









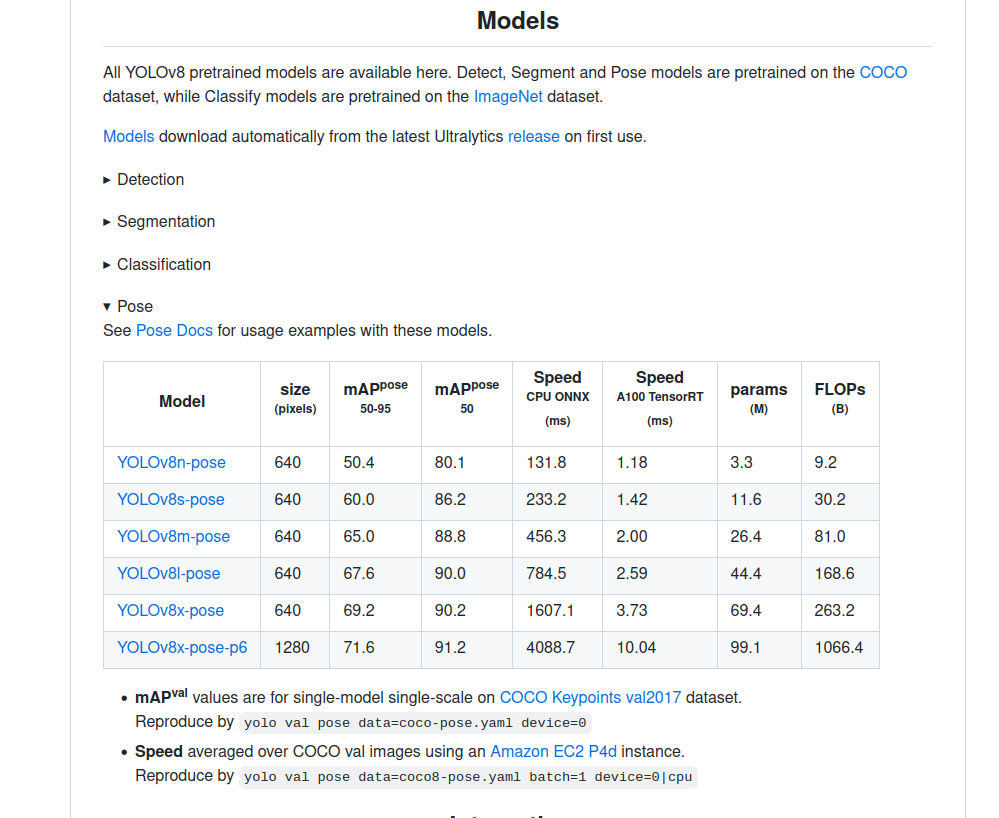
目录
1、下载权重
我这里之前在做实例分割的时候,项目已经下载到本地,环境也安装好了,只需要下载pose的权重就可以
2、python 推理
yolo task=pose mode=predict model=yolov8n-pose.pt source=0 show=true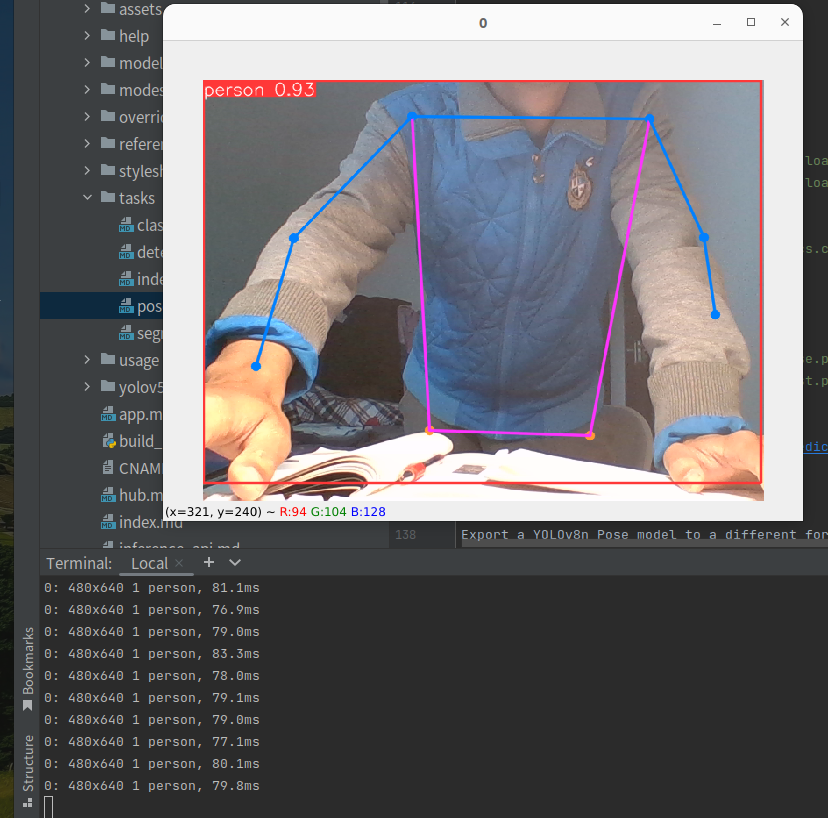
3、转ONNX格式
yolo export model=yolov8n-pose.pt format=onnx 输出:
(yolo) jason@honor:~/PycharmProjects/pytorch_learn/yolo/ultralytics-main-yolov8$ yolo export model=yolov8n-pose.pt format=onnx
Ultralytics YOLOv8.0.94 🚀 Python-3.8.13 torch-2.0.0+cu117 CPU
YOLOv8n-pose summary (fused): 187 layers, 3289964 parameters, 0 gradients, 9.2 GFLOPs
PyTorch: starting from yolov8n-pose.pt with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 56, 8400) (6.5 MB)
ONNX: starting export with onnx 1.13.1 opset 17...
============= Diagnostic Run torch.onnx.export version 2.0.0+cu117 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
ONNX: export success ✅ 0.8s, saved as yolov8n-pose.onnx (12.9 MB)
Export complete (1.4s)
Results saved to /home/jason/PycharmProjects/pytorch_learn/yolo/ultralytics-main-yolov8
Predict: yolo predict task=pose model=yolov8n-pose.onnx imgsz=640
Validate: yolo val task=pose model=yolov8n-pose.onnx imgsz=640 data=/usr/src/app/ultralytics/datasets/coco-pose.yaml
Visualize: https://netron.app
用netron查看一下:
如上图所是,YOLOv8n-pose只有一个输出:
output0: float32[1,56,8400]。这里的8400,表示有8400个检测框,56为4边界框坐标信息+人这个类别预测分数,17*3关键点信息。每个关键点由x,y,v组成,v代表该点是否可见,v小于 0.5 时,表示这个关键点可能在图外,可以考虑去除掉。
COCO的annotation一共有17个关节点。
分别是:“nose”,“left_eye”, “right_eye”,“left_ear”, “right_ear”,“left_shoulder”, “right_shoulder”,“left_elbow”, “right_elbow”,“left_wrist”, “right_wrist”,“left_hip”, “right_hip”,“left_knee”, “right_knee”,“left_ankle”, “right_ankle”。示例图如下:
4、ONNX RUNTIME C++ 部署
第二篇参考文章的github项目,以此为参考,实现ONNX RUNTIME C++部署
视频输入,效果如下:

utils.h
#pragma once
#include <iostream>
#include <opencv2/opencv.hpp>
struct OutputPose {
cv::Rect_<float> box;
int label =0;
float confidence =0.0;
std::vector<float> kps;
};
void DrawPred(cv::Mat& img, std::vector<OutputPose>& results,
const std::vector<std::vector<unsigned int>> &SKELLTON,
const std::vector<std::vector<unsigned int>> &KPS_COLORS,
const std::vector<std::vector<unsigned int>> &LIMB_COLORS);
void LetterBox(const cv::Mat& image, cv::Mat& outImage,
cv::Vec4d& params,
const cv::Size& newShape = cv::Size(640, 640),
bool autoShape = false,
bool scaleFill=false,
bool scaleUp=true,
int stride= 32,
const cv::Scalar& color = cv::Scalar(114,114,114));
