







C++程序编译的过程:预处理->编译(优化、汇编)->链接
预处理指令主要有以下三种:
- 包含头文件:
#includee - 宏定义:
#define(定义宏)、#undef(删除宏)。 - 条件编译:
#ifdef、#ifndef。
- 包含头文件
#include包含头文件有两种方式:#include <文件名>:直接从编译器自带的函数库目录中寻找文件。#include"文件名":先从自定义的目录中寻找文件,如果找不到,再从编译器自带的函数库目录
中寻找。
#include 也包含其它的文件,如:*.h、*.cpp或其它的文件。
C++98标准后的头文件:
- C的标准库:老版本的有
.h后缀;新版本没有.h的后缀,增加了字符c的前缀。例如:老版本是
<stdio.h>,新版本是<cstdio>,新老版本库中的内容是一样的。在程序中,不指定std命名空
间也能使用库中的内容。 - C++的标准库:老版本的有
.h后缀;新版本没有.h的后缀。例如:老版本是<iostream.h>,新
版本是<iostream>,老版本已弃用,只能用新版本。在程序中,必须指定std命名空间才能使用库中的内容。
注意:用户自定义的头文件还是用.h为后缀。
- 宏定义指令
无参数的宏:#define 宏名 宏内容
有参数的宏:#define MAX(x,y) ((x)>(y) ? (x) : (y))
编译的时候,编译器把程序中的宏名用宏内容替换,是为宏展开(宏替换)。
宏可以只有宏名,没有后面的宏内容
在C++中,内联函数可代替有参数的宏,效果更好。
C++中常用的宏:- 当前源代码文件名:
_FILE_ - 当前源代码函数名:
_FUNCTION_ - 当前源代码行号:
_LINE_ - 编译的日期:
_DATE_ - 编译的时间:
_TIME_ - 编译的时间戳:
_TIMESTAMP__ - 当用C++编译程序时,宏
_cplusplus就会被定义。
- 当前源代码文件名:
#include<iostream>
#include<algorithm>
using namespace std;
#define BH 3
#define MESSAGE "我是一只小小鸟。\n"
int main(){
cout<<"亲爱的"<<BH<<"号:"<<MESSAGE<<endl;
}
- 条件编译
最常用的两种:#ifdef、#ifndefif #define if not #definee
#ifdef 宏名
程序段一
#elsee
程序段二
#endif
含义:如果#ifdef后面的宏名已存在,则使用程序段一,否则使用程序段二。
#ifndef 宏名
程序段一
#else
程序段二
#endif
含义:如果#ifndef后面的宏名不存在,则使用程序段一,否则使用程序段二.
下面定义一个跨平台的C++程序
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
//不同操作系统的宏:__linux__,__WIN32
#ifdef _WIN32
cout<<"这是windows系统。\n";
typedef long long int64;
#else
cout<<"这不是windows系统。\n";
typedef long int64;
#endif
int64 a=10;
cout<<"a="<<a<<endl;
}
- 解决头文件中代码重复包含的问题
在C/C++中,在使用预编译指令#include的时候,为了防止头文件被重复包含,有两种方式。第一种:用#ifndef指令。
#ifndef _GIRL_
#define _GIRL_
//代码内容。
#endif
第二种:把#pragma once指令放在文件的开头。
#ifndef方式受C/C++语言标准的支持,不受编译器的任何限制;而#pragma once方式有些编译
器不支持。
#ifndef可以针对文件中的部分代码;而#pragma once只能针对整个文件。
例如:两个头文件boy.h和girl.h
boy.h
#pragma once
#include<iostream>
using namespace std;
#include "girl.h"
class CGirl;
class CBoy {
public:
string m_name;
CGirl* m_girl;//快男的女朋友
};
girl.h
#pragma once
#include<iostream>
using namespace std;
#include "boy.h"
class CBoy;//将快乐男声类的声明前置
class CGirl {
public:
string m_name;
CBoy* m_boy;//超女的男朋友
};
demo.cpp
#include<iostream>
#include<algorithm>
using namespace std;
#include "girl.h"
#include "boy.h"
int main() {
CGirl g;
CBoy b;
g.m_name = "西施";
b.m_name = "吕布";
}
编译和链接
- 源代码的组织
头文件(*.h) :#include头文件、函数的声明、结构体的声明、类的声明、模板的声明、内联函数、#define和const定义的常量等。
心
源文件(*.cpp)︰函数的定义、类的定义、模板具体化的定义。
**主程序(main函数所在的程序)**∶主程序负责实现框架和核心流程,把需要用到的头文件用#include包含进来。
例如这个:iostream是系统自带的,而girls.h和tolls.h是自己写的.三个源文件,demo01.cpp,girls.cpp,tools.cpp.
