








随处可见的红黑树
一般会用到[key,value]。
例如github中这个例子,第一个是访问网站,第二个是访问次数,但是这个不是静态的,这有个动态排序,并且当我们需要让相应的访问次数加1的时候,我们用红黑树查找的时候会比较快,所以用红黑树表示这个结构比较号。
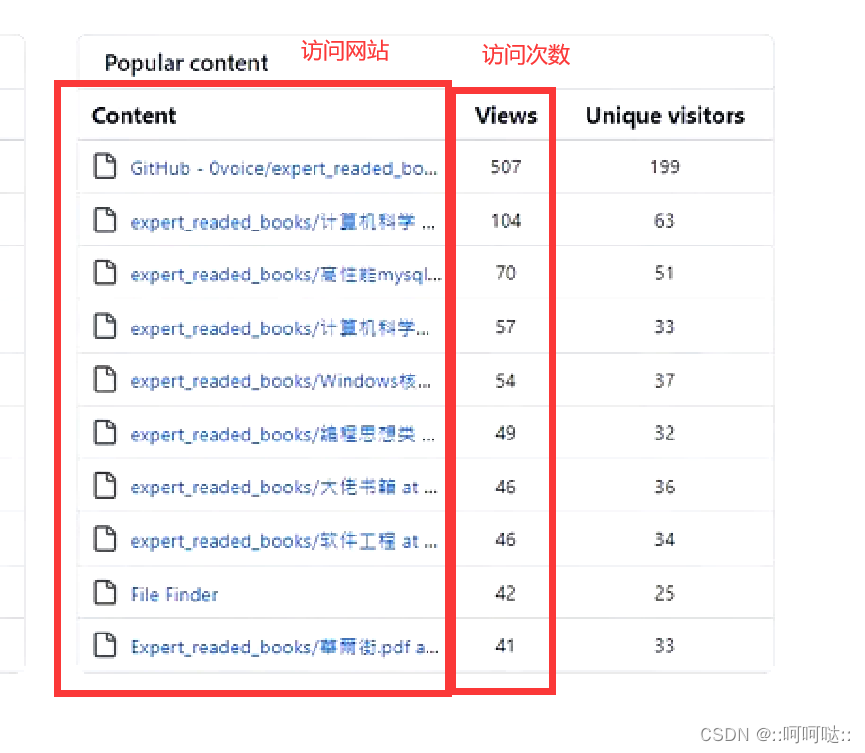
所以红黑树普遍用于强查找过程。对于这种强查找的过程:我们普遍用rbtree,hash,b/b+ tree,或者跳表。
红黑树的性质和定义
红黑树的性质:
1.每个结点是红的或者黑的2.根结点是黑的
3.每个叶子结点是黑的
4.如果一个结点是红的,则它的两个儿子都是黑的(红红不相邻)
5.对每个结点,从该结点到其子孙结点的所有路径上的包含相同数目的黑结点

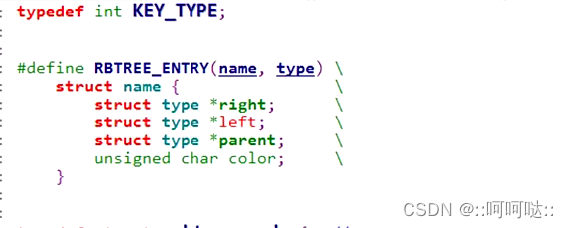

对于一个红黑树的定义:注意这个nil指的是叶子节点,也就是那个隐藏的那个黑节点。
typedef int KEY_TYPE;
typedef struct _rbtree_node {
unsigned char color;
struct _rbtree_node *right;
struct _rbtree_node *left;
struct _rbtree_node *parent;
KEY_TYPE key;
void *value;
} rbtree_node;
typedef struct _rbtree {
rbtree_node *root;//根节点
rbtree_node *nil;//叶子节点
} rbtree;
红黑树的左右旋
对于红黑树的旋转:
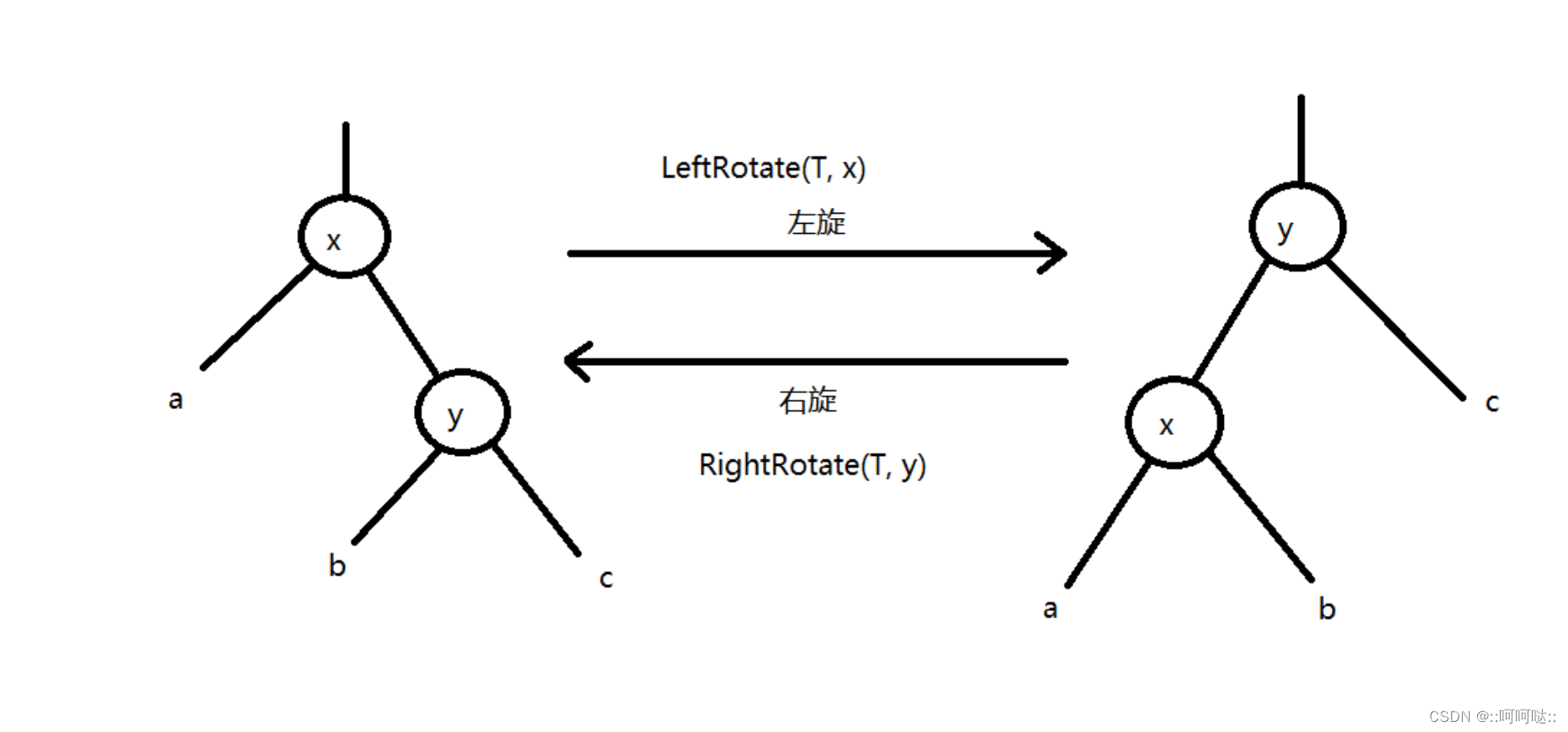
这里我们需要改变6根指针:
code:
这里主要需要判断的是x的parent是不是根节点。如果是的话,那么之间让根节点root指向y就行。

void rbtree_left_rotate(rbtree *T, rbtree_node *x) {
rbtree_node *y = x->right; // x --> y , y --> x, right --> left, left --> right
x->right = y->left; //1 1
if (y->left != T->nil) { //1 2
y->left->parent = x;
}
y->parent = x->parent; //1 3
if (x->parent == T->nil) { //1 4
T->root = y;
} else if (x == x->parent->left) {
x->parent->left = y;
} else {
x->parent->right = y;
}
y->left = x; //1 5
x->parent = y; //1 6
}
右旋:
也就是上面的代码x改成y,right改成left。
void rbtree_right_rotate(rbtree *T, rbtree_node *y) {
rbtree_node *x = y->left;
y->left = x->right;
if (x->right != T->nil) {
x->right->parent = y;
}
x->parent = y->parent;
if (y->parent == T->nil) {
T->root = x;
} else if (y == y->parent->right) {
y->parent->right = x;
} else {
y->parent->left = x;
}
x->right = y;
y->parent = x;
}
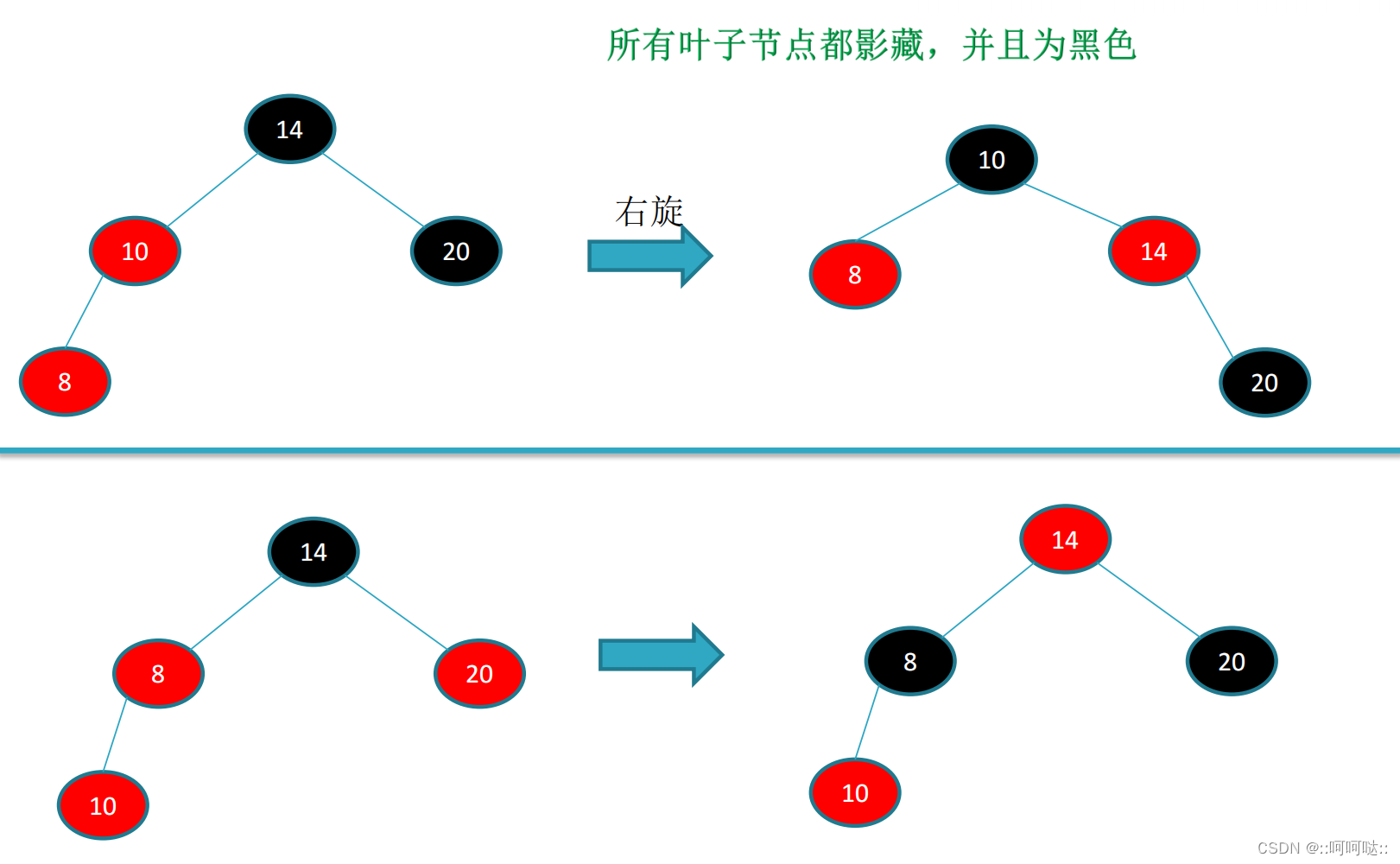
红黑树的插入
对于插入的时候我们都是一插到底,一直插到根节点。并且插入的节点定义为红色,然后再进行颜色的调整。而且它的父节点也是红色,因为原本的节点他的两个根是黑色,所以,这个父节点应该是红色。
因为红黑树在插入节点之前他已经是一个红黑树了。所以插入红色,不改变黑高的性质。
插入code:
void rbtree_insert(rbtree *T, rbtree_node *z) {
rbtree_node *y = T->nil;
rbtree_node *x = T->root;
while (x != T->nil) {
y = x;//y就是x的parent
if (z->key < x->key) {
x = x->left;
} else if (z->key > x->key) {
x = x->right;
} else { //Exist
return ;
}
}
z->parent = y;
if (y == T->nil) {
T->root = z;
} else if (z->key < y->key) {
y->left = z;
} else {
y->right = z;
}
z->left = T->nil;
z->right = T->nil;
z->color = RED;
rbtree_insert_fixup(T, z);
}
调整颜色,让其满足性质:

我们发现如果定义为红色之后,满足性质1,2,3。不知道满不满足4,5.所以我们要让其先满足5在满足4。
还没调整前的情况:假设插入的节点是z,z的父节点是y
z是红色
z的父节点y也是红色
z的祖父节点是黑色
z的叔父节点是不确定
那么就两种情况:
- z的叔父节点是红色
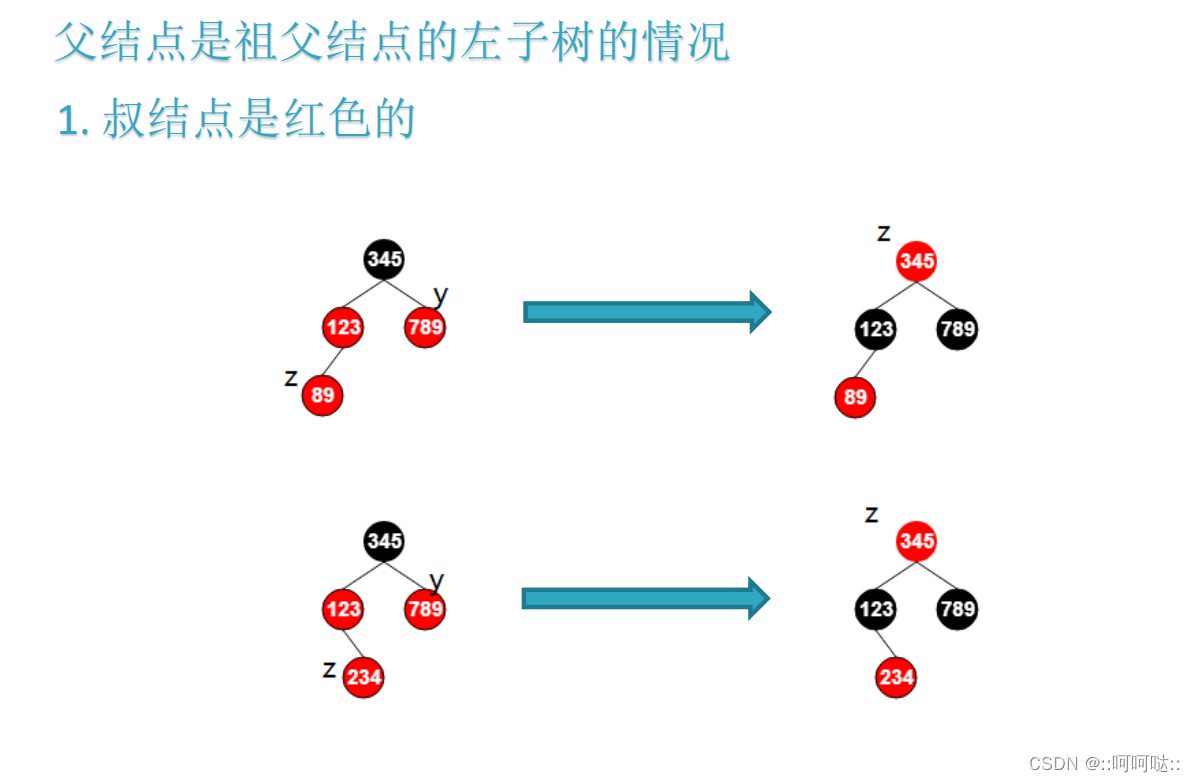
z->parent->color = BLACK;
y->color = BLACK;
z->parent->parent->color = RED;
z = z->parent->parent; //z --> RED,需要回溯
- z的叔父节点是黑色
这两种情况是调整出来的,因为你调整完之后需要回溯,因为你调整完之后它的祖父可能不满足所以z = z->parent->parent。然后这种情况是要旋转的。然后旋转之后的图是中间状态的图,然后旋转完之后就是改色。
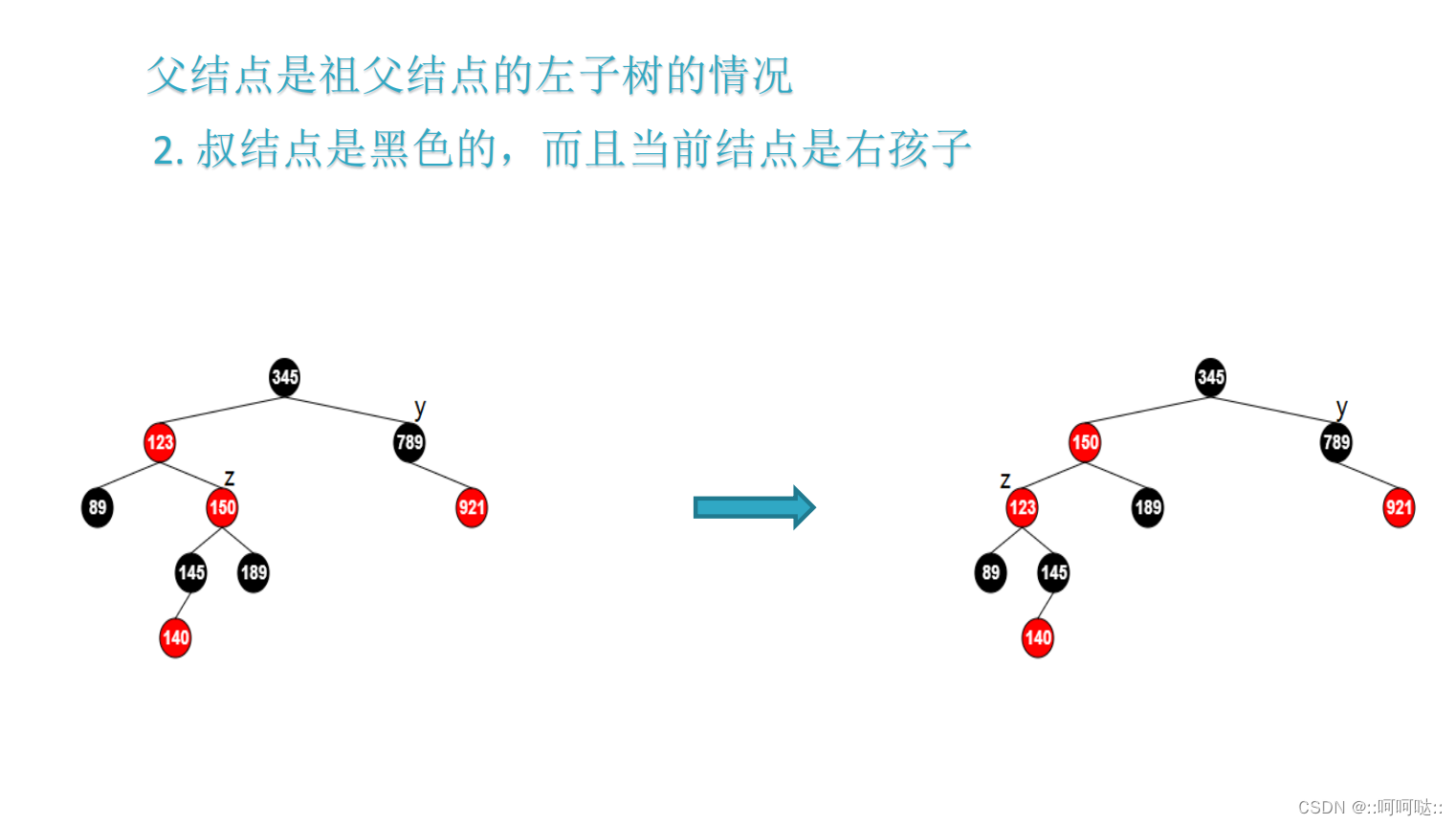
