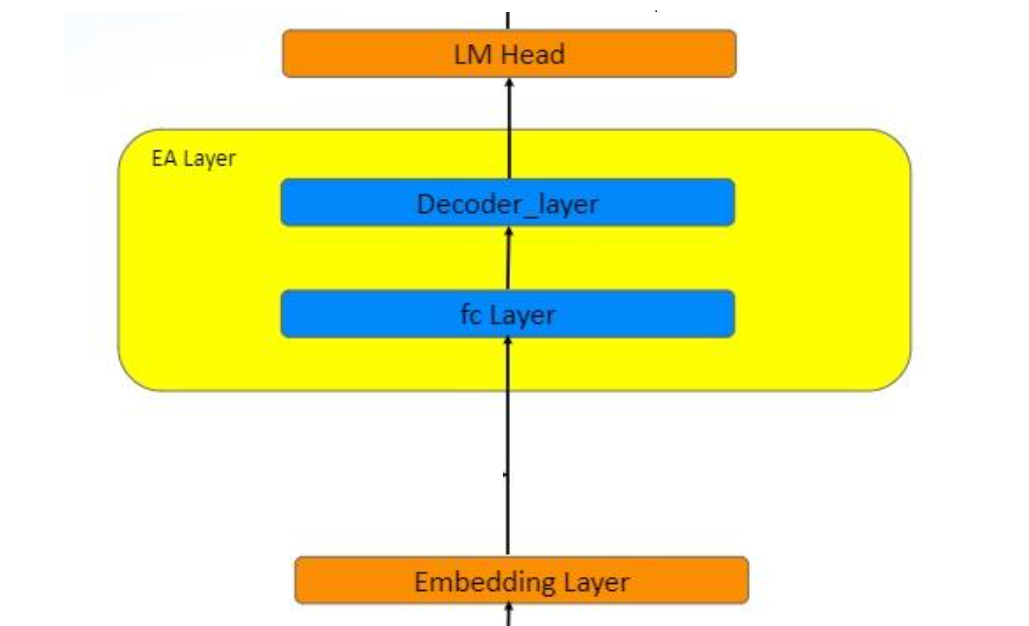
前向传播既然知道了,那么只需要确定损失函数就基本上可以大概进行训练了。损失函数EAGLE分为两部分,一部分是中间特征向量计算而来的损失函数
L
r
e
g
L_{reg}
Lreg,另一部分是草稿模型与目标模型之间分布差异计算而来的损失函数
L
c
l
s
L_{cls}
Lcls,由于计算的量级存在差异,所以需要一个权重
w
c
l
s
w_{cls}
wcls对后一个损失值进行放缩,论文里面该值取
w
c
l
s
=
0.1
w_{cls}=0.1
wcls=0.1:
L
=
L
r
e
g
+
w
c
l
s
L
c
l
s
L = L_{reg} + w_{cls}L_{cls}
L=Lreg+wclsLcls
其中各部分损失函数计算细节如下:
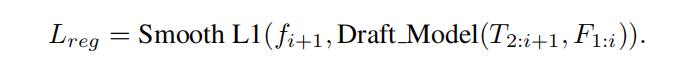
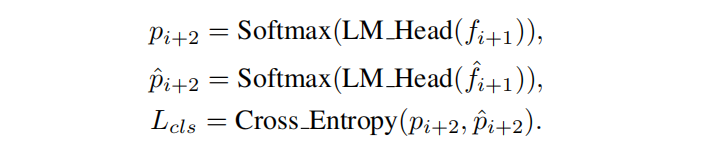
EAGLE的自回归头EA Layer理想情况下是通过目标LLM自回归生成的文本进行训练的,然而这种方法成本高昂(主要是训练原始模型的数据量太多,而且每次都需要原始模型计算中间特征表示)。幸运的是,EAGLE对训练数据的敏感性较低(后面的消融实验证明,目标LLM自回归生成的对加速比仅有0.1的提升),因此没有使用目标LLM生成的文本,而是使用了一个固定的训练数据集,大大减少了开销。