







模型预测控制(Model Predictive Control, MPC)
模型预测控制(Model predicative control,MPC)是由 Richalet 等人在 1978
年提出的一种基于数值优化的算法。模型预测控制主要包含预测模型、滚动优化和反馈校正这三个要素。模型预测控制的基本实现是根据对象的约束条件和控制目标,使用成本函数来评价系统的行为,当得到优化问题的最优解后,再将这个控制策略的第一个动作应用到对象上,然后重复这个步骤。模型预测控制在对系统进行优化时,能够将处理约束的过程与优化的过程结合在一起,可以减小扰动引起的不确定性。除了能够考虑对象的约束条件和控制目标之外,与障碍物、运动、环境干扰等有关的不确定性因素也都可以在模型预测控制算法的代价函数中形式化。虽然实时性是模型预测控制的一个缺点,但是随着近年来计算机性能的提高、算法结构的改进、计算工具的优化,模型预测控制的实时性得到很大的改善,已被广泛地应用于无人机、无人车及无人船的路径规划中去。
以下从数学建模、预测方程、优化问题、反馈校正等方面进行详细推导。
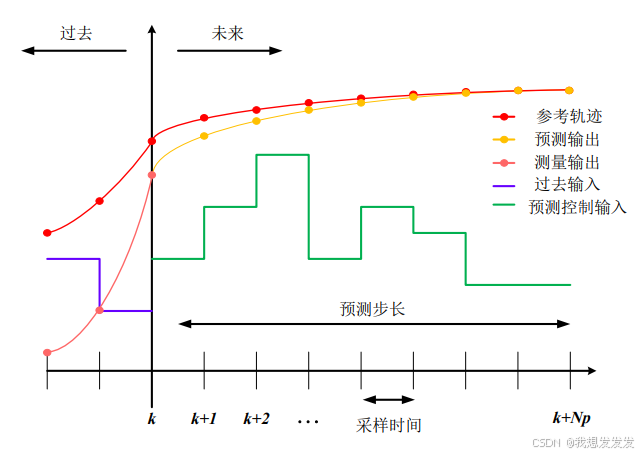
一、系统建模:离散时间状态空间模型
假设被控对象为线性时不变系统,其离散时间状态空间模型为:
{
x
k
+
1
=
A
x
k
+
B
u
k
y
k
=
C
x
k
+
D
u
k
\begin{cases} \mathbf{x}_{k+1} = \mathbf{A} \mathbf{x}_k + \mathbf{B} \mathbf{u}_k \\ \mathbf{y}_k = \mathbf{C} \mathbf{x}_k + \mathbf{D} \mathbf{u}_k \end{cases}
{xk+1=Axk+Bukyk=Cxk+Duk
- x k ∈ R n \mathbf{x}_k \in \mathbb{R}^n xk∈Rn:状态向量
- u k ∈ R m \mathbf{u}_k \in \mathbb{R}^m uk∈Rm:控制输入向量
- y k ∈ R p \mathbf{y}_k \in \mathbb{R}^p yk∈Rp:输出向量
- A ∈ R n × n \mathbf{A} \in \mathbb{R}^{n \times n} A∈Rn×n:状态转移矩阵
- B ∈ R n × m \mathbf{B} \in \mathbb{R}^{n \times m} B∈Rn×m:输入矩阵
- C ∈ R p × n \mathbf{C} \in \mathbb{R}^{p \times n} C∈Rp×n:输出矩阵
- D ∈ R p × m \mathbf{D} \in \mathbb{R}^{p \times m} D∈Rp×m:直接传递矩阵
二、预测模型:未来状态与输出的预测
在MPC中,控制器需要预测未来 N p N_p Np 步的状态和输出(称为预测时域)。假设当前时刻为 k k k,则预测方程如下:
- 状态预测序列:
x k + 1 ∣ k = A x k + B u k x k + 2 ∣ k = A x k + 1 ∣ k + B u k + 1 ⋮ x k + N p ∣ k = A N p x k + ∑ i = 0 N p − 1 A i B u k + i \mathbf{x}_{k+1|k} = \mathbf{A} \mathbf{x}_k + \mathbf{B} \mathbf{u}_k \\ \mathbf{x}_{k+2|k} = \mathbf{A} \mathbf{x}_{k+1|k} + \mathbf{B} \mathbf{u}_{k+1} \\ \vdots \\ \mathbf{x}_{k+N_p|k} = \mathbf{A}^{N_p} \mathbf{x}_k + \sum_{i=0}^{N_p-1} \mathbf{A}^i \mathbf{B} \mathbf{u}_{k+i} xk+1∣k=Axk+Bukxk+2∣k=Axk+1∣k+Buk+1⋮xk+Np∣k=ANpxk+i=0∑Np−1AiBuk+i
- x k + j ∣ k \mathbf{x}_{k+j|k} xk+j∣k:基于当前 k k k 时刻信息对 k + j k+j k+j 时刻的预测状态