if (z == z->parent->right) {
z = z->parent;
rbtree_left_rotate(T, z);
}
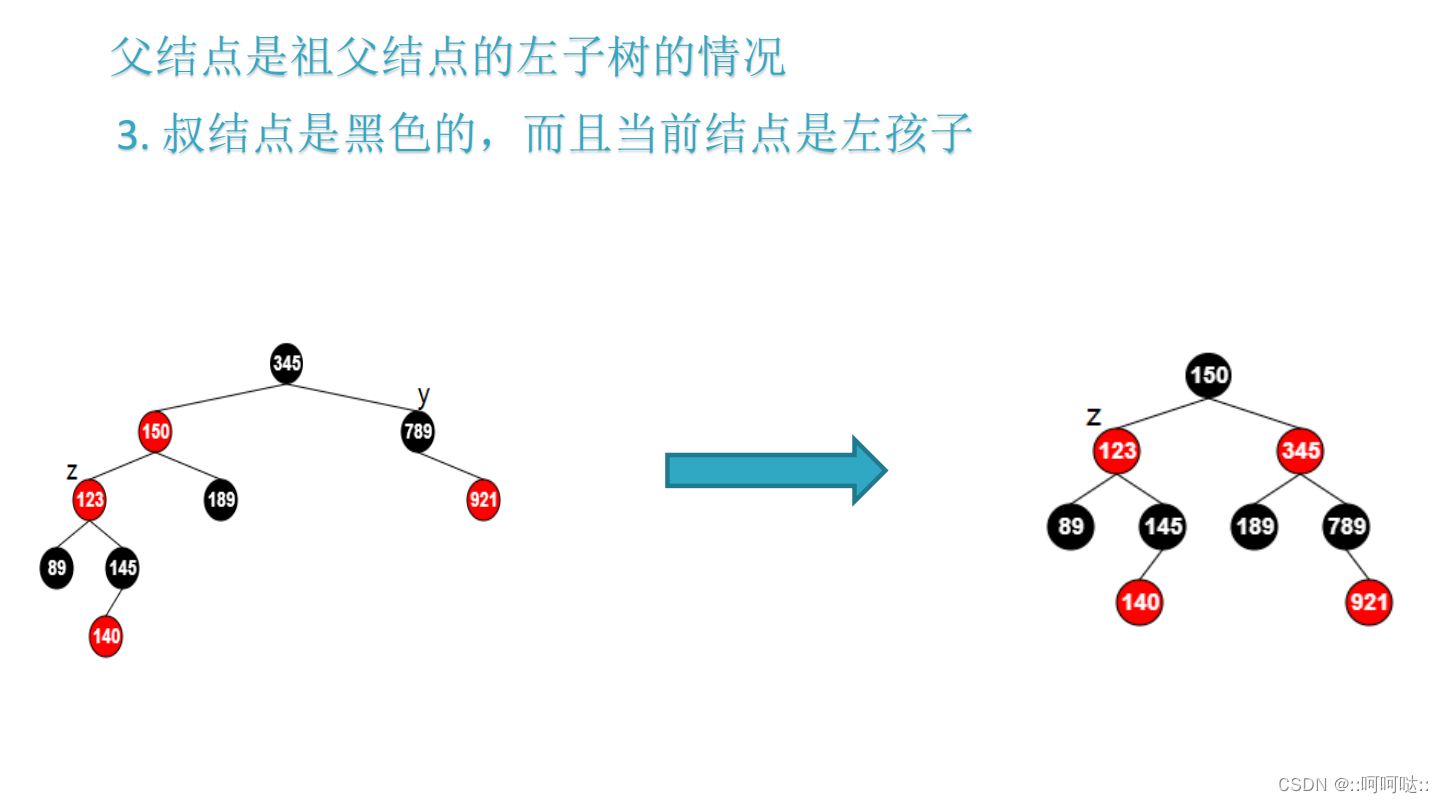
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_right_rotate(T, z->parent->parent);
然后叔父节点是黑色的完整代码就是这个:
if (z == z->parent->right) {
z = z->parent;
rbtree_left_rotate(T, z);
}
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_right_rotate(T, z->parent->parent);
然后父节点是祖父节点的左子树的情况代码就是这样的:
if (z->parent == z->parent->parent->left) {
rbtree_node *y = z->parent->parent->right;
if (y->color == RED) {
z->parent->color = BLACK;
y->color = BLACK;
z->parent->parent->color = RED;
z = z->parent->parent; //z --> RED,需要回溯
} else {
if (z == z->parent->right) {
z = z->parent;
rbtree_left_rotate(T, z);
}
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_right_rotate(T, z->parent->parent);
}
}
然后父节点是祖父节点的右子树的情况和上面差不多
完整代码就是:
void rbtree_insert_fixup(rbtree *T, rbtree_node *z) {
while (z->parent->color == RED) { //z ---> RED
if (z->parent == z->parent->parent->left) {
rbtree_node *y = z->parent->parent->right;
if (y->color == RED) {
z->parent->color = BLACK;
y->color = BLACK;
z->parent->parent->color = RED;
z = z->parent->parent; //z --> RED,需要回溯
} else {
if (z == z->parent->right) {
z = z->parent;
rbtree_left_rotate(T, z);
}
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_right_rotate(T, z->parent->parent);
}
}else {
rbtree_node *y = z->parent->parent->left;
if (y->color == RED) {
z->parent->color = BLACK;
y->color = BLACK;
z->parent->parent->color = RED;
z = z->parent->parent; //z --> RED
} else {
if (z == z->parent->left) {
z = z->parent;
rbtree_right_rotate(T, z);
}
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_left_rotate(T, z->parent->parent);
}
}
}
T->root->color = BLACK;
}
红黑树的删除
这个比较难,不需要掌握
完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define RED 1
#define BLACK 2
typedef int KEY_TYPE;
typedef struct _rbtree_node {
unsigned char color;
struct _rbtree_node *right;
struct _rbtree_node *left;
struct _rbtree_node *parent;
KEY_TYPE key;
void *value;
} rbtree_node;
typedef struct _rbtree {
rbtree_node *root;
rbtree_node *nil;
} rbtree;
rbtree_node *rbtree_mini(rbtree *T, rbtree_node *x) {
while (x->left != T->nil) {
x = x->left;
}
return x;
}
rbtree_node *rbtree_maxi(rbtree *T, rbtree_node *x) {
while (x->right != T->nil) {
x = x->right;
}
return x;
}
rbtree_node *rbtree_successor(rbtree *T, rbtree_node *x) {
rbtree_node *y = x->parent;
if (x->right != T->nil) {
return rbtree_mini(T, x->right);
}
while ((y != T->nil) && (x == y->right)) {
x = y;
y = y->parent;
}
return y;
}
void rbtree_left_rotate(rbtree *T, rbtree_node *x) {
rbtree_node *y = x->right; // x --> y , y --> x, right --> left, left --> right
x->right = y->left; //1 1
if (y->left != T->nil) { //1 2