utils.cpp
#pragma once
#include "utils.h"
using namespace cv;
using namespace std;
void LetterBox(const cv::Mat& image, cv::Mat& outImage,
cv::Vec4d& params,
const cv::Size& newShape,
bool autoShape,
bool scaleFill,
bool scaleUp,
int stride,
const cv::Scalar& color)
{
if (false) {
int maxLen = MAX(image.rows, image.cols);
outImage = Mat::zeros(Size(maxLen, maxLen), CV_8UC3);
image.copyTo(outImage(Rect(0, 0, image.cols, image.rows)));
params[0] = 1;
params[1] = 1;
params[3] = 0;
params[2] = 0;
}
// 取较小的缩放比例
cv::Size shape = image.size();
float r = std::min((float)newShape.height / (float)shape.height,
(float)newShape.width / (float)shape.width);
if (!scaleUp)
r = std::min(r, 1.0f);
printf("原图尺寸:w:%d * h:%d, 要求尺寸:w:%d * h:%d, 即将采用的缩放比:%f\n",
shape.width, shape.height, newShape.width, newShape.height, r);
// 依据前面的缩放比例后,原图的尺寸
float ratio[2]{r,r};
int new_un_pad[2] = { (int)std::round((float)shape.width * r), (int)std::round((float)shape.height * r)};
printf("等比例缩放后的尺寸该为:w:%d * h:%d\n", new_un_pad[0], new_un_pad[1]);
// 计算距离目标尺寸的padding像素数
auto dw = (float)(newShape.width - new_un_pad[0]);
auto dh = (float)(newShape.height - new_un_pad[1]);
if (autoShape)
{
dw = (float)((int)dw % stride);
dh = (float)((int)dh % stride);
}
else if (scaleFill)
{
dw = 0.0f;
dh = 0.0f;
new_un_pad[0] = newShape.width;
new_un_pad[1] = newShape.height;
ratio[0] = (float)newShape.width / (float)shape.width;
ratio[1] = (float)newShape.height / (float)shape.height;
}
dw /= 2.0f;
dh /= 2.0f;
printf("填充padding: dw=%f , dh=%f\n", dw, dh);
// 等比例缩放
if (shape.width != new_un_pad[0] && shape.height != new_un_pad[1])
{
cv::resize(image, outImage, cv::Size(new_un_pad[0], new_un_pad[1]));
}
else{
outImage = image.clone();
}
// 图像四周padding填充,至此原图与目标尺寸一致
int top = int(std::round(dh - 0.1f));
int bottom = int(std::round(dh + 0.1f));
int left = int(std::round(dw - 0.1f));
int right = int(std::round(dw + 0.1f));
params[0] = ratio[0]; // width的缩放比例
params[1] = ratio[1]; // height的缩放比例
params[2] = left; // 水平方向两边的padding像素数
params[3] = top; //垂直方向两边的padding像素数
cv::copyMakeBorder(outImage, outImage, top, bottom, left, right, cv::BORDER_CONSTANT, color);
}
void DrawPred(cv::Mat& img, std::vector<OutputPose>& results,
const std::vector<std::vector<unsigned int>> &SKELLTON,
const std::vector<std::vector<unsigned int>> &KPS_COLORS,
const std::vector<std::vector<unsigned int>> &LIMB_COLORS)
{
const int num_point =17;
