







FlashAttention 原理
Attention 计算 s o f t m a x ( Q i , K j T ) V j softmax(Q_i, K_j^T)V_j softmax(Qi,KjT)Vj,
softmax 对某个 q i q_i qi与所有 k j k_j kj的 attention score( q i ⋅ k 1 , q i ⋅ k 2 , . . . , q i ⋅ k n q_i\cdot k_1,q_i\cdot k_2,...,q_i\cdot k_n qi⋅k1,qi⋅k2,...,qi⋅kn)做归一化。
原生 softmax 计算
s o f t m a x ( x 1 , x 2 , . . . , x n ) = ( e x 1 e x 1 + e x 2 + . . . + e x n , e x 2 e x 1 + e x 2 + . . . + e x n , . . . , e x n e x 1 + e x 2 + . . . + e x n ) softmax(x_1,x_2,...,x_n)=(\dfrac{e^{x_1}}{e^{x_1}+e^{x_2}+...+e^{x_n}},\dfrac{e^{x_2}}{e^{x_1}+e^{x_2}+...+e^{x_n}},...,\dfrac{e^{x_n}}{e^{x_1}+e^{x_2}+...+e^{x_n}}) softmax(x1,x2,...,xn)=(ex1+ex2+...+exnex1,ex1+ex2+...+exnex2,...,ex1+ex2+...+exnexn)
由于指数计算容易溢出,safe-softmax 相对于原生的 softmax 计算在每个指数项都减去一个 max 值。
m a x = m a x ( x 1 , x 2 , . . . , x n ) max=max(x_1,x_2,...,x_n) max=max(x1,x2,...,xn)
s a f e − s o f t m a x ( x 1 , x 2 , . . . , x n ) = ( e x 1 − m a x e x 1 − m a x + e x 2 − m a x + . . . + e x n − m a x , e x 2 − m a x e x 1 − m a x + e x 2 − m a x + . . . + e x n − m a x , . . . , e x n − m a x e x 1 − m a x + e x 2 − m a x + . . . + e x n − m a x ) safe-softmax(x_1,x_2,...,x_n)=(\dfrac{e^{x_1-max}}{e^{x_1-max}+e^{x_2-max}+...+e^{x_n-max}},\dfrac{e^{x_2-max}}{e^{x_1-max}+e^{x_2-max}+...+e^{x_n-max}},...,\dfrac{e^{x_n-max}}{e^{x_1-max}+e^{x_2-max}+...+e^{x_n-max}}) safe−softmax(x1,x2,...,xn)=(ex1−max+ex2−max+...+exn−maxex1−max,ex1−max+ex2−max+...+exn−maxex2−max,...,ex1−max+ex2−max+...+exn−maxexn−max)
由于 m a x max max需要全局信息,需要遍历所有 X X X结果以后得到,因此原生的 safe softmax 计算需要遍历三遍 X X X。如果 SRAM 没有足够的空间存储 X X X,那么需要每次都取出对应的 q i , k j q_i,k_j qi,kj来 recompute x j x_{j} xj,因此 I/O 开销大。

为此,Online softmax 改进了 safe softmax,将 3 个 pass 减为 2 个 pass,减少了一遍 I/O。Online softmax 的原理是在遍历 x i x_i xi的过程中动态更新当前遇到过的局部最大值 m i = m a x ( x 1 , x 2 , . . . , x i ) m_{i}=max(x_1,x_2,...,x_i) mi=max(x1,x2,...,xi),在每轮迭代时通过修正将前面用到的局部最大值 m i − 1 m_{i-1} mi−1代替为 m i m_{i} mi,修正方式是把上一轮的结果乘以因数 e m i − 1 − m i e^{m_{i-1}-m_{i}} emi−1−mi。