y->left->parent = x;
}
y->parent = x->parent; //1 3
if (x->parent == T->nil) { //1 4
T->root = y;
} else if (x == x->parent->left) {
x->parent->left = y;
} else {
x->parent->right = y;
}
y->left = x; //1 5
x->parent = y; //1 6
}
void rbtree_right_rotate(rbtree *T, rbtree_node *y) {
rbtree_node *x = y->left;
y->left = x->right;
if (x->right != T->nil) {
x->right->parent = y;
}
x->parent = y->parent;
if (y->parent == T->nil) {
T->root = x;
} else if (y == y->parent->right) {
y->parent->right = x;
} else {
y->parent->left = x;
}
x->right = y;
y->parent = x;
}
void rbtree_insert_fixup(rbtree *T, rbtree_node *z) {
while (z->parent->color == RED) { //z ---> RED
if (z->parent == z->parent->parent->left) {
rbtree_node *y = z->parent->parent->right;
if (y->color == RED) {
z->parent->color = BLACK;
y->color = BLACK;
z->parent->parent->color = RED;
z = z->parent->parent; //z --> RED,需要回溯
} else {
if (z == z->parent->right) {
z = z->parent;
rbtree_left_rotate(T, z);
}
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_right_rotate(T, z->parent->parent);
}
}else {
rbtree_node *y = z->parent->parent->left;
if (y->color == RED) {
z->parent->color = BLACK;
y->color = BLACK;
z->parent->parent->color = RED;
z = z->parent->parent; //z --> RED
} else {
if (z == z->parent->left) {
z = z->parent;
rbtree_right_rotate(T, z);
}
z->parent->color = BLACK;
z->parent->parent->color = RED;
rbtree_left_rotate(T, z->parent->parent);
}
}
}
T->root->color = BLACK;
}
void rbtree_insert(rbtree *T, rbtree_node *z) {
rbtree_node *y = T->nil;
rbtree_node *x = T->root;
while (x != T->nil) {
y = x;//y就是x的parent
if (z->key < x->key) {
x = x->left;
} else if (z->key > x->key) {
x = x->right;
} else { //Exist
return ;
}
}
z->parent = y;
if (y == T->nil) {
T->root = z;
} else if (z->key < y->key) {
y->left = z;
} else {
y->right = z;
}
z->left = T->nil;
z->right = T->nil;
z->color = RED;
rbtree_insert_fixup(T, z);
}
void rbtree_delete_fixup(rbtree *T, rbtree_node *x) {
while ((x != T->root) && (x->color == BLACK)) {
if (x == x->parent->left) {
rbtree_node *w= x->parent->right;
if (w->color == RED) {
w->color = BLACK;
x->parent->color = RED;
rbtree_left_rotate(T, x->parent);
w = x->parent->right;
}
if ((w->left->color == BLACK) && (w->right->color == BLACK)) {
w->color = RED;
x = x->parent;
} else {
if (w->right->color == BLACK) {
w->left->color = BLACK;
w->color = RED;
rbtree_right_rotate(T, w);
w = x->parent->right;
}
w->color = x->parent->color;
x->parent->color = BLACK;
w->right->color = BLACK;
rbtree_left_rotate(T, x->parent);
x = T->root;
}
} else {
rbtree_node *w = x->parent->left;
if (w->color == RED) {
w->color = BLACK;
x->parent->color = RED;
rbtree_right_rotate(T, x->parent);
w = x->parent->left;
}