for (auto &result:results){
int left,top,width, height;
left = result.box.x;
top = result.box.y;
width = result.box.width;
height = result.box.height;
// printf("x: %d y:%d w:%d h%d\n",(int)left, (int)top, (int)result.box.width, (int)result.box.height);
// 框出目标
rectangle(img, result.box,Scalar(0,0,255), 2, 8);
// 在目标框左上角标识目标类别以及概率
string label = "person:" + to_string(result.confidence) ;
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
putText(img, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0,0,255), 2);
// 连线
auto &kps = result.kps;
// cout << "该目标关键点:" << kps.size() << endl;
for (int k=0; k<num_point+2; k++){// 不要设置为>0.5f ,>0.0f显示效果比较好
// 关键点绘制
if (k<num_point){
int kps_x = std::round(kps[k*3]);
int kps_y = std::round(kps[k*3 + 1]);
float kps_s = kps[k*3 + 2];
// printf("x:%d y:%d s:%f\n", kps_x, kps_y, kps_s);
if (kps_s > 0.0f){
cv::Scalar kps_color = Scalar(KPS_COLORS[k][0],KPS_COLORS[k][1],KPS_COLORS[k][2]);
cv::circle(img, {kps_x, kps_y}, 5, kps_color, -1);
}
}
auto &ske = SKELLTON[k];
int pos1_x = std::round(kps[(ske[0] -1) * 3]);
int pos1_y = std::round(kps[(ske[0] -1) * 3 + 1]);
int pos2_x = std::round(kps[(ske[1] -1) * 3]);
int pos2_y = std::round(kps[(ske[1] -1) * 3 + 1]);
float pos1_s = kps[(ske[0] -1) * 3 + 2];
float pos2_s = kps[(ske[1] -1) * 3 + 2];
if (pos1_s > 0.0f && pos2_s >0.0f){// 不要设置为>0.5f ,>0.0f显示效果比较好
cv::Scalar limb_color = cv::Scalar(LIMB_COLORS[k][0], LIMB_COLORS[k][1], LIMB_COLORS[k][3]);
cv::line(img, {pos1_x, pos1_y}, {pos2_x, pos2_y}, limb_color);
}
// 跌倒检测
float pt5_x = kps[5*3];
float pt5_y = kps[5*3 + 1];
float pt6_x = kps[6*3];
float pt6_y = kps[6*3+1];
float center_up_x = (pt5_x + pt6_x) /2.0f ;
float center_up_y = (pt5_y + pt6_y) / 2.0f;
Point center_up = Point((int)center_up_x, (int)center_up_y);
float pt11_x = kps[11*3];
float pt11_y = kps[11*3 + 1];
float pt12_x = kps[12*3];
float pt12_y = kps[12*3 + 1];
float center_down_x = (pt11_x + pt12_x) / 2.0f;
float center_down_y = (pt11_y + pt12_y) / 2.0f;
Point center_down = Point((int)center_down_x, (int)center_down_y);
float right_angle_point_x = center_down_x;
float righ_angle_point_y = center_up_y;
Point right_angl_point = Point((int)right_angle_point_x, (int)righ_angle_point_y);
float a = abs(right_angle_point_x - center_up_x);
float b = abs(center_down_y - righ_angle_point_y);
float tan_value = a / b;
float Pi = acos(-1);
float angle = atan(tan_value) * 180.0f/ Pi;