- u k + i \mathbf{u}_{k+i} uk+i:未来 N u N_u Nu 步的控制输入(称为控制时域, N u ≤ N p N_u \leq N_p Nu≤Np)
- 输出预测序列:
y k + j ∣ k = C x k + j ∣ k + D u k + j \mathbf{y}_{k+j|k} = \mathbf{C} \mathbf{x}_{k+j|k} + \mathbf{D} \mathbf{u}_{k+j} yk+j∣k=Cxk+j∣k+Duk+j
将上述预测方程向量化,得到矩阵形式:
[
x
k
+
1
∣
k
x
k
+
2
∣
k
⋮
x
k
+
N
p
∣
k
]
⏟
X
k
=
[
A
A
2
⋮
A
N
p
]
⏟
Φ
x
k
+
[
B
0
⋯
0
A
B
B
⋯
0
⋮
⋮
⋱
⋮
A
N
p
−
1
B
A
N
p
−
2
B
⋯
B
]
⏟
Ψ
[
u
k
u
k
+
1
⋮
u
k
+
N
u
−
1
]
⏟
U
k
\underbrace{\begin{bmatrix} \mathbf{x}_{k+1|k} \\ \mathbf{x}_{k+2|k} \\ \vdots \\ \mathbf{x}_{k+N_p|k} \end{bmatrix}}_{\mathbf{X}_{k}} = \underbrace{\begin{bmatrix} \mathbf{A} \\ \mathbf{A}^2 \\ \vdots \\ \mathbf{A}^{N_p} \end{bmatrix}}_{\mathbf{\Phi}} \mathbf{x}_k + \underbrace{\begin{bmatrix} \mathbf{B} & \mathbf{0} & \cdots & \mathbf{0} \\ \mathbf{A} \mathbf{B} & \mathbf{B} & \cdots & \mathbf{0} \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{A}^{N_p-1} \mathbf{B} & \mathbf{A}^{N_p-2} \mathbf{B} & \cdots & \mathbf{B} \end{bmatrix}}_{\mathbf{\Psi}} \underbrace{\begin{bmatrix} \mathbf{u}_k \\ \mathbf{u}_{k+1} \\ \vdots \\ \mathbf{u}_{k+N_u-1} \end{bmatrix}}_{\mathbf{U}_k}
Xk
xk+1∣kxk+2∣k⋮xk+Np∣k
=Φ
AA2⋮ANp
xk+Ψ
BAB⋮ANp−1B0B⋮ANp−2B⋯⋯⋱⋯00⋮B
Uk
ukuk+1⋮uk+Nu−1
- Φ ∈ R N p n × n \mathbf{\Phi} \in \mathbb{R}^{N_p n \times n} Φ∈RNpn×n:状态预测基矩阵
- Ψ ∈ R N p n × N u m \mathbf{\Psi} \in \mathbb{R}^{N_p n \times N_u m} Ψ∈RNpn×Num:输入影响矩阵
三、优化问题:二次型目标函数与约束
MPC的核心是在每个时刻
k
k
k 求解以下优化问题:
min
U
k
J
=
∑
j
=
1
N
p
(
y
k
+
j
∣
k
−
r
k
+
j
)
T
Q
(
y
k
+
j
∣
k
−
r
k
+
j
)
+
∑
j
=
0
N
u
−
1
u
k
+
j
T
R
u
k
+
j
\min_{\mathbf{U}_k} \quad J = \sum_{j=1}^{N_p} \left( \mathbf{y}_{k+j|k} - \mathbf{r}_{k+j} \right)^T \mathbf{Q} \left( \mathbf{y}_{k+j|k} - \mathbf{r}_{k+j} \right) + \sum_{j=0}^{N_u-1} \mathbf{u}_{k+j}^T \mathbf{R} \mathbf{u}_{k+j}
UkminJ=j=1∑Np(yk+j∣k−rk+j)TQ(yk+j∣k−rk+j)+j=0∑Nu−1uk+jTRuk+j
s.t.