if ((w->left->color == BLACK) && (w->right->color == BLACK)) {
w->color = RED;
x = x->parent;
} else {
if (w->left->color == BLACK) {
w->right->color = BLACK;
w->color = RED;
rbtree_left_rotate(T, w);
w = x->parent->left;
}
w->color = x->parent->color;
x->parent->color = BLACK;
w->left->color = BLACK;
rbtree_right_rotate(T, x->parent);
x = T->root;
}
}
}
x->color = BLACK;
}
rbtree_node *rbtree_delete(rbtree *T, rbtree_node *z) {
rbtree_node *y = T->nil;
rbtree_node *x = T->nil;
if ((z->left == T->nil) || (z->right == T->nil)) {
y = z;
} else {
y = rbtree_successor(T, z);
}
if (y->left != T->nil) {
x = y->left;
} else if (y->right != T->nil) {
x = y->right;
}
x->parent = y->parent;
if (y->parent == T->nil) {
T->root = x;
} else if (y == y->parent->left) {
y->parent->left = x;
} else {
y->parent->right = x;
}
if (y != z) {
z->key = y->key;
z->value = y->value;
}
if (y->color == BLACK) {
rbtree_delete_fixup(T, x);
}
return y;
}
rbtree_node *rbtree_search(rbtree *T, KEY_TYPE key) {
rbtree_node *node = T->root;
while (node != T->nil) {
if (key < node->key) {
node = node->left;
} else if (key > node->key) {
node = node->right;
} else {
return node;
}
}
return T->nil;
}
void rbtree_traversal(rbtree *T, rbtree_node *node) {
if (node != T->nil) {
rbtree_traversal(T, node->left);
printf("key:%d, color:%d\n", node->key, node->color);
rbtree_traversal(T, node->right);
}
}
int main() {
int keyArray[20] = {24,25,13,35,23, 26,67,47,38,98, 20,19,17,49,12, 21,9,18,14,15};
rbtree *T = (rbtree *)malloc(sizeof(rbtree));
if (T == NULL) {
printf("malloc failed\n");
return -1;
}
T->nil = (rbtree_node*)malloc(sizeof(rbtree_node));
T->nil->color = BLACK;
T->root = T->nil;
rbtree_node *node = T->nil;
int i = 0;
for (i = 0;i < 20;i ++) {
node = (rbtree_node*)malloc(sizeof(rbtree_node));
node->key = keyArray[i];
node->value = NULL;
rbtree_insert(T, node);
}
rbtree_traversal(T, T->root);
printf("----------------------------------------\n");
for (i = 0;i < 20;i ++) {
rbtree_node *node = rbtree_search(T, keyArray[i]);
rbtree_node *cur = rbtree_delete(T, node);
free(cur);
rbtree_traversal(T, T->root);
printf("----------------------------------------\n");
}
}
b/b+树
对于,红黑树,b/b+树,都是强查找数据类型,这种像是在一个大的集合中查找一个东西这种比较常见。
对于二叉树,1023个节点,我们可以用10层就可以表示了。对于这种树高,他的影响就是比对次数,找下一个节点多 。如果储存在一些节点是储存到内存中,那么还好,但是如果一些节点是存储在磁盘中,那么查找的次数会变多,所以出现了很多降层高的数据结构。因为如果我们每一个节点都存储在磁盘中,那么每次对比后找下一个节点就是一次磁盘寻址。那么层高越高,查找越耗时。
所以假设是1024个节点,四叉树。每个节点3个数据。那么就是
l
o
g
4
(
1024
/
3
)
log_4{(1024/3)}
log4(1024/3)那么就是5层就可以了。
btree/b-tree
一颗 M M M阶 B B B树 T T T,满足以下条件
- 每个结点至多拥有 M M M颗子树
- 根结点至少拥有两颗子树
- 除了根结点以外,其余每个分支结点至少拥有M/2课子树
- 所有的叶结点都在同一层上
- 有k课子树的分支结点则存在 k − 1 k-1 k−1个关键字,关键字按照递增顺序进行排序
- 关键字数量满足 c e i l ( M / 2 ) − 1 < = n < = M − 1 ceil(M/2)-1 <= n <= M-1 ceil(M/2)−1<=n<=M−1
b树每次添加都是添加到叶子节点的,如果叶子节点满了就分裂。如果根满了就,分裂,然后增加树高。