string angel_label = "angle: " + to_string(angle);
putText(img, angel_label, Point(left, top-40), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0,0,255), 2);
if (angle > 60.0f || center_down_y <= center_up_y || (double)width/ height > 5.0f/3.0f) // 宽高比小于0.6为站立,大于5/3为跌倒
{
string fall_down_label = "person fall down!!!!";
putText(img, fall_down_label , Point(left, top-20), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0,0,255), 2);
printf("angel:%f width/height:%f\n",angle, (double)width/ height );
}
cv::line(img, center_up, center_down,
Scalar(0,0,255), 2, 8);
cv::line(img, center_up, right_angl_point,
Scalar(0,0,255), 2, 8);
cv::line(img, right_angl_point, center_down,
Scalar(0,0,255), 2, 8);
}
}
}
detect.h
#pragma onece
#include <iostream>
#include <memory>
#include <opencv2/opencv.hpp>
#include "utils.h"
#include <onnxruntime_cxx_api.h>
#include <numeric>
class Yolov8Onnx{
private:
template<typename T>
T VectorProduct(const std::vector<T>& v)
{
return std::accumulate(v.begin(), v.end(), 1, std::multiplies<T>());
}
int Preprocessing(const std::vector<cv::Mat>& SrcImgs,
std::vector<cv::Mat>& OutSrcImgs,
std::vector<cv::Vec4d>& params);
const int _netWidth = 640; //ONNX-net-input-width
const int _netHeight = 640; //ONNX-net-input-height
int _batchSize = 1; //if multi-batch,set this
bool _isDynamicShape = false;//onnx support dynamic shape
int _anchorLength=56;// pose一个框的信息56个数
float _classThreshold = 0.25;
float _nmsThrehold= 0.45;
//ONNXRUNTIME
Ort::Env _OrtEnv = Ort::Env(OrtLoggingLevel::ORT_LOGGING_LEVEL_ERROR, "Yolov5-Seg");
Ort::SessionOptions _OrtSessionOptions = Ort::SessionOptions();
Ort::Session* _OrtSession = nullptr;
Ort::MemoryInfo _OrtMemoryInfo;
std::shared_ptr<char> _inputName, _output_name0;
std::vector<char*> _inputNodeNames; //输入节点名
std::vector<char*> _outputNodeNames; // 输出节点名
size_t _inputNodesNum = 0; // 输入节点数
size_t _outputNodesNum = 0; // 输出节点数
ONNXTensorElementDataType _inputNodeDataType; //数据类型
ONNXTensorElementDataType _outputNodeDataType;
std::vector<int64_t> _inputTensorShape; // 输入张量shape
std::vector<int64_t> _outputTensorShape;
public:
Yolov8Onnx():_OrtMemoryInfo(Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtDeviceAllocator, OrtMemType::OrtMemTypeCPUOutput)) {};
~Yolov8Onnx() {};// delete _OrtMemoryInfo;
public:
/** \brief Read onnx-model
* \param[in] modelPath:onnx-model path
* \param[in] isCuda:if true,use Ort-GPU,else run it on cpu.