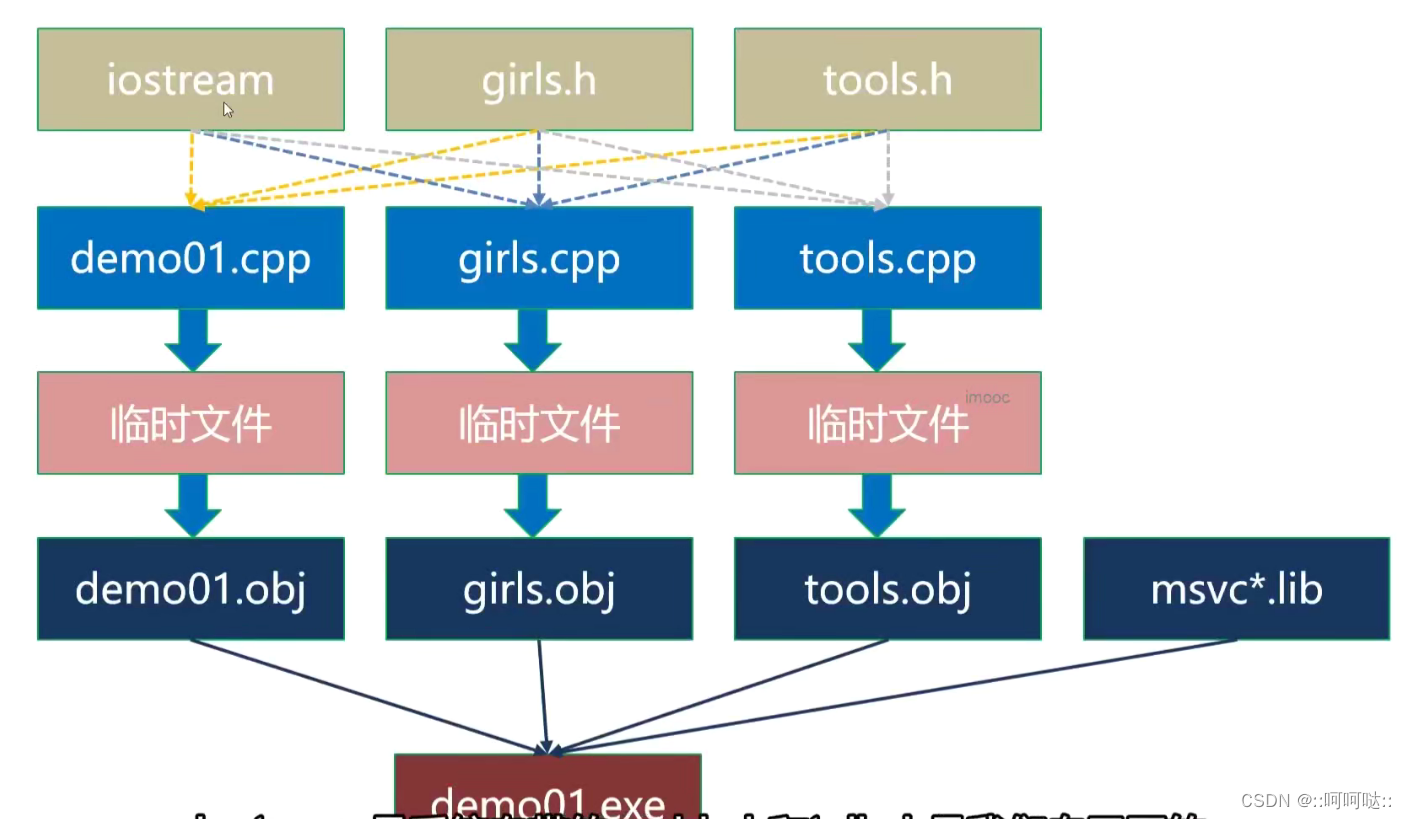
有三大步骤:编译预处理,编译和链接.