基于上面online的思想,FlashAttention 把 Attention 计算优化为 1 pass。
在 Attention 计算中,某个 q q q向量与所有 k j , v j k_j,v_j kj,vj计算得到结果向量 o o o
o = ∑ j = 1 n e x j − m n d n ′ v j o=\sum_{j=1}^{n}\dfrac{e^{x_j-m_n}}{d^{'}_{n}}v_j o=j=1∑ndn′exj−mnvj
在遍历时,定义第 i i i轮的结果为:
o i = ∑ j = 1 i e x j − m i d i ′ v j o_i=\sum_{j=1}^{i}\dfrac{e^{x_j-m_i}}{d^{'}_{i}}v_j oi=j=1∑idi′exj−mivj
当第 n 轮计算完成时, o n = o o_n=o on=o。第 i 轮的结果与第 i − 1 i-1 i−1轮的结果之间的关系如下,因此可以达到 1 pass 就计算出 o o o的效果。
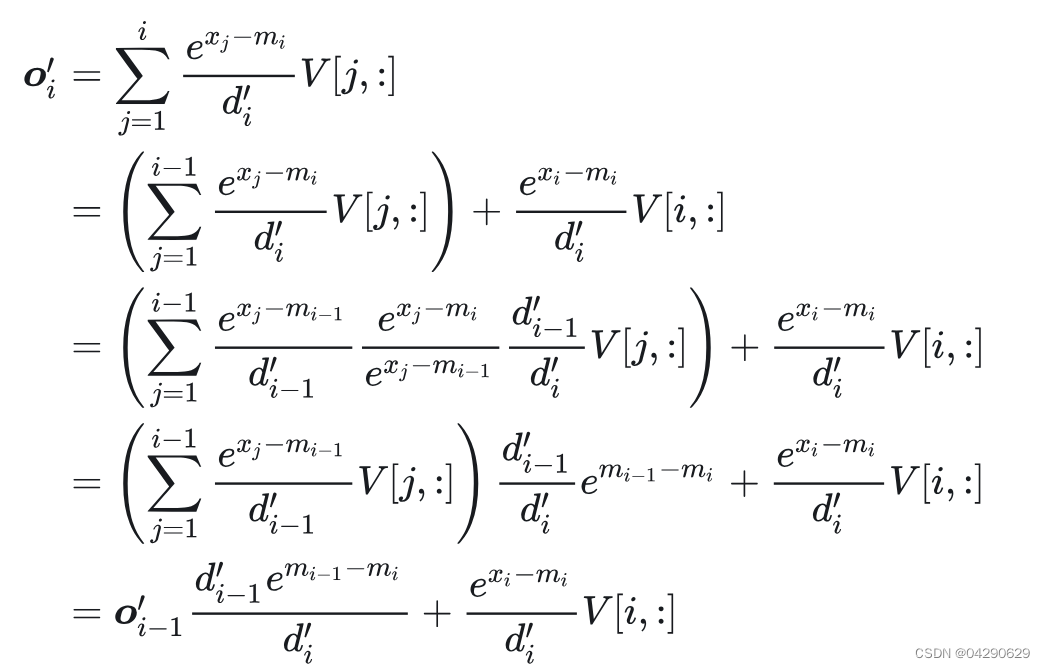
在此基础上,FlashAttention-2 采用分块计算,把 K , V K,V K,V在 sequence length 维度上分成 T c T_c Tc个大小相同的 K i , V i K_i,V_i Ki,Vi块,把 Q Q Q在 sequence length 维度上分成 T r T_r Tr个大小相同的 K i , V i K_i,V_i Ki,Vi块。

计算时,先 load Q i Q_i Qi,然后内层循环每轮计算 load 一对 K i , V i K_i,V_i Ki,Vi块。这样每个 Q i Q_i Qi只需要 load 一次,并且不同的 Q i Q_i Qi之间可以没有干扰地做并行计算。