在草稿阶段,EAGLE自回归地处理特征。特征中的不准确可能会导致错误累积。为了解决这个问题,在训练期间通过向目标LLM的特征添加从均匀分布U(−0.1, 0.1)中采样的随机噪声来进行数据增强。
3.3 验证阶段介绍
与SpecInfer里面的树形验证方法一致
四 论文实验与效果对比详解
实验模型:Vicuna (7B, 13B, 33B);LLaMA2-chat (7B, 13B, 70B);Mixtral 8x7B Instruct
实验任务:多轮对话;代码生成;数学推理;指令遵循
实验数据:MT-bench;HumanEval;GSM8K;Alpaca
主要讨论 batch size = 1 的情况,且以推理延迟为衡量而非吞吐量,对于 batch size = n 在实验最后一节提及。
加速指标:实际加速比;平均接受长度;接受率
训练参数:
4.1 加速效果
在普通模型上效果特别好:
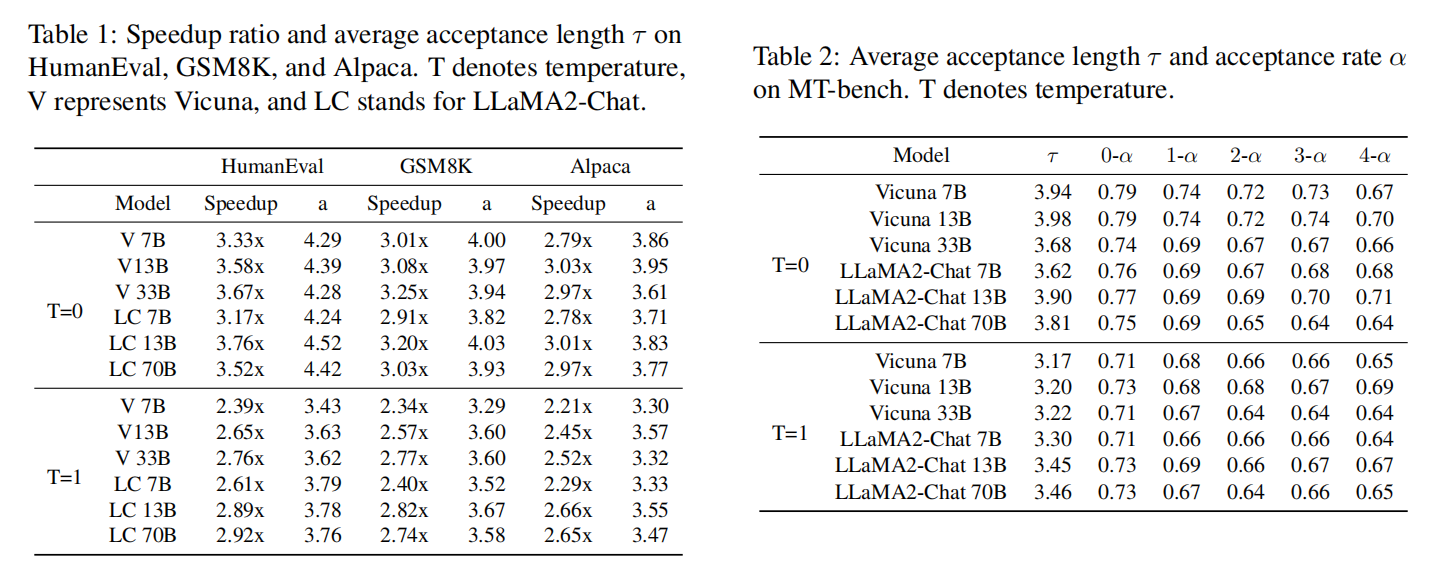
但在MoE模型上效果差不少,因为计算过程可能需要所有专家参与计算,但原始模型只需要8个专家中的2个参与计算,所以加速效果大打折扣:
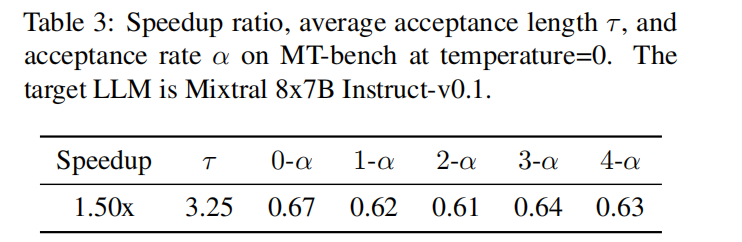
4.2 量化加速
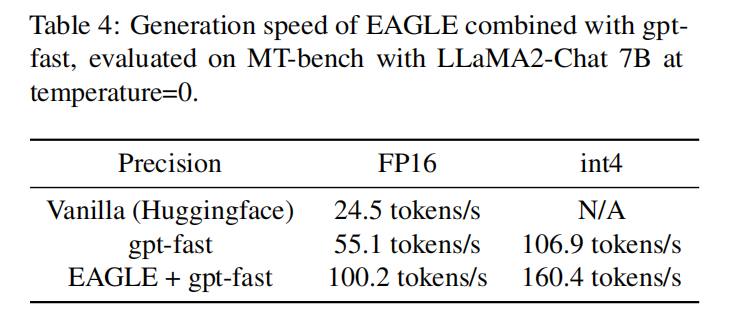