- 编译预处理是生产临时文件

- 编译
主要是讲预处理生成的临时文件,经过词法分析,语法分析,语义分析以及优化和汇编后生成二进制的目标文件 - 链接
将编译后的目标文件,以及它们所需要的库文件链接在一起形成一个整体.
更多细节
- 分开编译的好处:每次只编译修改过的源文件,然后再链接,效率最高。
- 编译单个
*.cpp文件的时候,必须要让编译器知道名称的存在,否则会出现找不到标识符的错
误。 - 编译单个
*.cpp文件的时候,编译器只需要知道名称的存在,不会把它们的定义起编译。 - 如果函数和类的定义不存在,编译不会报错,但链接会出现无法解析的外部命令。
- 链接的时候,变量、函数和类的定义只能有一个,否则会出现重定义的错误。(如果把变量和函数和类的定义放在
*.h文件中,*.h会被多次包含,链接前可能存在多个副本;如果放在*.cpp文件中,*.cpp文件不会被包含,只会被编译一次,链接前只存在一个版本) - 把变量、函数和类的定义放在
*.h中是不规范的做法,如果*.h被多个*.cpp包含,会出现重定
义。 - 用
#include包含*.cpp也是不规范的做法,原理同上. - 尽可能不使用全局变量,如果一定要用,要在
*.h文件中声明(需要加extern 关键字),在*.cpp文件中定义。 - 全局的
const常量在头文件中和定义(const常量仅在单个文件内有效)。 *.h重复包含的处理方法只对单个的*.cpp文件有效,不是整个项目。- 函数模板和类模板的声明和定义可以分开书写,但它们的定义并不是真实的定义,只能放在
*.h文件中;函数模板和类模板的具体化版本的代码是真实的定义,所以放在*.cpp文件中。
这章的代码主要包含girls.h,girls.cpp,tools.h,tools.cpp和主程序demo.cpp.
