









模型预测控制MPC详解(附带案例实现)
文章目录
写在前面本文是记录学习B站博主Dr.can的学习笔记,如有侵权请联系笔者删除此文。
1. 最优控制问题
最优控制问题就是研究在约束条件下达到最优的系统表现,通常系统的表现是综合分析的结果。比如考虑一个单输入单输出的系统(SISO),状态变量 x x x,输出为 y y y,要求其输出能跟踪预设的参考值 r r r,误差可以表示为 e = y − r e=y-r e=y−r,那么最优控制的目标是
min ∫ 0 t e 2 d t \min \int_0^t e^2 dt min∫0te2dt
如果同时希望输入量 u u u也能越小越好(一般的目的是减少能耗),那最优控制的目标可以是
min ∫ 0 t q × e 2 d t + r × u 2 d t \min \int_0^t q\times e^2 dt + r\times u^2 dt min∫0tq×e2dt+r×u2dt
其中 q , r q,r q,r分别是权重参数,用于调节两个目标的重要性。
考虑一个多输入多输出的系统(MIMO),系统的模型为:
d X d t = A X + B U Y = C X \begin{align*} \frac{dX}{dt} & = AX + BU \\ Y & = CX \end{align*} dtdXY=AX+BU=CX
那么可以将上述的最优化目标改写为:
J = ∫ 0 t E T Q E + U T R U d t J = \int^t_0 E^T Q E + U^T R U dt J=∫0tETQE+UTRUdt
举一个实际的例子,系统的模型如下所示:
d d t [ x 1 x 2 ] = A [ x 1 x 2 ] + B [ u 1 u 2 ] [ y 1 y 2 ] = [ x 1 x 2 ] \begin{align*} \frac{d}{dt} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} & = A \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} + B \begin{bmatrix} u_1 \\ u_2 \end{bmatrix} \\ \begin{bmatrix} y_1 \\ y_2 \end{bmatrix} & = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} \end{align*} dtd[x1x2][y1y2]=A[x1x2]+B[u1u2]=[x1x2]
设置的参考值 R R R为:
R = [ r 1 r 2 ] = [ 0 0 ] R = \begin{bmatrix} r_1 \\ r_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} R=[r1r2]=[00]
那么可以推导出误差 E E E为:
E = [ e 1 e 2 ] = [ y 1 − r 1 y 2 − r 2 ] = [ x 1 x 2 ] E = \begin{bmatrix} e_1 \\ e_2 \end{bmatrix} = \begin{bmatrix} y_1 - r_1 \\ y_2 - r_2 \end{bmatrix} = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} E=[e1e2]=[y1−r1y2−r2]=[x1x2]
那么上述最优控制的目标函数可以写成:
E T Q E = [ x 1 x 2 ] T [ q 1 0 0 q 2 ] [ x 1 x 2 ] = q 1 x 1 2 + q 2 x 2 2 U T R U = [ u 1 u 2 ] T [ r 1 0 0 r 2 ] [ u 1 u 2 ] = r 1 u 1 2 + r 2 u 2 2 J = ∫ 0 t q 1 x 1 2 + q 2 x 2 2 + r 1 u 1 2 + r 2 u 2 2 \begin{align*} E^TQE & = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix}^T \begin{bmatrix} q_1 & 0 \\ 0 & q_2 \end{bmatrix}\begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = q_1 x_1^2 + q_2 x_2^2 \\ U^TRU & = \begin{bmatrix} u_1 \\ u_2 \end{bmatrix}^T \begin{bmatrix} r_1 & 0 \\ 0 & r_2 \end{bmatrix}\begin{bmatrix} u_1 \\ u_2 \end{bmatrix} = r_1 u_1^2 +r_2 u_2^2 \\ J & = \int^t_0 q_1 x_1^2 + q_2 x_2^2 + r_1 u_1^2 + r_2 u_2^2 \end{align*} ETQEUTRUJ=[x1x2]T[q100q2][x1x2]=q1x12+q2x22=[u1u2]T[r100r2][u1u2]=r1u12+r2u22=∫0tq1x12+q2x22+r1u12+r2u22
2. 什么是MPC
MPC(Model Predictive Control,模型预测控制)的基本思想是通过建立一个系统的动态模型,并在每一个控制时刻使用这个模型来预测系统未来的行为。基于这些预测,它可以生成一个优化控制序列,然后通过执行第一个控制动作来调整系统状态,接着在下一个时刻重新计算和执行。这个过程反复进行,以使系统能够在未来的一段时间内优化一个特定的性能指标。
通常来说,MPC包括以下四个基本步骤:
-
系统模型化:建立描述系统动态行为的数学模型,通常是差分方程或微分方程。
-
预测:在当前时刻基于系统状态和控制输入,使用模型预测未来一段时间内的系统响应。
-
优化:基于预测的系统响应,通过求解一个优化问题来计算最优的控制输入序列,以最大化或最小化一个性能指标(如系统响应时间、能耗等)。
-
执行:根据优化得到的控制输入序列中的第一个值,执行这个控制动作,并将实际的系统状态反馈到下一个控制周期中
在具体实施的过程中MPC主要分为下列的三个步骤:
在k时刻:
- step1:估计/测量/读取当前的系统状态;
- step2:基于
u
k
,
u
k
+
1
,
⋯
,
u
k
+
N
\bold{u}_k, \bold{u}_{k+1}, \cdots, \bold{u}_{k+N}
uk,uk+1,⋯,uk+N来进行最优化
J = ∑ k N − 1 E k T Q E k + U k T R U k + E N T F E N ⏟ Terminal Cost J = \sum_k^{N-1} E_k^TQE_k + U_k^T R U_k + \underbrace{E_N^TFE_N}_{\text{Terminal Cost}} J=k∑N−1EkTQEk+UkTRUk+Terminal Cost ENTFEN
其中Terminal Cost代表了模型滑动窗口的末端的控制误差。 - step3:只取 u k \bold{u}_k uk,进行滚动优化控制。
3. 二次规划Quadratic Programming
为了能求解MPC问题,我们需要将其转换成二次规划(Quadratic Programming)的形式,对于二次规划已经有很多成熟的求解器了,我们只需要使用这些求解器就能顺利求解。
二次规划一般具有如下的形式:
min x x T H x + f T x subject to . . . \begin{align*} & \min_\bold{x} \bold{x}^TH\bold{x} + f^T\bold{x} \\ & \text{subject to} \quad... \end{align*} xminxTHx+fTxsubject to...