部署上,作者使用的 GPT-Fast 作为推理框架,同时这里也结合了不少量化方面的。GPT-Fast 框架上支持较成熟的编译优化和量化功能来加速生成过程,并且在 GPT-Fast 的基础上还可以通过 eagle 再加速两倍左右,同时量化工作可以再进一步加速 60% 。
4.3 消融实验
相对链式结构草稿与验证,树形结构草稿与验证加速效果更好:
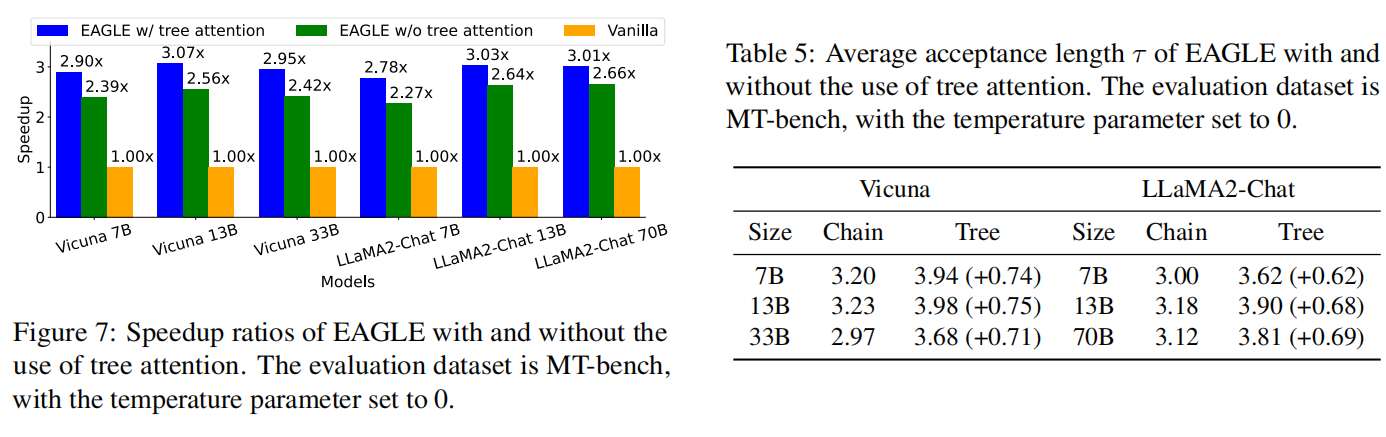
后面又做了一系列实验:
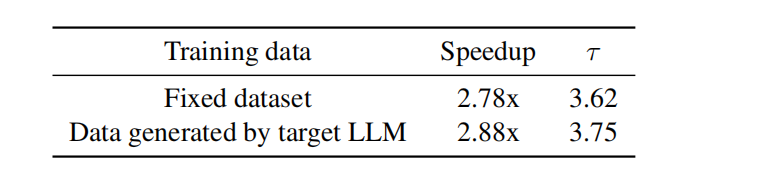
Fixed dataset:问题和答案均来自于ShareGPT dataset
Data generated by target LLM:问题来自ShareGPT dataset,但答案使用原始模型生成
通过下面实验结果证实无需原始模型去生成答案(这样也很慢):
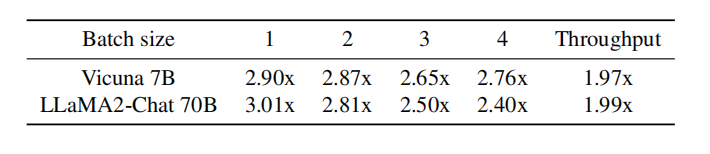
4.4 Batch size and throughput
batch size增大的时候,相对batch size = 1 的情况,整体加速比呈现下降趋势:


















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