b树删除的时候,要么就是可以之间删除,不能直接删除就借位,借位不够的话就合并(父节点合并)。
创建一个节点:
btree_node *btree_create_node(int t, int leaf) {
btree_node *node = (btree_node*)calloc(1, sizeof(btree_node));
if (node == NULL) assert(0);
node->leaf = leaf;
node->keys = (KEY_VALUE*)calloc(1, (2*t-1)*sizeof(KEY_VALUE));
node->childrens = (btree_node**)calloc(1, (2*t) * sizeof(btree_node*));
node->num = 0;
return node;
}
删除一个节点
void btree_destroy_node(btree_node *node) {
assert(node);
free(node->childrens);
free(node->keys);
free(node);
}
节点分裂:一分为二
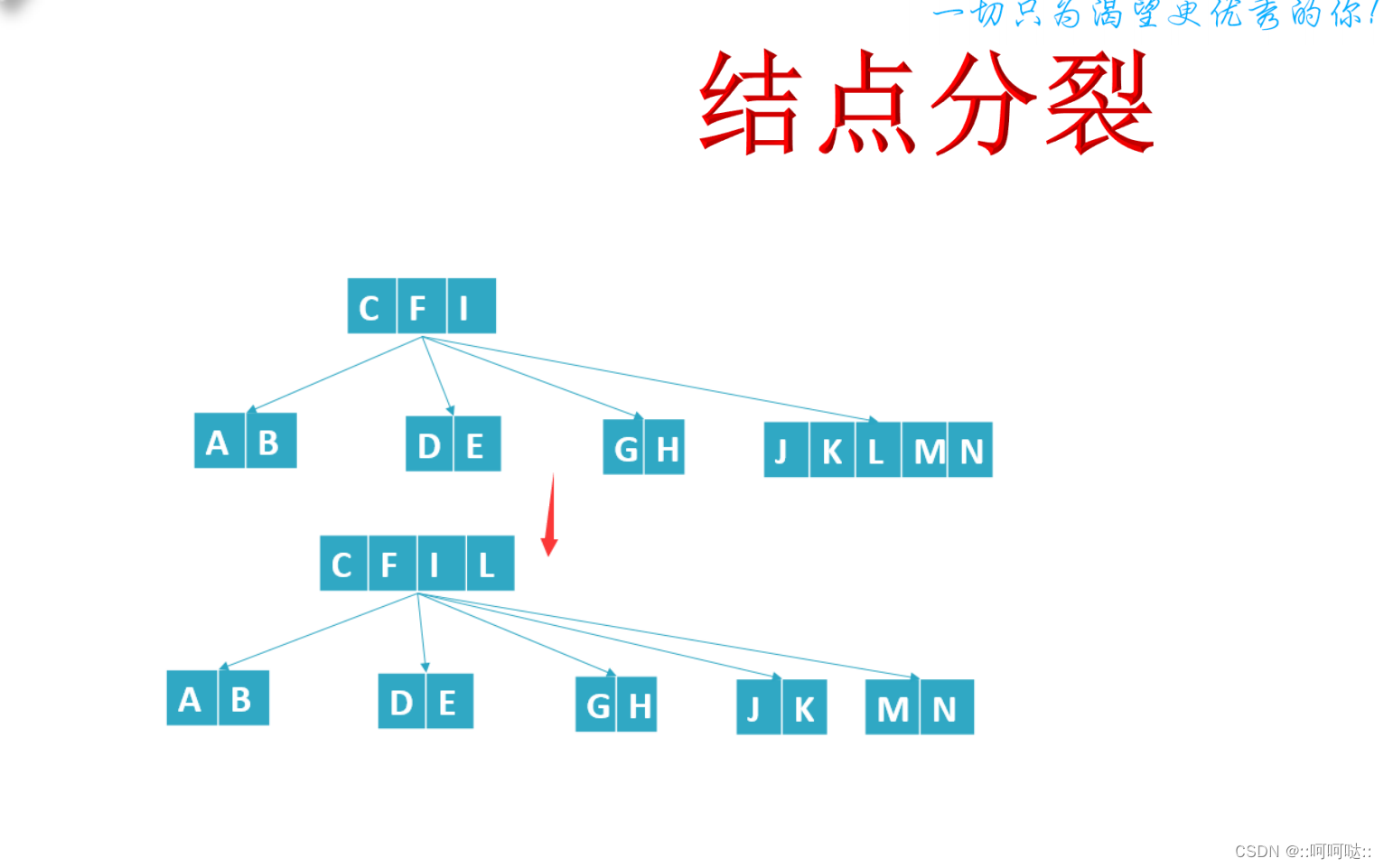
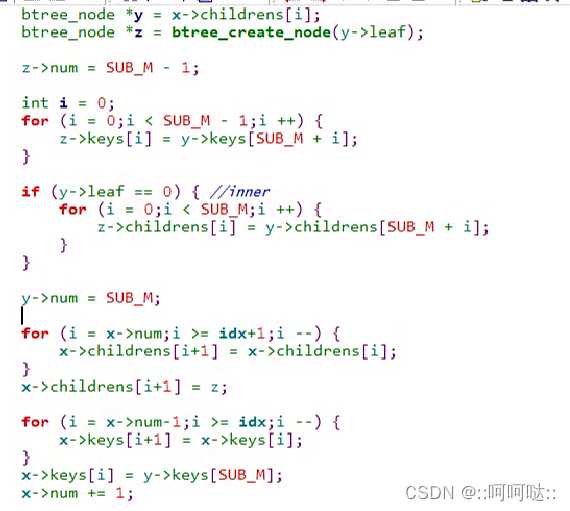
根节点分裂:一分为三
合并:
//{child[idx], key[idx], child[idx+1]}
void btree_merge(btree *T, btree_node *node, int idx) {
btree_node *left = node->childrens[idx];
btree_node *right = node->childrens[idx+1];
int i = 0;
/data merge
left->keys[T->t-1] = node->keys[idx];
for (i = 0;i < T->t-1;i ++) {
left->keys[T->t+i] = right->keys[i];
}
if (!left->leaf) {
for (i = 0;i < T->t;i ++) {
left->childrens[T->t+i] = right->childrens[i];
}
}
left->num += T->t;
//destroy right
btree_destroy_node(right);
//node
for (i = idx+1;i < node->num;i ++) {
node->keys[i-1] = node->keys[i];
node->childrens[i] = node->childrens[i+1];
}
node->childrens[i+1] = NULL;
node->num -= 1;
if (node->num == 0) {
T->root = left;
btree_destroy_node(node);
}
}
完整:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#define DEGREE 3
typedef int KEY_VALUE;
typedef struct _btree_node {
KEY_VALUE *keys;
struct _btree_node **childrens;
int num;
int leaf;//叶子个数
} btree_node;
typedef struct _btree {
btree_node *root;
int t;
} btree;
btree_node *btree_create_node(int t, int leaf) {
btree_node *node = (btree_node*)calloc(1, sizeof(btree_node));
if (node == NULL) assert(0);
node->leaf = leaf;
node->keys = (KEY_VALUE*)calloc(1, (2*t-1)*sizeof(KEY_VALUE));
node->childrens = (btree_node**)calloc(1, (2*t) * sizeof(btree_node*));
node->num = 0;
return node;
}
void btree_destroy_node(btree_node *node) {
assert(node);
free(node->childrens);
free(node->keys);
free(node);
}
void btree_create(btree *T, int t) {
T->t = t;
btree_node *x = btree_create_node(t, 1);
T->root = x;
}
void btree_split_child(btree *T, btree_node *x, int i) {
int t = T->t;
btree_node *y = x->childrens[i];
btree_node *z = btree_create_node(t, y->leaf);
z->num = t - 1;
int j = 0;
for (j = 0;j < t-1;j ++) {
z->keys[j] = y->keys[j+t];
}
if (y->leaf == 0) {
for (j = 0;j < t;j ++) {
z->childrens[j] = y->childrens[j+t];
}
}
y->num = t - 1;
for (j = x->num;j >= i+1;j --) {
x->childrens[j+1] = x->childrens[j];
}
x->childrens[i+1] = z;
for (j = x->num-1;j >= i;j --) {
x->keys[j+1] = x->keys[j];
}
x->keys[i] = y->keys[t-1];
x->num += 1;
}
void btree_insert_nonfull(btree *T, btree_node *x, KEY_VALUE k) {