u
min
≤
u
k
+
j
≤
u
max
,
j
=
0
,
1
,
…
,
N
u
−
1
\text{s.t.} \quad \mathbf{u}_{\text{min}} \leq \mathbf{u}_{k+j} \leq \mathbf{u}_{\text{max}}, \quad j=0,1,\dots,N_u-1
s.t.umin≤uk+j≤umax,j=0,1,…,Nu−1
- r k + j \mathbf{r}_{k+j} rk+j:参考轨迹
- Q ∈ R p × p \mathbf{Q} \in \mathbb{R}^{p \times p} Q∈Rp×p:输出误差权重矩阵(半正定)
- R ∈ R m × m \mathbf{R} \in \mathbb{R}^{m \times m} R∈Rm×m:输入权重矩阵(正定)
- 约束条件:输入的上下限
将目标函数转换为矩阵形式:
J
=
(
Y
k
−
R
k
)
T
Q
f
(
Y
k
−
R
k
)
+
U
k
T
R
f
U
k
J = (\mathbf{Y}_k - \mathbf{R}_k)^T \mathbf{Q}_f (\mathbf{Y}_k - \mathbf{R}_k) + \mathbf{U}_k^T \mathbf{R}_f \mathbf{U}_k
J=(Yk−Rk)TQf(Yk−Rk)+UkTRfUk
- Y k = C f X k + D f U k \mathbf{Y}_k = \mathbf{C}_f \mathbf{X}_k + \mathbf{D}_f \mathbf{U}_k Yk=CfXk+DfUk
- C f = blockdiag ( C , C , … , C ) ∈ R N p p × N p n \mathbf{C}_f = \text{blockdiag}(\mathbf{C}, \mathbf{C}, \dots, \mathbf{C}) \in \mathbb{R}^{N_p p \times N_p n} Cf=blockdiag(C,C,…,C)∈RNpp×Npn
- D f = blockdiag ( D , D , … , D ) ∈ R N p p × N u m \mathbf{D}_f = \text{blockdiag}(\mathbf{D}, \mathbf{D}, \dots, \mathbf{D}) \in \mathbb{R}^{N_p p \times N_u m} Df=blockdiag(D,D,…,D)∈RNpp×Num
- Q f = blockdiag ( Q , Q , … , Q ) ∈ R N p p × N p p \mathbf{Q}_f = \text{blockdiag}(\mathbf{Q}, \mathbf{Q}, \dots, \mathbf{Q}) \in \mathbb{R}^{N_p p \times N_p p} Qf=blockdiag(Q,Q,…,Q)∈RNpp×Npp
- R f = blockdiag ( R , R , … , R ) ∈ R N u m × N u m \mathbf{R}_f = \text{blockdiag}(\mathbf{R}, \mathbf{R}, \dots, \mathbf{R}) \in \mathbb{R}^{N_u m \times N_u m} Rf=blockdiag(R,R,…,R)∈RNum×Num
四、最优控制序列求解:二次规划(QP)
将目标函数代入预测模型,得到:
J
=
(
C
f
Φ
x
k
+
C
f
Ψ
U
k
+
D
f
U
k
−
R
k
)
T
Q
f
(
C
f
Φ
x
k
+
C
f
Ψ
U
k
+
D
f
U
k
−
R
k
)
+
U
k
T
R
f
U
k
J = \left( \mathbf{C}_f \mathbf{\Phi} \mathbf{x}_k + \mathbf{C}_f \mathbf{\Psi} \mathbf{U}_k + \mathbf{D}_f \mathbf{U}_k - \mathbf{R}_k \right)^T \mathbf{Q}_f \left( \mathbf{C}_f \mathbf{\Phi} \mathbf{x}_k + \mathbf{C}_f \mathbf{\Psi} \mathbf{U}_k + \mathbf{D}_f \mathbf{U}_k - \mathbf{R}_k \right) + \mathbf{U}_k^T \mathbf{R}_f \mathbf{U}_k
J=(CfΦxk+CfΨUk+DfUk−Rk)TQf(CfΦxk+CfΨUk+DfUk−Rk)+UkTRfUk
展开后为关于
U
k