* \param[in] cudaID:if isCuda==true,run Ort-GPU on cudaID.
* \param[in] warmUp:if isCuda==true,warm up GPU-model.
*/
bool ReadModel(const std::string& modelPath, bool isCuda=false, int cudaId=0, bool warmUp=true);
/** \brief detect.
* \param[in] srcImg:a 3-channels image.
* \param[out] output:detection results of input image.
*/
bool OnnxDetect(cv::Mat& srcImg, std::vector<OutputPose>& output);
/** \brief detect,batch size= _batchSize
* \param[in] srcImg:A batch of images.
* \param[out] output:detection results of input images.
*/
bool OnnxBatchDetect(std::vector<cv::Mat>& srcImgs, std::vector<std::vector<OutputPose>>& output);
//public:
// std::vector<std::string> _className = {
// "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
// "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
// "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
// "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
// "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
// "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
// "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
// "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
// "hair drier", "toothbrush"
// };
};
detect.cpp
#include "detect.h"
using namespace std;
using namespace cv;
using namespace cv::dnn;
using namespace Ort;
bool Yolov8Onnx::ReadModel(const std::string &modelPath, bool isCuda, int cudaId, bool warmUp){
if (_batchSize < 1) _batchSize =1;
try
{
std::vector<std::string> available_providers = GetAvailableProviders();
auto cuda_available = std::find(available_providers.begin(), available_providers.end(), "CUDAExecutionProvider");
if (isCuda && (cuda_available == available_providers.end()))
{
std::cout << "Your ORT build without GPU. Change to CPU." << std::endl;
std::cout << "************* Infer model on CPU! *************" << std::endl;
}
else if (isCuda && (cuda_available != available_providers.end()))
{
std::cout << "************* Infer model on GPU! *************" << std::endl;
//#if ORT_API_VERSION < ORT_OLD_VISON
// OrtCUDAProviderOptions cudaOption;
// cudaOption.device_id = cudaID;
// _OrtSessionOptions.AppendExecutionProvider_CUDA(cudaOption);
//#else
// OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(_OrtSessionOptions, cudaID);
//#endif
}
else
{
std::cout << "************* Infer model on CPU! *************" << std::endl;
}
//
_OrtSessionOptions.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
#ifdef _WIN32
std::wstring model_path(modelPath.begin(), modelPath.end());
_OrtSession = new Ort::Session(_OrtEnv, model_path.c_str(), _OrtSessionOptions);
#else
_OrtSession = new Ort::Session(_OrtEnv, modelPath.c_str(), _OrtSessionOptions);
#endif
Ort::AllocatorWithDefaultOptions allocator;
//init input
_inputNodesNum = _OrtSession->GetInputCount();
#if ORT_API_VERSION < ORT_OLD_VISON
_inputName = _OrtSession->GetInputName(0, allocator);
_inputNodeNames.push_back(_inputName);
#else
_inputName = std::move(_OrtSession->GetInputNameAllocated(0, allocator));
_inputNodeNames.push_back(_inputName.get());
#endif
//cout << _inputNodeNames[0] << endl;
Ort::TypeInfo inputTypeInfo = _OrtSession->GetInputTypeInfo(0);
auto input_tensor_info = inputTypeInfo.GetTensorTypeAndShapeInfo();
_inputNodeDataType = input_tensor_info.GetElementType();
_inputTensorShape = input_tensor_info.GetShape();
if (_inputTensorShape[0] == -1)
{
_isDynamicShape = true;
_inputTensorShape[0] = _batchSize;