int i = x->num - 1;
if (x->leaf == 1) {
while (i >= 0 && x->keys[i] > k) {
x->keys[i+1] = x->keys[i];
i --;
}
x->keys[i+1] = k;
x->num += 1;
} else {
while (i >= 0 && x->keys[i] > k) i --;
if (x->childrens[i+1]->num == (2*(T->t))-1) {
btree_split_child(T, x, i+1);
if (k > x->keys[i+1]) i++;
}
btree_insert_nonfull(T, x->childrens[i+1], k);
}
}
void btree_insert(btree *T, KEY_VALUE key) {
//int t = T->t;
btree_node *r = T->root;
if (r->num == 2 * T->t - 1) {
btree_node *node = btree_create_node(T->t, 0);
T->root = node;
node->childrens[0] = r;
btree_split_child(T, node, 0);
int i = 0;
if (node->keys[0] < key) i++;
btree_insert_nonfull(T, node->childrens[i], key);
} else {
btree_insert_nonfull(T, r, key);
}
}
void btree_traverse(btree_node *x) {
int i = 0;
for (i = 0;i < x->num;i ++) {
if (x->leaf == 0)
btree_traverse(x->childrens[i]);
printf("%C ", x->keys[i]);
}
if (x->leaf == 0) btree_traverse(x->childrens[i]);
}
void btree_print(btree *T, btree_node *node, int layer)
{
btree_node* p = node;
int i;
if(p){
printf("\nlayer = %d keynum = %d is_leaf = %d\n", layer, p->num, p->leaf);
for(i = 0; i < node->num; i++)
printf("%c ", p->keys[i]);
printf("\n");
#if 0
printf("%p\n", p);
for(i = 0; i <= 2 * T->t; i++)
printf("%p ", p->childrens[i]);
printf("\n");
#endif
layer++;
for(i = 0; i <= p->num; i++)
if(p->childrens[i])
btree_print(T, p->childrens[i], layer);
}
else printf("the tree is empty\n");
}
int btree_bin_search(btree_node *node, int low, int high, KEY_VALUE key) {
int mid;
if (low > high || low < 0 || high < 0) {
return -1;
}
while (low <= high) {
mid = (low + high) / 2;
if (key > node->keys[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return low;
}
//{child[idx], key[idx], child[idx+1]}
void btree_merge(btree *T, btree_node *node, int idx) {
btree_node *left = node->childrens[idx];
btree_node *right = node->childrens[idx+1];
int i = 0;
/data merge
left->keys[T->t-1] = node->keys[idx];
for (i = 0;i < T->t-1;i ++) {
left->keys[T->t+i] = right->keys[i];
}
if (!left->leaf) {
for (i = 0;i < T->t;i ++) {
left->childrens[T->t+i] = right->childrens[i];
}
}
left->num += T->t;
//destroy right
btree_destroy_node(right);
//node
for (i = idx+1;i < node->num;i ++) {
node->keys[i-1] = node->keys[i];
node->childrens[i] = node->childrens[i+1];
}
node->childrens[i+1] = NULL;
node->num -= 1;
if (node->num == 0) {
T->root = left;
btree_destroy_node(node);
}
}
void btree_delete_key(btree *T, btree_node *node, KEY_VALUE key) {
if (node == NULL) return ;
int idx = 0, i;
while (idx < node->num && key > node->keys[idx]) {
idx ++;
}
if (idx < node->num && key == node->keys[idx]) {
if (node->leaf) {
for (i = idx;i < node->num-1;i ++) {
node->keys[i] = node->keys[i+1];
}
node->keys[node->num - 1] = 0;