FlashDecoding 原理
FlashAttention 在 Q Q Q的 sequence length 维度上并行,因此在 prefill 阶段可以良好地并行,但是在 decode 阶段只有上一轮新生成的 token 的 q q q,因此无法在 Q Q Q的 sequence length 维度上并行。为此,Flash-Decoding 让 LLM 在 decode 阶段能够在 K , V K,V K,V的 sequence length 维度上并行。FlashDecoding 将 K , V K,V K,V分块,每个块分别与 q q q做 FlashAttention,分块之间可以并行计算,分块得到的结果通过 reduce 得到最终结果。Reduce 时,只需要用到每个分块计算出的 o j ( 1 × D ) , l j ( 1 × 1 ) , m j ( 1 × 1 ) o_j(1\times D),l_j(1\times 1),m_j(1\times 1) oj(1×D),lj(1×1),mj(1×1),Reduce 操作的时间复杂度非常低: O ( D ⋅ T c ) O(D\cdot T_c) O(D⋅Tc)。
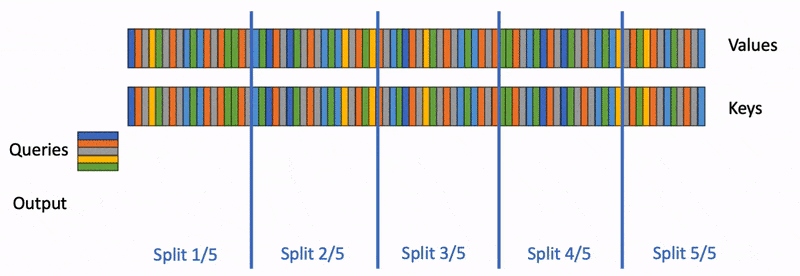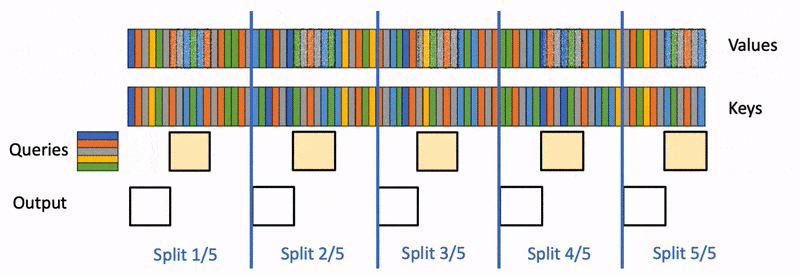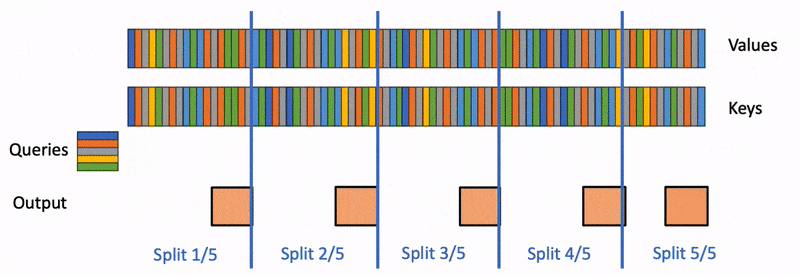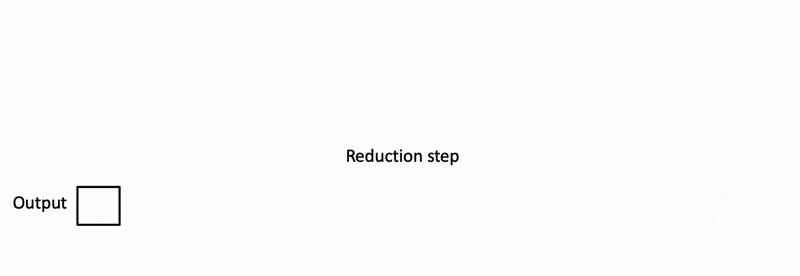
FlashAttention 和 FlashDecoding 在 vLLM 中的应用
vLLM 在 prefill 阶段调用 xformers 的 flash-attn 后端,间接使用 FlashAttention 进行推理;在 decode 阶段,当单个 GPU 上 Attention Head 较少时,此时 Head 维度上的并行性低,因此 vLLM 的 PagedAttention V2 使用了 FlashDecoding 的思路进行优化,在 K , V K,V K,V的 sequence length 维度上增加并行性。
“PagedAttention V2 (#1348) implements a similar idea to boost the performance when the batch size or the number of attention heads per GPU is small.”
Does vLLM support flash attention? · vllm-project/vllm · Discussion #425
does vllm use Flash-Decoding? · Issue #1362 · vllm-project/vllm
参考
From Online Softmax to FlashAttention
Flash-Decoding for long-context inference
FlashAttention 的速度优化原理是怎样的? - 知乎
[Attention 优化][2w 字]🔥 原理&图解: 从 Online-Softmax 到 FlashAttention V1/V2/V3
[Decoding 优化]🔥 原理&图解 FlashDecoding/FlashDecoding++
Towards-100x-Speedup-Full-Stack-Transformer-Inference-Optimization

















 1560
1560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