其中 H H H是正定的对称矩阵, f f f, x \bold{x} x是向量。
4. MPC为什么可以转换成QP问题(推导过程)
考虑一个离散的线性系统
x ( k + 1 ) = A n × n x ( k ) + B n × p u ( k ) x n × 1 = [ x 1 x 2 ⋮ x n ] , u p × 1 = [ u 1 u 2 ⋮ u p ] \bold{x}(k+1) = A_{n\times n}\bold{x}(k) + B_{n\times p}\bold{u}(k) \\ \bold{x}_{n\times 1} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix}, \bold{u}_{p\times1} = \begin{bmatrix} u_1 \\ u_2 \\ \vdots \\ u_p \end{bmatrix} x(k+1)=An×nx(k)+Bn×pu(k)xn×1= x1x2⋮xn ,up×1= u1u2⋮up
假设滚动的窗口大小(预测区间,Predictive Horizon)为 N N N,在 k k k时刻,预测 k k k时刻的输入为 u ( k ∣ k ) \bold{u}(k|k) u(k∣k),预测 k + 1 k+1 k+1时刻的输入为 u ( k + 1 ∣ k ) \bold{u}(k+1|k) u(k+1∣k),以此类推预测,预测区间的最后一个时刻的输入为 u ( k + N − 1 ∣ k ) \bold{u}(k+N-1|k) u(k+N−1∣k),将这些预测输入整合成一个向量
U k = [ u ( k ∣ k ) u ( k + 1 ∣ k ) ⋮ u ( k + i ∣ k ) u ( k + N − 1 ∣ k ) ] \bold{U}_k = \begin{bmatrix} \bold{u}(k|k) \\ \bold{u}(k+1|k) \\ \vdots \\ \bold{u}(k+i|k) \\ \bold{u}(k+N-1|k) \end{bmatrix} Uk= u(k∣k)u(k+1∣k)⋮u(k+i∣k)u(k+N−1∣k)
在 k k k时刻,系统的状态为 x ( k ∣ k ) \bold{x}(k|k) x(k∣k), k + 1 k+1 k+1系统的状态为 x ( k + 1 ∣ k ) \bold{x}(k+1|k) x(k+1∣k),以此类推预测,预测区间的最后一个时刻的系统的状态为 x ( k + N − 1 ∣ k ) \bold{x}(k+N-1|k) x(k+N−1∣k),然后再加上区间结束后的第一个状态 x ( k + N ∣ k ) \bold{x}(k+N|k) x(k+N∣k),将这些系统的状态整合成一个向量
X k = [ x ( k ∣ k ) x ( k + 1 ∣ k ) ⋮ x ( k + i ∣ k ) x ( k + N ∣ k ) ] \bold{X}_k = \begin{bmatrix} \bold{x}(k|k) \\ \bold{x}(k+1|k) \\ \vdots \\ \bold{x}(k+i|k) \\ \bold{x}(k+N|k) \end{bmatrix} Xk= x(k∣k)x(k+1∣k)⋮x(k+i∣k)x(k+N∣k)
假设系统的输出 y = x \bold{y}=\bold{x} y=x,设定的参考值 r = 0 \bold{r}=0 r=0,那么系统的误差为 e = y − r = x − 0 = x \bold{e}=\bold{y}-\bold{r}=\bold{x}-0 = \bold{x} e=y−r=x−0=x,为了最优化误差和最优化输入,我们可以这样表示代价函数(Cost Function)
min u J = ∑ i = 0 N − 1 ( x ( k + i ∣ k ) T Q x ( k + i ∣ k ) + u ( k + i ∣ k ) T R u ( k + i ∣ k ) ) + x ( k + N ) T F x ( k + N ) ⏟ Terminal Cost \min_\bold{u} J = \sum^{N-1}_{i=0} \Big(\bold{x}(k+i|k)^TQ \bold{x}(k+i|k) + \bold{u}(k+i|k)^TR \bold{u}(k+i|k) \Big) + \underbrace{\bold{x}(k+N)^T F \bold{x}(k+N)}_{\text{Terminal Cost}} uminJ=i=0∑N−1(x(k+i∣k)TQx(k+i∣k)+u(k+i∣k)TRu(k+i∣k))+Terminal Cost x(k+N)TFx(k+N)
但是乍一看这并不是二次规划的形式,我们可以通过化简将其转化为标准的二次规划形式。
在 k k k时刻,我们的系统状态可以表示为
x ( k ∣ k ) = x k x ( k + 1 ∣ k ) = A x ( k ∣ k ) + B u ( k ∣ k ) = A x k + B u ( k ∣ k ) x ( k + 2 ∣ k ) = A x ( k + 1 ∣ k ) + B u ( k ∣ k ) = A 2 x k + A B u ( k ∣ k ) + B u ( k + 1 ∣ k ) ⋮ x ( k + N ∣ k ) = A N x k + A N − 1 B u ( k ∣ k ) + ⋯ + B u ( k + N − 1 ∣ k ) \begin{align*} \bold{x}(k|k) & = \bold{x}_k \\ \bold{x}(k+1|k) & = A \bold{x}(k|k) + B\bold{u}(k|k) = A\bold{x}_k + B\bold{u}(k|k) \\ \bold{x}(k+2|k) & = A \bold{x}(k+1|k) + B\bold{u}(k|k) = A^2\bold{x}_k + AB\bold{u}(k|k) + B\bold{u}(k+1|k) \\ \vdots \\ \bold{x}(k+N|k) & = A^N \bold{x}_k + A^{N-1}B\bold{u}(k|k) + \cdots + B \bold{u}(k+N-1|k) \end{align*} x(k∣k)x(k+1∣k)x(k+2∣k)⋮x(k+N∣k)=xk=Ax(k∣k)+Bu(k∣k)=Axk+Bu(k∣k)=Ax(k+1∣k)+Bu(k∣k)=A2xk+ABu(k∣k)+Bu(k+1∣k)=ANxk+AN−1Bu(k∣k)+⋯+Bu(k+N−1∣k)