}
if (_inputTensorShape[2] == -1 || _inputTensorShape[3] == -1) {
_isDynamicShape = true;
_inputTensorShape[2] = _netHeight;
_inputTensorShape[3] = _netWidth;
}
//init output
_outputNodesNum = _OrtSession->GetOutputCount();
#if ORT_API_VERSION < ORT_OLD_VISON
_output_name0 = _OrtSession->GetOutputName(0, allocator);
_outputNodeNames.push_back(_output_name0);
#else
_output_name0 = std::move(_OrtSession->GetOutputNameAllocated(0, allocator));
_outputNodeNames.push_back(_output_name0.get());
#endif
Ort::TypeInfo type_info_output0(nullptr);
type_info_output0 = _OrtSession->GetOutputTypeInfo(0); //output0
auto tensor_info_output0 = type_info_output0.GetTensorTypeAndShapeInfo();
_outputNodeDataType = tensor_info_output0.GetElementType();
_outputTensorShape = tensor_info_output0.GetShape();
//_outputMaskNodeDataType = tensor_info_output1.GetElementType(); //the same as output0
//_outputMaskTensorShape = tensor_info_output1.GetShape();
//if (_outputTensorShape[0] == -1)
//{
// _outputTensorShape[0] = _batchSize;
// _outputMaskTensorShape[0] = _batchSize;
//}
//if (_outputMaskTensorShape[2] == -1) {
// //size_t ouput_rows = 0;
// //for (int i = 0; i < _strideSize; ++i) {
// // ouput_rows += 3 * (_netWidth / _netStride[i]) * _netHeight / _netStride[i];
// //}
// //_outputTensorShape[1] = ouput_rows;
// _outputMaskTensorShape[2] = _segHeight;
// _outputMaskTensorShape[3] = _segWidth;
//}
//warm up
if (isCuda && warmUp) {
//draw run
cout << "Start warming up" << endl;
size_t input_tensor_length = VectorProduct(_inputTensorShape);
float* temp = new float[input_tensor_length];
std::vector<Ort::Value> input_tensors;
std::vector<Ort::Value> output_tensors;
input_tensors.push_back(Ort::Value::CreateTensor<float>(
_OrtMemoryInfo, temp, input_tensor_length, _inputTensorShape.data(),
_inputTensorShape.size()));
for (int i = 0; i < 3; ++i) {
output_tensors = _OrtSession->Run(Ort::RunOptions{ nullptr },
_inputNodeNames.data(),
input_tensors.data(),
_inputNodeNames.size(),
_outputNodeNames.data(),
_outputNodeNames.size());
}
delete[]temp;
}
}
catch (const std::exception&) {
return false;
}
return true;
}
int Yolov8Onnx::Preprocessing(const std::vector<cv::Mat> &SrcImgs,
std::vector<cv::Mat> &OutSrcImgs,
std::vector<cv::Vec4d> ¶ms){
OutSrcImgs.clear();
Size input_size = Size(_netWidth, _netHeight);
// 信封处理
for (size_t i=0; i<SrcImgs.size(); ++i){
Mat temp_img = SrcImgs[i];
Vec4d temp_param = {1,1,0,0};
if (temp_img.size() != input_size){
Mat borderImg;
LetterBox(temp_img, borderImg, temp_param, input_size, false, false, true, 32);
OutSrcImgs.push_back(borderImg);
params.push_back(temp_param);
}
else {
OutSrcImgs.push_back(temp_img);
params.push_back(temp_param);
}
}
int lack_num = _batchSize - SrcImgs.size();
if (lack_num > 0){
Mat temp_img = Mat::zeros(input_size, CV_8UC3);
Vec4d temp_param = {1,1,0,0};
OutSrcImgs.push_back(temp_img);
params.push_back(temp_param);
}
return 0;
}
bool Yolov8Onnx::OnnxBatchDetect(std::vector<cv::Mat> &srcImgs, std::vector<std::vector<OutputPose>> &output)
{
vector<Vec4d> params;
vector<Mat> input_images;
cv::Size input_size(_netWidth, _netHeight);
//preprocessing (信封处理)
Preprocessing(srcImgs, input_images, params);
// [0~255] --> [0~1]; BGR2RGB
Mat blob = cv::dnn::blobFromImages(input_images, 1 / 255.0, input_size, Scalar(0,0,0), true, false);
// 前向传播得到推理结果
int64_t input_tensor_length = VectorProduct(_inputTensorShape);// ?
