







 超级会员免费看
超级会员免费看
一、KV-cache
在LLM的推理过程中,KVCache已经属于必备的技术了。然而,网上现有的解读文章并不够清晰。看了一些文章之后,我决定还是自己写一篇新的,以飨读者。
二、GQA(Grouped-query attention)
在LLaMa2一文中,其主要区别于LLaMa的改动为:使用GQA和4k文本长度,那什么是GQA?
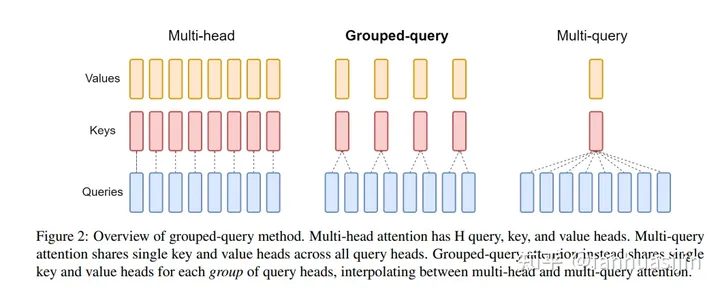
GQA(Grouped-query attention) - 知乎
三、投机采样(Speculative Decoding)
用小模型推理,用大模型做验证
投机采样(Speculative Decoding)是Google[1]和DeepMind[2]在2022年同时发现的大模型推理加速方法。它可以在不损失生成效果前提下,获得3x以上的加速比。GPT-4泄密报告也提到OpenAI线上模型推理使用了它。
对如此妙到毫巅的方法,介绍它中文资料却很少

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