左边即为 X k \bold{X}_k Xk,然后将右边写成矩阵的形式
X k = [ I A A 2 ⋮ A N ] ⏟ M x k + [ 0 0 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 0 B 0 ⋯ 0 A B B ⋯ 0 ⋮ ⋮ ⋱ ⋮ A N − 1 B A N − 2 B ⋯ B ] ⏟ C U k X k = M x k + C U k \begin{align*} \bold{X}_k & = \underbrace{\begin{bmatrix} I \\ A \\ A^2 \\ \vdots \\ A^N \end{bmatrix}}_{M} \bold{x}_k + \underbrace{\begin{bmatrix} 0 & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 0 \\ B & 0 & \cdots & 0 \\ AB & B & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ A^{N-1}B & A^{N-2}B & \cdots & B \end{bmatrix}}_{C} \bold{U}_k \\ \bold{X}_k & = M \bold{x}_k + C \bold{U}_k \end{align*} XkXk=M IAA2⋮AN xk+C 0⋮0BAB⋮AN−1B0⋮00B⋮AN−2B⋯⋱⋯⋯⋯⋱⋯0⋮000⋮B Uk=Mxk+CUk
其中 C C C的前 n n n行都是 0 0 0。接下来,我们来将代价函数化成QP的形式
J = ∑ i = 0 N − 1 ( x ( k + i ∣ k ) T Q x ( k + i ∣ k ) + u ( k + i ∣ k ) T R u ( k + i ∣ k ) ) + x ( k + N ) T F x ( k + N ) = x ( k ∣ k ) T Q x ( k ∣ k ) + x ( k + 1 ∣ k ) T Q x ( k + 1 ∣ k ) + ⋯ + x ( k + N − 1 ∣ k ) T Q x ( k + N − 1 ∣ k ) + x ( k + N ∣ k ) T Q x ( k + N ∣ k ) + ∑ i = 0 N − 1 u ( k + i ∣ k ) T R u ( k + i ∣ k ) = [ x ( k ∣ k ) x ( k + 1 ∣ k ) ⋮ x ( k + i ∣ k ) x ( k + N ∣ k ) ] T [ Q Q Q ⋱ F ] ⏟ Q ˉ [ x ( k ∣ k ) x ( k + 1 ∣ k ) ⋮ x ( k + i ∣ k ) x ( k + N ∣ k ) ] + [ u ( k ∣ k ) u ( k + 1 ∣ k ) ⋮ u ( k + i ∣ k ) u ( k + N − 1 ∣ k ) ] T [ R R R ⋱ R ] ⏟ R ˉ [ u ( k ∣ k ) u ( k + 1 ∣ k ) ⋮ u ( k + i ∣ k ) u ( k + N − 1 ∣ k ) ] = X k T Q ˉ X k + U k R ˉ U k \begin{align*} J & = \sum^{N-1}_{i=0} \Big(\bold{x}(k+i|k)^TQ \bold{x}(k+i|k) + \bold{u}(k+i|k)^TR \bold{u}(k+i|k) \Big) + \bold{x}(k+N)^T F \bold{x}(k+N) \\ & = \bold{x}(k|k)^TQ\bold{x}(k|k) + \bold{x}(k+1|k)^TQ\bold{x}(k+1|k) + \cdots + \bold{x}(k+N-1|k)^TQ\bold{x}(k+N-1|k) + \bold{x}(k+N|k)^TQ\bold{x}(k+N|k) \\ & + \sum^{N-1}_{i=0}\bold{u}(k+i|k)^TR\bold{u}(k+i|k) \\ & = \begin{bmatrix} \bold{x}(k|k) \\ \bold{x}(k+1|k) \\ \vdots \\ \bold{x}(k+i|k) \\ \bold{x}(k+N|k) \end{bmatrix}^T \underbrace{\begin{bmatrix} Q & & & &\\ & Q & & &\\ & & Q & &\\ & & & \ddots & \\ & & & & F \end{bmatrix}}_{\bar{Q}}\begin{bmatrix} \bold{x}(k|k) \\ \bold{x}(k+1|k) \\ \vdots \\ \bold{x}(k+i|k) \\ \bold{x}(k+N|k) \end{bmatrix} + \begin{bmatrix} \bold{u}(k|k) \\ \bold{u}(k+1|k) \\ \vdots \\ \bold{u}(k+i|k) \\ \bold{u}(k+N-1|k) \end{bmatrix}^T \underbrace{\begin{bmatrix} R & & & &\\ & R & & &\\ & & R & &\\ & & & \ddots & \\ & & & & R \end{bmatrix}}_{\bar{R}}\begin{bmatrix} \bold{u}(k|k) \\ \bold{u}(k+1|k) \\ \vdots \\ \bold{u}(k+i|k) \\ \bold{u}(k+N-1|k) \end{bmatrix} \\ & = \bold{X}_k^T \bar{Q} \bold{X}_k + \bold{U}_k \bar{R} \bold{U}_k \end{align*} J=i=0∑N−1(x(k+i∣k)TQx(k+i∣k)+u(k+i∣k)TRu(k+i∣k))+x(k+N)TFx(k+N)=x(k∣k)TQx(k∣k)+x(k+1∣k)TQx(k+1∣k)+⋯+x(k+N−1∣k)TQx(k+N−1∣k)+x(k+N∣k)TQx(k+N∣k)+i=0∑N−1u(k+i∣k)TRu(k+i∣k)= x(k∣k)x(k+1∣k)⋮x(k+i∣k)x(k+N∣k) TQˉ QQQ⋱F x(k∣k)x(k+1∣k)⋮x(k+i∣k)x(k+N∣k) + u(k∣k)u(k+1∣k)⋮u(k+i∣k)u(k+N−1∣k) TRˉ RRR⋱R u(k∣k)u(k+1∣k)⋮u(k+i∣k)u(k+N−1∣k) =XkTQˉXk+UkRˉUk
然后再将前面推导的条件带入
J = X k T Q ˉ X k + U k R ˉ U k = ( M x k + C U k ) T Q ˉ ( M x k + C U k ) + U k R ˉ U k = x k T M T Q ˉ M x k + U k T C T Q ˉ M x k + x k T M T Q ˉ C ⏟ 2 x T C T Q ˉ M U k U k + U k T C T Q ˉ C U k + U k R ˉ U k = x k T M T Q ˉ M x k + 2 x T C T Q ˉ M U k U k + U k T C T Q ˉ C U k + U k R ˉ U k \begin{align*} J & = \bold{X}_k^T \bar{Q} \bold{X}_k + \bold{U}_k \bar{R} \bold{U}_k \\ & = (M \bold{x}_k + C \bold{U}_k)^T \bar{Q}(M \bold{x}_k + C \bold{U}_k) + \bold{U}_k \bar{R} \bold{U}_k \\ & = \bold{x}_k^TM^T\bar{Q}M\bold{x}_k + \underbrace{\bold{U}_k^TC^T\bar{Q}M\bold{x}_k + \bold{x}_k^TM^T\bar{Q}C}_{2\bold{x}^TC^T\bar{Q}M\bold{U}_k} \bold{U}_k + \bold{U}_k^TC^T\bar{Q}C \bold{U}_k + \bold{U}_k \bar{R} \bold{U}_k \\ & = \bold{x}_k^TM^T\bar{Q}M\bold{x}_k + 2\bold{x}^TC^T\bar{Q}M\bold{U}_k \bold{U}_k + \bold{U}_k^TC^T\bar{Q}C \bold{U}_k + \bold{U}_k \bar{R} \bold{U}_k \end{align*} J=XkTQˉXk+UkRˉUk=(Mxk+CUk)TQˉ(Mxk+CUk)+UkRˉUk=xkTMTQˉMxk+2xTCTQˉMUk UkTCTQˉMxk+xkTMTQˉCUk+UkTCTQˉCUk+UkRˉUk=xkTMTQˉMxk+2xTCTQˉMUkUk+UkTCTQˉCUk+UkRˉUk
其中 G = M T Q ˉ M G=M^T\bar{Q}M G=MTQˉM, E = C T Q ˉ M E=C^T\bar{Q}M E=CTQˉM, H = C T R ˉ C + R ˉ H=C^T\bar{R}C+\bar{R} H=CTRˉC+Rˉ,那么 J J J可以化简为:
J = x k T G x k + 2 U k T E x k + U k T H U k J = \bold{x}_k^T G \bold{x}_k + 2\bold{U}_k^T E \bold{x}_k + \bold{U}_k^T H \bold{U}_k J=xkTGxk+2UkTExk+UkTHUk
其中 x k T G x k \bold{x}_k^T G \bold{x}_k xkTGxk是初始状态,是一个常量,在优化的过程中可以忽略。最终的代价函数可以表示为
min U J = U k T E x k + 0.5 × U k T H U k G = M T Q ˉ M E = C T Q ˉ M H = C T R ˉ C + R ˉ Q ˉ = [ Q ⋯ ⋮ Q ⋮ ⋯ F ] , R ˉ = [ R ⋯ ⋮ ⋱ ⋮ ⋯ R ] \min_\bold{U} J = \bold{U}_k^T E \bold{x}_k + 0.5 \times\bold{U}_k^T H \bold{U}_k \\ G=M^T\bar{Q}M \\ E=C^T\bar{Q}M \\ H=C^T\bar{R}C+\bar{R} \\ \bar{Q} = \begin{bmatrix} Q & \cdots & \\ \vdots & Q & \vdots \\ & \cdots & F \end{bmatrix}, \bar{R} = \begin{bmatrix} R & \cdots & \\ \vdots & \ddots & \vdots \\ & \cdots & R \end{bmatrix} UminJ=UkTExk+0.5×UkTHUkG=MTQˉME=CTQˉMH=CTRˉC+RˉQˉ= Q⋮⋯Q⋯⋮F ,Rˉ= R⋮⋯⋱⋯⋮R
这就是一个标准的QP问题。
5. MPC总结
5.1 MPC的优势劣势
😄MPC的优势在于:
- 可以处理多输入多数出的系统(MIMO),PID控制只能在一个PID环内控制一个系统状态,当系统状态相互影响的时候PID控制往往难以设计,MPC就体现出了其优势
- MPC的另一个优势在于可以处理约束条件,约束很重要,因为违反它们会导致不良后果。
😄MPC的不足在于:
- MPC是在线滚动优化的,所以需要比较强的算力。
5.2 MPC的衍生算法
😄如何选择合适的MPC?