std::vector<Ort::Value> input_tensors;
std::vector<Ort::Value> output_tensors;
input_tensors.push_back(Ort::Value::CreateTensor<float>(_OrtMemoryInfo, (float*)blob.data,
input_tensor_length, _inputTensorShape.data(),
_inputTensorShape.size()));
output_tensors = _OrtSession->Run(Ort::RunOptions{ nullptr },
_inputNodeNames.data(),
input_tensors.data(),
_inputNodeNames.size(),
_outputNodeNames.data(),
_outputNodeNames.size()
);
//post-process
float* all_data = output_tensors[0].GetTensorMutableData<float>(); // 第一张图片的输出
_outputTensorShape = output_tensors[0].GetTensorTypeAndShapeInfo().GetShape(); // 一张图片输出的维度信息 [1, 84, 8400]
int64_t one_output_length = VectorProduct(_outputTensorShape) / _outputTensorShape[0]; // 一张图片输出所占内存长度 8400*84
for (int img_index = 0; img_index < srcImgs.size(); ++img_index){
Mat output0 = Mat(Size((int)_outputTensorShape[2], (int)_outputTensorShape[1]), CV_32F, all_data).t(); // [1, 56 ,8400] -> [1, 8400, 56]
all_data += one_output_length; //指针指向下一个图片的地址
float* pdata = (float*)output0.data; // [classid,x,y,w,h,x,y,...21个点]
int rows = output0.rows; // 预测框的数量 8400
// 一张图片的预测框
vector<float> confidences;
vector<Rect> boxes;
vector<int> labels;
vector<vector<float>> kpss;
for (int r=0; r<rows; ++r){
// 得到人类别概率
auto kps_ptr = pdata + 5;
// 预测框坐标映射到原图上
float score = pdata[4];
if (score > _classThreshold){
// rect [x,y,w,h]
float x = (pdata[0] - params[img_index][2]) / params[img_index][0]; //x
float y = (pdata[1] - params[img_index][3]) / params[img_index][1]; //y
float w = pdata[2] / params[img_index][0]; //w
float h = pdata[3] / params[img_index][1]; //h
int left = MAX(int(x - 0.5 *w +0.5), 0);
int top = MAX(int(y - 0.5*h + 0.5), 0);
std::vector<float> kps;
for (int k=0; k< 17; k++){
float kps_x = (*(kps_ptr + 3*k) - params[img_index][2]) / params[img_index][0];
float kps_y = (*(kps_ptr + 3*k + 1) - params[img_index][3]) / params[img_index][1];
float kps_s = *(kps_ptr + 3*k +2);
// cout << *(kps_ptr + 3*k) << endl;
kps.push_back(kps_x);
kps.push_back(kps_y);
kps.push_back(kps_s);
}
confidences.push_back(score);
labels.push_back(0);
kpss.push_back(kps);
boxes.push_back(Rect(left, top, int(w + 0.5), int(h + 0.5)));
}
pdata += _anchorLength; //下一个预测框
}
// 对一张图的预测框执行NMS处理
vector<int> nms_result;
cv::dnn::NMSBoxes(boxes, confidences, _classThreshold, _nmsThrehold, nms_result); // 还需要classThreshold?