\mathbf{U}_k
Uk 的二次型函数:
J
=
U
k
T
H
U
k
+
2
U
k
T
G
+
常数项
J = \mathbf{U}_k^T \mathbf{H} \mathbf{U}_k + 2 \mathbf{U}_k^T \mathbf{G} + \text{常数项}
J=UkTHUk+2UkTG+常数项
其中:
H
=
(
C
f
Ψ
+
D
f
)
T
Q
f
(
C
f
Ψ
+
D
f
)
+
R
f
\mathbf{H} = (\mathbf{C}_f \mathbf{\Psi} + \mathbf{D}_f)^T \mathbf{Q}_f (\mathbf{C}_f \mathbf{\Psi} + \mathbf{D}_f) + \mathbf{R}_f
H=(CfΨ+Df)TQf(CfΨ+Df)+Rf
G
=
(
C
f
Φ
x
k
−
R
k
)
T
Q
f
(
C
f
Ψ
+
D
f
)
\mathbf{G} = (\mathbf{C}_f \mathbf{\Phi} \mathbf{x}_k - \mathbf{R}_k)^T \mathbf{Q}_f (\mathbf{C}_f \mathbf{\Psi} + \mathbf{D}_f)
G=(CfΦxk−Rk)TQf(CfΨ+Df)
求解此二次规划问题,得到最优控制序列:
U
k
∗
=
H
−
1
G
T
\mathbf{U}_k^* = \mathbf{H}^{-1} \mathbf{G}^T
Uk∗=H−1GT
仅将第一个控制量
u
k
∗
\mathbf{u}_k^*
uk∗ 作用于系统,下一时刻重复此过程(滚动优化)。
五、反馈校正:处理模型误差与扰动
实际系统中存在模型误差和外部扰动,因此需要引入反馈校正:
x
k
+
1
=
A
x
k
+
B
u
k
+
w
k
\mathbf{x}_{k+1} = \mathbf{A} \mathbf{x}_k + \mathbf{B} \mathbf{u}_k + \mathbf{w}_k
xk+1=Axk+Buk+wk
y
k
=
C
x
k
+
D
u
k
+
v
k
\mathbf{y}_k = \mathbf{C} \mathbf{x}_k + \mathbf{D} \mathbf{u}_k + \mathbf{v}_k
yk=Cxk+Duk+vk
- w k \mathbf{w}_k wk:过程噪声
- v k \mathbf{v}_k vk:测量噪声
通过实时测量的
y
k
\mathbf{y}_k
yk 计算预测误差:
e
k
=
y
k
−
y
k
∣
k
−
1
\mathbf{e}_k = \mathbf{y}_k - \mathbf{y}_{k|k-1}
ek=yk−yk∣k−1
将误差反馈到预测模型中,更新未来预测:
x
k
+
1
∣
k
=
A
x
k
+
B
u
k
+
L
e
k
\mathbf{x}_{k+1|k} = \mathbf{A} \mathbf{x}_k + \mathbf{B} \mathbf{u}_k + \mathbf{L} \mathbf{e}_k
xk+1∣k=Axk+Buk+Lek
- L \mathbf{L} L:反馈增益矩阵(通常通过卡尔曼滤波或LQR设计)
六、约束处理与可行性分析
MPC的优势在于能够显式处理输入、状态和输出约束。通过将约束转化为线性不等式:
u
min
≤
U
k
≤
u
max
x
min
≤
X
k
≤
x
max
y
min
≤
Y
k
≤
y
max
\mathbf{u}_{\text{min}} \leq \mathbf{U}_k \leq \mathbf{u}_{\text{max}} \\ \mathbf{x}_{\text{min}} \leq \mathbf{X}_k \leq \mathbf{x}_{\text{max}} \\ \mathbf{y}_{\text{min}} \leq \mathbf{Y}_k \leq \mathbf{y}_{\text{max}}
umin≤Uk≤umaxxmin≤Xk≤xmaxymin≤Yk≤ymax
这些约束可直接嵌入二次规划问题中求解。若优化问题不可行,需调整预测时域或引入松弛变量。
好的,我将用一个自动泊车的简单例子解释模型预测控制(MPC)的核心原理。
案例场景
假设你要让一辆智能汽车从当前位置(A点)水平泊入目标车位(B点),车身姿态需与车位对齐。使用MPC实现这一过程:
1. 建立系统模型
- 模型简化:假设汽车为单车模型,控制输入为方向盘转角( δ \delta δ)和加速度( a a a)。
- 状态变量:位置 ( x , y ) (x, y) (x,y)、航向角 θ \theta θ、速度 v v v。
- 运动学方程(离散化后):