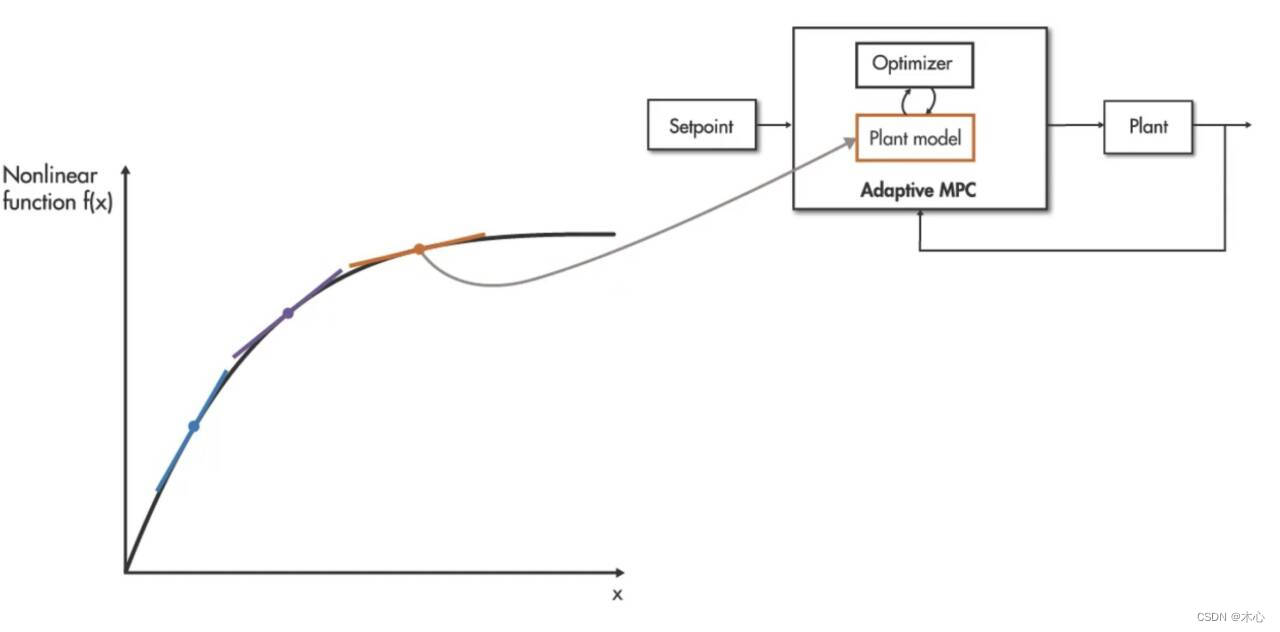
自适应MPC(Adaptive MPC)
在自适应MPC 中,线性模型是随着工作条件的变化而动态计算的,并且在每个时间步长,您都可以使用此线性模型更新。MPC控制器使用的内部被控对象模型,请注意,在自适应MPC 中,优化问题的结构在不同的工作点上保持不变。这意味着在预测范围内,状态数量和约束数量不会因不同的操作条件而改变。
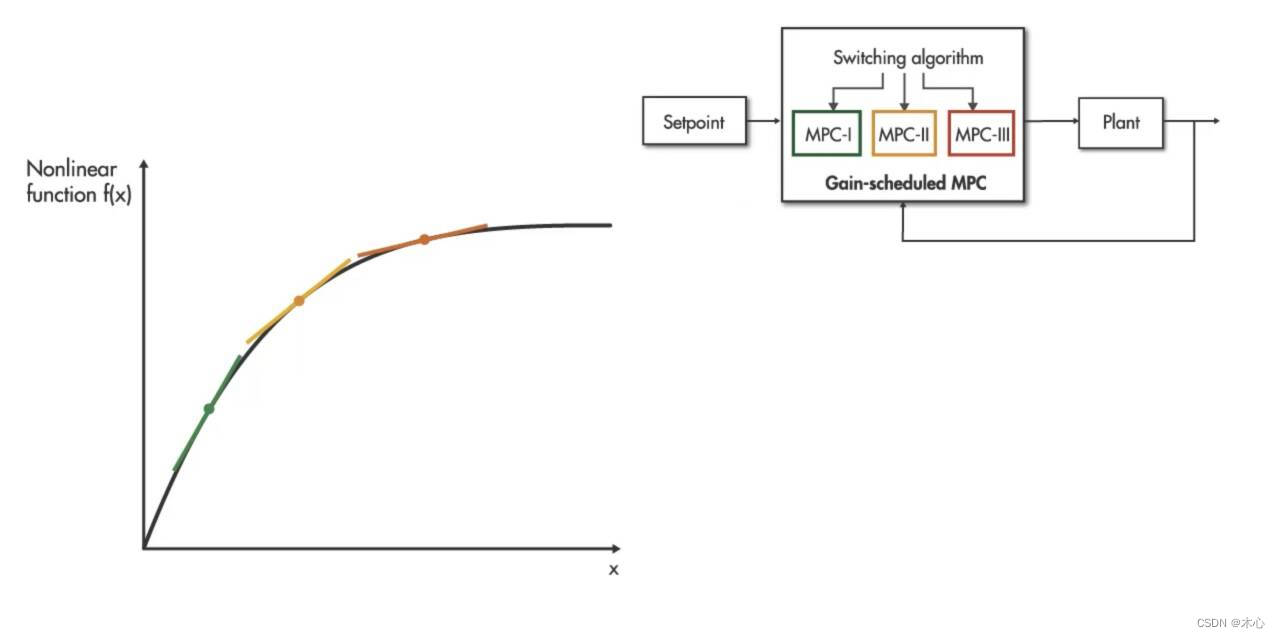
增益调度MPC(Gain-scheduled MPC)
如果它们确实发生了变化,则应使用增益调度MPC。在增益调度MPC 中,您可以在感兴趣的工作点进行离线线性化,并为每个工作点设计一个线性MPC控制器。每个控制器彼此独立,因此可能具有不同数量的状态和不同数量的约束。
小结:
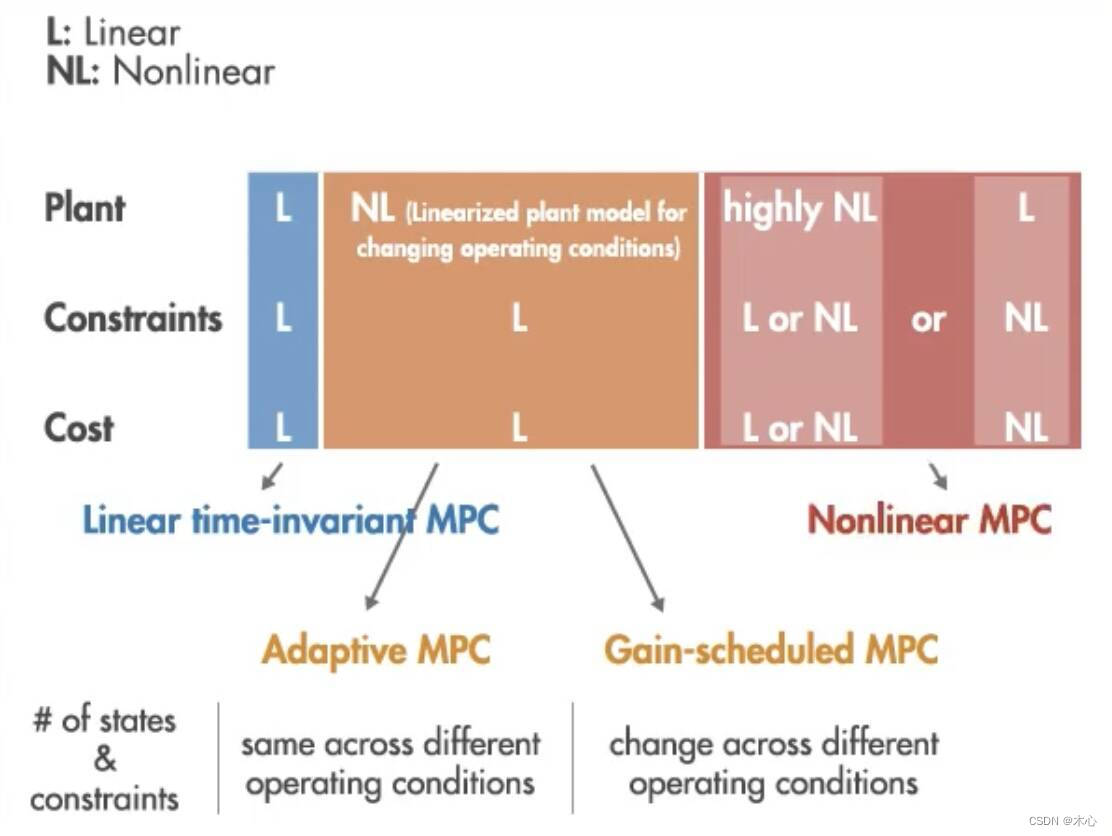
如果被控对象是非线性的,但可以通过线性模型逼近,则可以使用自适应MPC 控制器和如果被控对象是非线性的且状态的维度和约束的数量会发生变化,那么应该使用增益调度的MPC控制器。如果优化问题的结构在不同的工作条件下没有变化,则应使用自适应 MPC;但是,如果该结构有变化,则使用增益调度 MPC;如果因您有一个无法通过线性化进行良好逼近的高度非线性系统,从而导致以上这些方法都不起作用,则可以使用非线性MPC。具体可以如下图所示:
6. 示例实现
这个示例系统的状态方程为
[ x 1 ( k + 1 ) x 2 ( k + 1 ) ] = [ 1 0.1 − 1 2 ] [ x 1 ( k ) x 2 ( k ) ] + [ 0.2 1 0.5 2 ] [ u 1 ( k ) u 2 ( k ) ] \begin{bmatrix} x_1(k+1) \\ x_2(k+1) \end{bmatrix} = \begin{bmatrix} 1 & 0.1 \\ -1 & 2 \end{bmatrix}\begin{bmatrix} x_1(k) \\ x_2(k) \end{bmatrix} + \begin{bmatrix} 0.2 & 1 \\ 0.5 & 2 \end{bmatrix}\begin{bmatrix} u_1(k) \\ u_2(k) \end{bmatrix} [x1(k+1)x2(k+1)]=[1−10.12][x1(k)x2(k)]+[0.20.512][u1(k)u2(k)]
[ y 1 ( k ) y 2 ( k ) ] = [ x 1 ( k ) x 2 ( k ) ] , [ r 1 ( k ) r 2 ( k ) ] = [ 0 0 ] \begin{bmatrix} y_1(k) \\ y_2(k) \end{bmatrix} = \begin{bmatrix} x_1(k) \\ x_2(k) \end{bmatrix}, \begin{bmatrix} r_1(k) \\ r_2(k) \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} [y1(k)y2(k)]=[x1(k)x2(k)],[r1(k)r2(k)]=[00]
Dr_can提供的matlab/octave示例代码