// 对一张图片:依据NMS处理得到的索引,得到类别id、confidence、box,并置于结构体OutputDet的容器中
vector<OutputPose> temp_output;
for (size_t i=0; i<nms_result.size(); ++i){
int idx = nms_result[i];
OutputPose result;
result.confidence = confidences[idx];
result.box = boxes[idx];
result.label = labels[idx];
result.kps = kpss[idx];
temp_output.push_back(result);
}
output.push_back(temp_output); // 多张图片的输出;添加一张图片的输出置于此容器中
}
if (output.size())
return true;
else
return false;
}
bool Yolov8Onnx::OnnxDetect(cv::Mat &srcImg, std::vector<OutputPose> &output){
vector<Mat> input_data = {srcImg};
vector<vector<OutputPose>> temp_output;
if(OnnxBatchDetect(input_data, temp_output)){
output = temp_output[0];
return true;
}
else return false;
}
main.cpp
#include <iostream>
#include <opencv2/opencv.hpp>
#include "detect.h"
#include <sys/time.h>
#include <vector>
using namespace std;
using namespace cv;
using namespace cv::dnn;
const std::vector<std::vector<unsigned int>> KPS_COLORS =
{{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{51, 153, 255},
{51, 153, 255},
{51, 153, 255},
{51, 153, 255},
{51, 153, 255},
{51, 153, 255}};
const std::vector<std::vector<unsigned int>> SKELETON = {{16, 14},
{14, 12},
{17, 15},
{15, 13},
{12, 13},
{6, 12},
{7, 13},
{6, 7},
{6, 8},
{7, 9},
{8, 10},
{9, 11},
{2, 3},
{1, 2},
{1, 3},
{2, 4},
{3, 5},
{4, 6},
{5, 7}};
const std::vector<std::vector<unsigned int>> LIMB_COLORS = {{51, 153, 255},
{51, 153, 255},
{51, 153, 255},
{51, 153, 255},
{255, 51, 255},
{255, 51, 255},
{255, 51, 255},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{255, 128, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0},
{0, 255, 0}};
int main(){
// 读取模型
string detect_model_path = "/home/jason/PycharmProjects/pytorch_learn/yolo/ultralytics-main-yolov8/yolov8n-pose.onnx";
Yolov8Onnx yolov8;
if (yolov8.ReadModel(detect_model_path))
cout << "read Net ok!\n";
else {
return -1;
}
VideoCapture capture;
capture.open("/home/jason/work/01-img/fall-down3.mp4");
if (capture.isOpened())
cout << "read video ok!\n";
else
cout << "read video err!\n";
int width = capture.get(CAP_PROP_FRAME_WIDTH);
int height = capture.get(CAP_PROP_FRAME_HEIGHT);
Size size1 = Size(width, height);
double delay = 1000/capture.get(CAP_PROP_FPS);
int frame_pos = 0;
int frame_all = capture.get(CAP_PROP_FRAME_COUNT);
VideoWriter writer;
writer.open("/home/jason/work/01-img/fall-down-result.mp4", VideoWriter::fourcc('m', 'p', '4', 'v'),
delay,size1);
Mat frame;
struct timeval t1, t2;
double timeuse;
while (1) {
//
capture>>frame;
if (frame_pos == frame_all-1) break;
// YOLOv8检测
vector<OutputPose> result;
gettimeofday(&t1, NULL);
bool find = yolov8.OnnxDetect(frame, result);
gettimeofday(&t2, NULL);
frame_pos+=1;
printf("%d/%d:find %d person!\n",frame_pos, frame_all, (int)result.size());
if(find)
{
DrawPred(frame, result, SKELETON, KPS_COLORS, LIMB_COLORS);
}
else {
cout << "not find!\n";
}
timeuse = (t2.tv_sec - t1.tv_sec) + (double)(t2.tv_usec - t1.tv_usec)/1000000;
timeuse *= 1000;
string label = "TimeUse: " + to_string(timeuse);
putText(frame, label, Point(30,30), FONT_HERSHEY_SIMPLEX, 1, Scalar(0,0,255), 2, 8);
writer << frame;
imshow("yolov8n-pose", frame);
if(waitKey(1)=='q') break;
}
capture.release();
// writer.release();
return 0;
}
CmakeList.txt
cmake_minimum_required(VERSION 3.5)
project(05-YOLOv8-pose-onnruntime LANGUAGES CXX)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
include_directories("/home/jason/下载/onnxruntime-linux-x64-1.14.1/include")
#link_directories("/home/jason/下载/onnxruntime-linux-x64-1.14.1/lib")
include_directories(./include)
aux_source_directory(./src SOURCES)
find_package(OpenCV 4 REQUIRED)
add_executable(${PROJECT_NAME} ${SOURCES})
target_link_libraries(${PROJECT_NAME} ${OpenCV_LIBS})
target_link_libraries(${PROJECT_NAME} "/home/jason/下载/onnxruntime-linux-x64-1.14.1/lib/libonnxruntime.so")















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