.h文件主要是 函数的定义还有全局变量的定义,.cpp文件是函数的具体实现.对于全局变量我们需要在.h中声明(需要加extera),然后在.cpp中定义,
代码:girls.h
#pragma once
#include<iostream>
#include "tools.h"
using namespace std;
void print(int no, string str);
extern int aa;
girls.cpp
#include "girls.h"
int aa = 3;
void print(int no, string str) {
cout << "亲爱的" << no << "号:" << str << endl;
}
tools.h
#pragma once
#include<iostream>
#include "girls.h"
using namespace std;
int max(int a, int b);
int min(int a, int b);
extern int bb;
tools.cpp
#include "tools.h"
int bb = 8;
int max(int a, int b) {
return a > b ? a : b;
}
int min(int a, int b) {
return a < b ? a : b;
}
demo.cpp
#include "tools.h"
#include "girls.h"
int main() {
cout << "max(5,8)=" << max(5, 8) << endl;
cout << "min(5,8)=" << min(5, 8) << endl;
print(3, "我是一只小小鸟。");
cout << "aa=" << aa << endl;
cout << "bb=" << bb << endl;
}
命名空间
在实际开发中,较大型的项目会使用大量的全局名字,如类、函数、模板、变量等,很容易出现名字冲突的情况。
命名空间分割了全局空间,每个命名空间是一个作用域,防止名字冲突。
-
语法
创建命名空间 namespace 命名空间的名字 { //类,函数,模板,变量的声明和定义 } 创建命名空间的别名: namespace 别名=原名;例如:
namespace aa { int ab = 1;//全局变量 void func1();//全局变量的声明 class A1 { public: void show();//类的成员函数 }; void func1() {//全局函数的定义 cout << "调用了func()函数\n"; } void A1::show() {//类成员函数的类外实现 cout << "调用了A1::show()函数.\n"; } } -
使用命名空间
在同一命名空间内的名字可以直接访问,该命名空间之外的代码则必须明确指出命名空间。
第一种方法:运算符::
语法命名空间::名字,但是使用起来比较繁琐#include<iostream> #include<algorithm> using namespace std; namespace aa { int ab = 1;//全局变量 void func1();//全局变量的声明 class A1 { public: void show();//类的成员函数 }; void func1() {//全局函数的定义 cout << "调用了func()函数\n"; } void A1::show() {//类成员函数的类外实现 cout << "调用了A1::show()函数.\n"; } } int main() { cout << "ab=" << aa::ab << endl; aa::func1(); aa::A1 a1; a1.show(); }第二种方法:
using声明
语法:using 命名空间::名字,用using声名后,就可以进行直接使用名称,如果该声明区域有相同的名字,就会报错.#include<iostream> #include<algorithm> using namespace std; namespace aa { int ab = 1;//全局变量 void func1();//全局变量的声明 class A1 { public: void show();//类的成员函数 }; void func1() {//全局函数的定义 cout << "调用了func()函数\n"; } void A1::show() {//类成员函数的类外实现 cout << "调用了A1::show()函数.\n"; } } int main() { using aa::ab; using aa::A1; using aa::func1; cout << "ab=" << ab << endl; func1(); A1 a1; a1.show(); }第三种方法:
using namespace 名字;类似于using namespace std;
语法:using namesapce 命名空间.using编译指令将使整个命名空间中的名字可用。如果声明区域有相同的名字,局部版本将隐藏命名空间中的名字,不过,可以使用域名解析符使用命名空间中的名称。#include<iostream> #include<algorithm> using namespace std; namespace aa { int ab = 1;//全局变量 void func1();//全局变量的声明 class A1 { public: void show();//类的成员函数 }; void func1() {//全局函数的定义 cout << "调用了func()函数\n"; } void A1::show() {//类成员函数的类外实现 cout << "调用了A1::show()函数.\n"; } } int main() { using namespace aa; cout << "ab=" << ab << endl; func1(); A1 a1; a1.show(); }注意如果在主函数中在定义一个和命名空间中相同的变量,该变量将覆盖命名空间中的变量.
-
注意事项
-
命名空间是全局的,可以分布在多个文件中.