MPC_Test.m
%% 清屏
clear;
close all;
clc;
%% 加载 optim package,若使用matlab,则注释掉此行
pkg load optim;
%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 第一步,定义状态空间矩阵
%% 定义状态矩阵 A, n x n 矩阵
A=[1 0.1; -1 2];
n=size(A,1);
%% 定义输入矩阵 B, n x p 矩阵
B=[ 0.2 1; 0.5 2];
p=size(B,2);
%% 定义Q矩阵,n x n 矩阵
Q=[100 0;0 1];
%% 定义F矩阵,n x n 矩阵
F=[100 0;0 1];
%% 定义R矩阵,p x p 矩阵
R=[1 0 ;0 .1];
%% 定义step数量k
k_steps=100;
%% 定义矩阵 X_K, n x k 矩 阵
X_K = zeros(n,k_steps);
%% 初始状态变量值, n x 1 向量
X_K(:,1) =[20;-20];
%% 定义输入矩阵 U_K, p x k 矩阵
U_K=zeros(p,k_steps);
%% 定义预测区间K
N=5;
%% Call MPC_Matrices 函数 求得 E,H矩阵
[E,H]=MPC_Matrices(A,B,Q,R,F,N);
%% 计算每一步的状态变量的值
for k = 1 : k_steps
%% 求得U_K(:,k)
U_K(:,k) = Prediction(X_K(:,k),E,H,N,p);
%% 计算第k+1步时状态变量的值
X_K(:,k+1)=(A*X_K(:,k)+B*U_K(:,k));
end
%% 绘制状态变量和输入的变化
subplot(2, 1, 1);
hold;
for i =1 :size (X_K,1)
plot (X_K(i,:));
end
legend("x1","x2")
hold off;
subplot(2, 1, 2);
hold;
for i =1 : size (U_K,1)
plot (U_K(i,:));
end
legend("u1","u2")
MPC_Matrices.m
function [E , H]=MPC_Matrices(A,B,Q,R,F,N)
n=size(A,1);% A 是 n x n 矩阵, 得到 n
p=size(B,2);% B 是 n x p 矩阵, 得到 p
%%%%%%%%%%%%
M=[eye(n);zeros(N*n,n)];% 初始化 M 矩阵. M 矩阵是 (N+1)n x n的,它上面是 n x n 个 "I", 这一步先把下半部分写成 0
C=zeros((N+1)*n,N*p); % 初始化 C 矩阵, 这一步令它有 (N+1)n x NP 个 0
% 定义M 和 C
tmp=eye(n);%定义一个n x n 的 I 矩阵
% 更新M和C
for i=1:N % 循环,i 从 1到 N
%定义当前行数,从i x n开始,共n行
rows =i*n+(1:n);
C(rows,:)=[tmp*B,C(rows-n, 1:end-p)]; %将c矩阵填满
tmp= A*tmp;%每一次将tmp左乘一次A