{ x k + 1 = x k + v k cos θ k ⋅ Δ t y k + 1 = y k + v k sin θ k ⋅ Δ t θ k + 1 = θ k + v k L tan δ k ⋅ Δ t v k + 1 = v k + a k ⋅ Δ t \begin{cases} x_{k+1} = x_k + v_k \cos\theta_k \cdot \Delta t \\ y_{k+1} = y_k + v_k \sin\theta_k \cdot \Delta t \\ \theta_{k+1} = \theta_k + \frac{v_k}{L} \tan\delta_k \cdot \Delta t \\ v_{k+1} = v_k + a_k \cdot \Delta t \end{cases} ⎩ ⎨ ⎧xk+1=xk+vkcosθk⋅Δtyk+1=yk+vksinθk⋅Δtθk+1=θk+Lvktanδk⋅Δtvk+1=vk+ak⋅Δt
( L L L为轴距, Δ t \Delta t Δt为采样时间)
2. 预测未来行为
- 预测时域:假设未来5秒的轨迹( N = 5 N=5 N=5步)。
- 初始状态:当前位置 ( x 0 , y 0 ) (x_0, y_0) (x0,y0)、航向角 θ 0 \theta_0 θ0、速度 v 0 = 0 v_0=0 v0=0。
- 预测过程:
- 假设控制输入序列 { δ 0 , a 0 , δ 1 , a 1 , . . . , δ 4 , a 4 } \{\delta_0, a_0, \delta_1, a_1, ..., \delta_4, a_4\} {δ0,a0,δ1,a1,...,δ4,a4}。
- 用模型递推计算未来5步的状态 { x 1 , y 1 , . . . , x 5 , y 5 } \{x_1, y_1, ..., x_5, y_5\} {x1,y1,...,x5,y5}。
3. 优化控制输入
- 目标函数:最小化与目标位置的偏差,同时限制控制量变化:
J = ∑ k = 1 N [ ( x k − x B ) 2 + ( y k − y B ) 2 ] + λ ∑ k = 0 N − 1 ( δ k 2 + a k 2 ) J = \sum_{k=1}^N \left[(x_k - x_B)^2 + (y_k - y_B)^2\right] + \lambda \sum_{k=0}^{N-1} \left(\delta_k^2 + a_k^2\right) J=k=1∑N[(xk−xB)2+(yk−yB)2]+λk=0∑N−1(δk2+ak2)
( λ \lambda λ为权重系数,平衡轨迹精度与控制平滑性) - 约束条件:
- 方向盘转角范围: δ min ≤ δ k ≤ δ max \delta_{\text{min}} \leq \delta_k \leq \delta_{\text{max}} δmin≤δk≤δmax
- 加速度范围: a min ≤ a k ≤ a max a_{\text{min}} \leq a_k \leq a_{\text{max}} amin≤ak≤amax
- 求解优化:使用二次规划(QP)或其他方法,得到最优控制序列 { δ 0 ∗ , a 0 ∗ , δ 1 ∗ , . . . } \{\delta_0^*, a_0^*, \delta_1^*, ...\} {δ0∗,a0∗,δ1∗,...}。
4. 滚动执行与更新
- 执行第一步:仅实施第一个控制量 ( δ 0 ∗ , a 0 ∗ ) (\delta_0^*, a_0^*) (δ0∗,a0∗),驱动汽车移动。
- 重新测量:获取新的位置 ( x 1 ′ , y 1 ′ ) (x_1', y_1') (x1′,y1′)、航向角 θ 1 ′ \theta_1' θ1′、速度 v 1 ′ v_1' v1′。
- 更新预测:以新状态为起点,重复步骤2-4,重新优化未来5秒的轨迹。
关键优势
- 提前规划:考虑未来多步的影响,避免局部最优(如PID可能震荡)。
- 处理约束:直接限制方向盘转角和加速度,符合物理可行性。
- 动态调整:实时更新状态,适应突发障碍或模型误差。
与传统控制对比
| 方法 | 泊车路径规划方式 | 应对突发情况能力 |
|---|---|---|
| MPC | 每一步重新计算全局最优路径 | 强 |
| PID | 根据当前误差调整方向和速度 | 弱(可能撞线) |
通过这个例子,可以直观理解MPC的核心逻辑:预测-优化-执行-更新,类似于人类驾驶员不断预判下一步动作并动态调整策略。

















 5002
5002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