-
命名空间可以嵌套。
-
在命名空间中声明变量,而不是使用外部全局变量和静态全局变量。
-
对于using声明,首选将其作用域设置为局部而不是全局。
-
不要在头文件中使用using编译指令,如果非要使用,应将它放在所有的#include之后。-
-
匿名的命名空间,从创建的位置到文件结束有效。
C++数据转换-static_cast
C风格的类型转换很容易理解:
语法:(目标类型)表达式或目标类型(表达式);
C++认为C风格的类型转换过于松散,可能会带来隐患,不够安全。
C++推出了新的类型转换来替代C风格的类型转换,采用更严格的语法检查,降低使用风险。
C++新增了四个关键字static_cast、const_cast、reinterpret_cast和dynamic_cast用于支持C++风格的类型转换。
C++的类型转换只是语法上的解释,本质上与C风格的类型转换没什么不同,C语言做不到事情的C++也做不到。
语法:
static_cast<目标类型>(表达式);
const_cast<目标类型>(表达式);
reinterpret_cast<目标类型>(表达式);
dynamic_cast<目标类型>(表达式);
static_cast
- 用于内置数据类型之间的转换
除了语法不同,C和C++没有区别
对于指针类型转化:一般都是#include<iostream> #include<algorithm> using namespace std; int main() { int ii = 3; long ll = ii;//安全,可以隐式转换,不会出现警告 double dd = 1.23; long ll1 = dd;//可以隐式转化,但是会出现丢失数据的警告 long ll2 = (long)dd; //c风格,显式转换,不会警告 long ll3 = static_cast<long>(dd);//C++风格:显式转化,不会警告 cout << "ll1=" << ll1 << ",ll2=" << ll2 << ",ll3=" << ll3 << endl; }其他类型指针->void *指针->其他类型指针,他是需要借助void*指针的.#include<iostream> #include<algorithm> using namespace std; void func(void* ptr) {//其他类型指针->void *指针->其他类型指针 double* pp = static_cast<double*>(ptr); } int main(int argc,char* argv[]) { int ii = 10; //double* pd1 = ⅈ//错误,不能隐式转换 double* pd2 = (double*)ⅈ//C风格强制转换 //double* pd3=static_cast<double*>(&ii);//错误,static_cast不支持不同类型指针的转换 void* pv = ⅈ double* pd4 = static_cast<double*>(pv);//static可以将void *转换成其他类型的指针 func(&ii); }
const_cast
static_cast不能丢掉指针(引用)的const和volitale属性,const_cast可以。
#include<iostream>
#include<algorithm>
using namespace std;
void func(int* ii) {
}
int main(int argc,char* argv[]) {
const int *aa = nullptr;
int* bb = (int*)aa;//C风格,强制转化,丢掉const限定符
int* cc = const_cast<int*>(aa);//C++风格,强制转换,丢掉const限定符
func(const_cast<int*>(aa));
}
reinterprt_cast
static_cast不能用于转换不同类型的指针(引用)(不考虑有继承关系的情况),reinterpret_cast
可以。
reinterpret_cast 的意思是重新解释,能够将一种对象类型转换为另一种,不管它们是否有关系。
语法: reinterpret_cast<目标类型>(表达式);
<目标类型>和(表达式)中必须有一个是指针(引用)类型。
reinterpret_cast不能丢掉(表达式)的const或volitale属性。
应用场景:
reinterpret_cast的第一种用途是改变指针(引用)的类型。reinterpret_cast的第二种用途是将指针(引用)转换成整型变量。整型与指针占用的字节数必须一致,否则转换可能损失精度。reinterpret_cast的第三种用途是将一个整型变量转换成指针(引用)。
指针的转换static_cast需要借助void*,但是reinterpret_cast就不需要.#include<iostream> #include<algorithm> using namespace std; void func(void* ptr) {//其他类型指针->void *指针->其他类型指针 double* pp = static_cast<double*>(ptr); } int main(int argc,char* argv[]) { int ii = 10; //double* pd1 = ⅈ//错误,不能隐式转换 double* pd2 = (double*)ⅈ//C风格强制转换 double* pd3=reinterpret_cast<double*>(&ii);//错误,static_cast不支持不同类型指针的转换 void* pv = ⅈ double* pd4 = static_cast<double*>(pv);//static可以将void *转换成其他类型的指针 func(&ii); }
reinterpret_cast把指针在整数之间转换.
#include<iostream>
#include<algorithm>
using namespace std;
void func(void* ptr) {
int ii = reinterpret_cast<int>(ptr);
cout << "ii=" << ii << endl;
}
int main(int argc,char* argv[]) {
int ii = 10;
func(reinterpret_cast<void*>(ii));
}















 3499
3499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