M(rows,:)=tmp;%将M矩阵写满
end
% 定义Q_bar和R_bar
Q_bar = kron(eye(N),Q);
Q_bar = blkdiag(Q_bar,F);
R_bar = kron(eye(N),R);
% 计算G, E, H
G=M'*Q_bar*M;% G: n x n
E=C'*Q_bar*M;% E: NP x n
H=C'*Q_bar*C+R_bar;% NP x NP
end
Prediction.m
function u_k= Prediction(x_k,E,H,N,p)
U_k = zeros(N*p,1); % NP x 1
U_k = quadprog(H,E*x_k);
u_k = U_k(1:p,1); % 取第一个结果
end
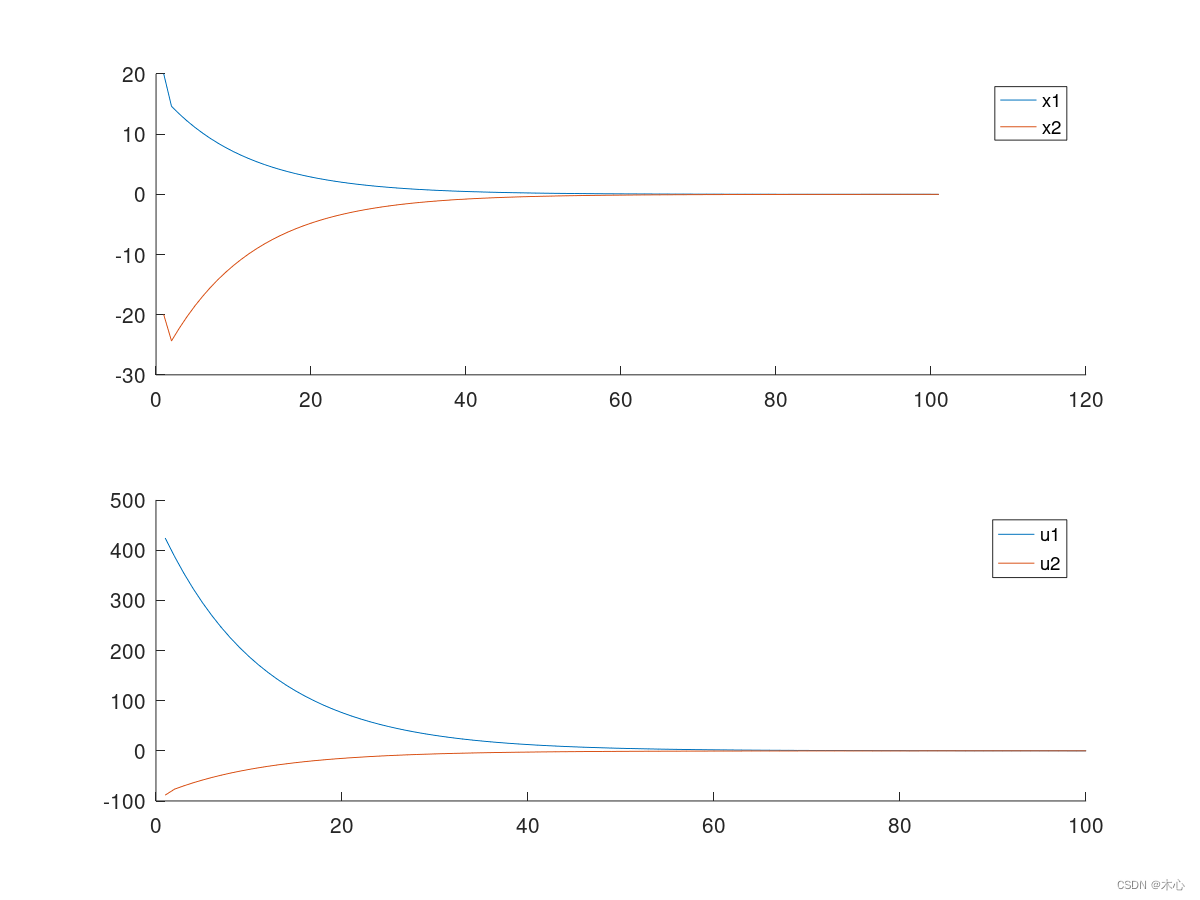
仿真的结果如下
使用CasaDi Python API重新实现了Dr_can视频里提到的示例代码
import numpy as np
import matplotlib.pyplot as plt
import casadi as ca
# 系统参数
N = 5 # 预测区间
k_steps = 100
# 状态矩阵A和输入矩阵B
A = np.array([[1, 0.1], [-1, 2]])
B = np.array([[0.2, 1], [0.5, 2]])
n = A.shape[0]
p = B.shape[1]
# Q、F、R矩阵
Q = np.diag([100, 1])
F = np.diag([100, 1])
R = np.diag([1, 0.1])
# 定义step的数量
k_steps = 100
# 开辟所有状态x的存储空间并初始状态
X_k = np.zeros((n, k_steps+1))
X_k[:,0] = np.array([20,-20])
# 开辟所有控制输入u的存储空间
U_k = np.zeros((p, k_steps))
# 计算QP中代价函数相关的矩阵
def get_QPMatrix(A, B, Q, R, F, N):
M = np.vstack([np.eye(n), np.zeros((N*n, n))])
C = np.zeros(((N+1)*n, N*p))
temp = np.eye(n)
for i in range(1,N+1):
rows = i * n + np.arange(n)
C[rows,:] = np.hstack([temp @ B, C[rows-n, :-p]])
temp = A @ temp
M[rows,:] = temp
Q_ = np.kron(np.eye(N), Q)
rows_Q, cols_Q = Q_.shape
rows_F, cols_F = F.shape
Q_bar = np.zeros((rows_Q+rows_F, cols_Q+cols_F))
Q_bar[:rows_Q, :cols_Q] = Q_
Q_bar[rows_Q:, cols_Q:] = F
R_bar = np.kron(np.eye(N), R)
# G = M.T @ Q_bar @ M
E = C.T @ Q_bar @ M
H = C.T @ Q_bar @ C + R_bar
return E, H
# 定义MPC优化问题
def mpc_prediction(x_k, E, H, N, p):
# 定义优化变量
U = ca.SX.sym('U', N * p)
# 定义目标函数
objective = 0.5 * ca.mtimes([U.T, H, U]) + ca.mtimes([U.T, E, x_k])
qp = {'x': U, 'f': objective}
opts = {'print_time': False, 'ipopt': {'print_level': 0}}
solver = ca.nlpsol('solver', 'ipopt', qp, opts)
# 求解问题
sol = solver()
# 提取最优解
U_k = sol['x'].full().flatten()
u_k = U_k[:p] # 取第一个结果
return u_k
if __name__ == "__main__":
# Get QP Matrix
E, H = get_QPMatrix(A, B, Q, R, F, N)
# Simulation
for i in range(k_steps):
x_k = X_k[:,i]
u_k = mpc_prediction(x_k, E, H, N, p)
x_k = A @ x_k + B @ u_k
X_k[:,i+1] = x_k
U_k[:,i] = u_k
# 绘制结果
plt.subplot(2, 1, 1)
for i in range(X_k.shape[0]):
plt.plot(X_k[i, :], label=f"x{i+1}")
plt.legend()
plt.title("State Variables")
plt.xlabel("Time Step")
plt.ylabel("State Value")
# 第二个子图: 控制输入
plt.subplot(2, 1, 2)
for i in range(U_k.shape[0]):
plt.plot(U_k[i, :], label=f"u{i+1}")
plt.legend()
plt.title("Control Inputs")
plt.xlabel("Time Step")
plt.ylabel("Control Value")
# 调整布局并显示
plt.tight_layout()
plt.show()
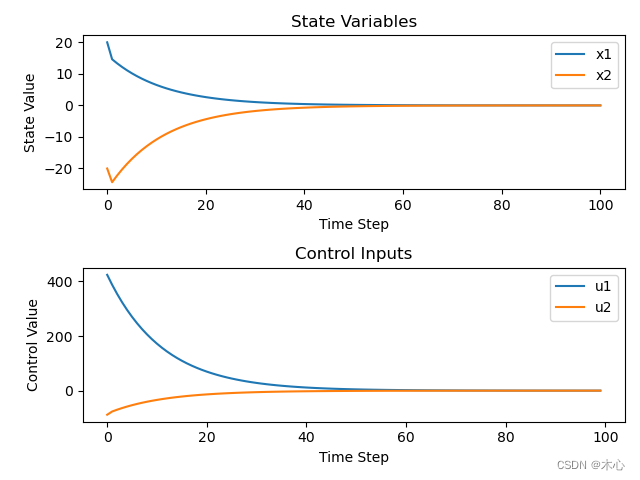
结果如下
Reference
[1]MPC模型预测控制器
[2]Understanding Model Predictive Control
[3]CasADi_MPC_MHE_Python
[4]MPC-and-MHE-implementation-in-MATLAB-using-Casadi
[5]MPC and MHE implementation in Matlab using Casadi



















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