node->num--;
if (node->num == 0) { //root
free(node);
T->root = NULL;
}
return ;
} else if (node->childrens[idx]->num >= T->t) {
btree_node *left = node->childrens[idx];
node->keys[idx] = left->keys[left->num - 1];
btree_delete_key(T, left, left->keys[left->num - 1]);
} else if (node->childrens[idx+1]->num >= T->t) {
btree_node *right = node->childrens[idx+1];
node->keys[idx] = right->keys[0];
btree_delete_key(T, right, right->keys[0]);
} else {
btree_merge(T, node, idx);
btree_delete_key(T, node->childrens[idx], key);
}
} else {
btree_node *child = node->childrens[idx];
if (child == NULL) {
printf("Cannot del key = %d\n", key);
return ;
}
if (child->num == T->t - 1) {
btree_node *left = NULL;
btree_node *right = NULL;
if (idx - 1 >= 0)
left = node->childrens[idx-1];
if (idx + 1 <= node->num)
right = node->childrens[idx+1];
if ((left && left->num >= T->t) ||
(right && right->num >= T->t)) {
int richR = 0;
if (right) richR = 1;
if (left && right) richR = (right->num > left->num) ? 1 : 0;
if (right && right->num >= T->t && richR) { //borrow from next
child->keys[child->num] = node->keys[idx];
child->childrens[child->num+1] = right->childrens[0];
child->num ++;
node->keys[idx] = right->keys[0];
for (i = 0;i < right->num - 1;i ++) {
right->keys[i] = right->keys[i+1];
right->childrens[i] = right->childrens[i+1];
}
right->keys[right->num-1] = 0;
right->childrens[right->num-1] = right->childrens[right->num];
right->childrens[right->num] = NULL;
right->num --;
} else { //borrow from prev
for (i = child->num;i > 0;i --) {
child->keys[i] = child->keys[i-1];
child->childrens[i+1] = child->childrens[i];
}
child->childrens[1] = child->childrens[0];
child->childrens[0] = left->childrens[left->num];
child->keys[0] = node->keys[idx-1];
child->num++;
node->keys[idx-1] = left->keys[left->num-1];
left->keys[left->num-1] = 0;
left->childrens[left->num] = NULL;
left->num --;
}
} else if ((!left || (left->num == T->t - 1))
&& (!right || (right->num == T->t - 1))) {
if (left && left->num == T->t - 1) {
btree_merge(T, node, idx-1);
child = left;
} else if (right && right->num == T->t - 1) {
btree_merge(T, node, idx);
}
}
}
btree_delete_key(T, child, key);
}
}
int btree_delete(btree *T, KEY_VALUE key) {
if (!T->root) return -1;
btree_delete_key(T, T->root, key);
return 0;
}
int main() {
btree T = {0};
btree_create(&T, 3);
srand(48);
int i = 0;
char key[27] = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (i = 0;i < 26;i ++) {
//key[i] = rand() % 1000;
printf("%c ", key[i]);
btree_insert(&T, key[i]);
}
btree_print(&T, T.root, 0);
for (i = 0;i < 26;i ++) {
printf("\n---------------------------------\n");
btree_delete(&T, key[25-i]);
//btree_traverse(T.root);
btree_print(&T, T.root, 0);
}
}
b树和b+树的区别
对于b树还有b+树的区别:
- b树的每个节点都是可以存储数据的
- b+树的只有叶子节点可以存储数据,内节点只能当索引用。
对于一个节点,b树比b+树所需的内存要大,所以相同的内存,b+树存的节点多与b树。
然后举个例子:假如有1000w个节点数据,那么如果用b树存储这些数据,那么数据会放在内存中,有的数据会放在磁盘中,那么如果我们用b+树进行存储的这些数据的话,我们是将索引关系放在内存中,数据放在磁盘中,然后查找的时候通过一次寻址(内存向磁盘寻址)就可以了。
所以b+树通常用来做磁盘索引,特别是那种大量的索引。所以向MySQL等都是b+树。
海量数据去重的Hash与BloomFilter
总体脉络
背景:
- 使用 word 文档时,word 如何判断某个单词是否拼写正确?
- 网络爬虫程序,怎么让它不去爬相同的 url 页面?
- 垃圾邮件过滤算法如何设计?
- 公安办案时,如何判断某嫌疑人是否在网逃名单中?
- 缓存穿透问题如何解决?
主要解决的就是从海量数据中查询某个字符串是否存在?
散列表
对于平衡二叉树增删改查时间复杂度为 O(nlog(n));平衡的目的是增删改后,保证下次搜索能稳定排除一半的数据;
直观理解:100万个节点,最多比较 20 次;10 亿个节点,最多比较 30 次;
总结:通过比较保证有序,通过每次排除一半的元素达到快速
平衡二叉树结构有序,提升搜索效率。而散列表则是key与节点存储位置的映射关系。
根据 key 计算 key 在表中的位置的数据结构;是 key 和其所在
存储地址的映射关系;
注意:散列表的节点中 kv 是存储在一起的;
hash 函数
struct node {
void *key;
void *val;
struct node *next;
};
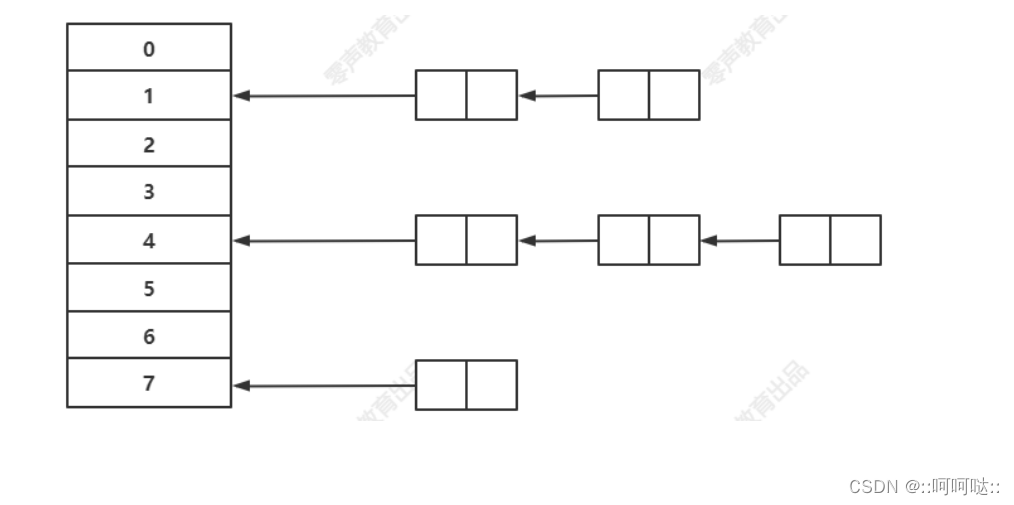
hash 函数
映射函数 Hash(key)=addr;hash 函数可能会把两个或两个以上的不同 key 映射到同一地址,这种情况称之为冲突(或者hash 碰撞);
选择hash
- 计算速度快
- 强随机分布(等概率、均匀地分布在整个地址空间)murmurhash1,murmurhash2(使用最多),murmurhash3,siphash( redis6.0 当中使用,rust 等大多数语言选用的 hash 算法来实
现 hashmap),cityhash 都具备强随机分布性;测试地址如下:
https://github.com/aappleby/smhasher - siphash 主要解决字符串接近的强随机分布性;
操作流程
hash 函数
struct node {
void *key;
void *val;
struct node *next;
};
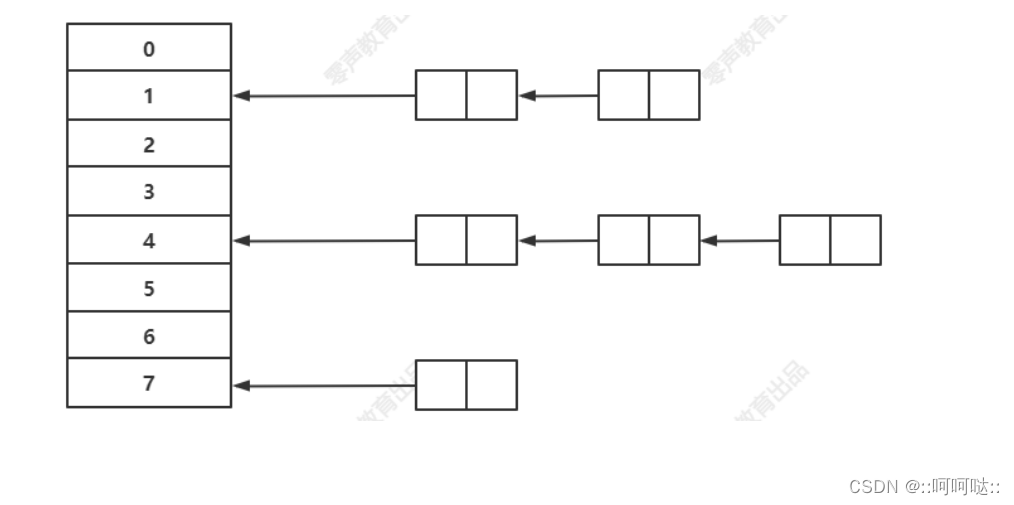
我们通常就是将一个key通过哈希函数得到一个整数,然后我们会将这个整数对数组的长度进行取余,然后他肯定会落在数组的某个槽位中。然后我们会在改槽位中增加一个节点。
然后随着我们插入的数增多,他肯定会出现多个数落在同一个槽位中,这就形成了hash冲突。上面是拉链发。
冲突
负载因子
数组存储元素的个数 / 数组长度;用来形容散列表的存储密度;负载因子越小,冲突概率越小,负载因子越大,冲突概率越大。
冲突处理
当负载因子在合理范围内的话:
链表法
引用链表来处理哈希冲突;也就是将冲突元素用链表链接起来;这也是常用的处理冲突的方式;但是可能出现一种极端情况,冲突元素比较多,该冲突链表过长,这个时候可以将这个链表转换为红黑树、最小堆(java hashmap);由原来链表时间复杂度 转换为红黑树时间复杂度 ;那么判断该链表过长的依据是多少?可以采用超过 256(经验值)个节点的时候将链表结构转换为红黑树或堆结构(java hashmap);
开放寻址法
将所有的元素都存放在哈希表的数组中,不使用额外的数据结构;一般使用线性探查的思路解决;
- 当插入新元素的时,使用哈希函数在哈希表中定位元素位置;
- 检查数组中该槽位索引是否存在元素。如果该槽位为空,则插入,否则3;
- 在 2 检测的槽位索引上加一定步长接着检查2; 加一定步长分为以下几种:
i+1,i+2,i+3,i+4, … ,i+n(不好)
i − 1 2 i- 1^2 i−12, i + 1 2 i+ 1^2 i+12, i − 3 2 i- 3^2 i−32, 1 + 4 2 1+4^2 1+42, … 这两种都会导致同类 hash 聚集;也就是近似值它的hash值也近似,那么它的数组槽位也靠近,形成 hash 聚集;第一种同类聚集冲突在前,第二种只是将聚集冲突延后; 另外还可以使用双重哈希来解决上面出现hash聚集现象:
在.net HashTable类的hash函数Hk定义如下:
Hk(key) = [GetHash(key) + k * (1 +(((GetHash(key) >> 5) + 1) %(hashsize – 1)))] % hashsize
在此 (1 + (((GetHash(key) >> 5) + 1) %
(hashsize – 1))) 与 hashsize互为素数(两数互为素数表示两者没有共同的质因⼦);
执⾏了 hashsize 次探查后,哈希表中的每⼀个位置都有且只有⼀次被访问到,
也就是说,对于给定的 key,对哈希表中的同⼀位置不会同时使⽤Hi 和 Hj;
当负载因子不在合理范围内的话:
扩容
used>size
缩容
used<0.1*size
rehash
stl中散列表的实现
对于map,set,mltimap,multiset都是用红黑树实现的。
而在 STL 中 unordered_map,unordered_set、unordered_multimap、unordered_multiset 四兄弟底层实
现都是散列表;
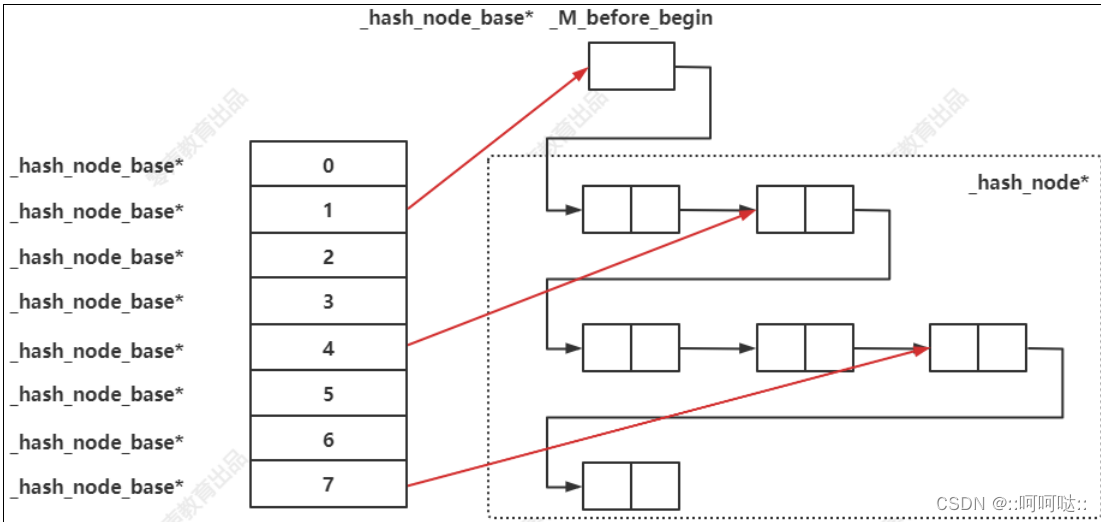
他主要的目的就是将后面的给串成一个单链表,这样方便我们的迭代器进行依次查找。实际上还是hash,为了实现迭代器,将后面具体节点串成一个单链表
布隆过滤器
背景
对于散列表我们需要保存这个[key,val]对,但是有时候我们并不需要知道[key,val]的具体的内容,我们只想知道key存不存在。也就是内存有限我们并不需要知道val,我们只需要知道key存不存在。这时候我们就需要布隆过滤器。
例如:我们想要知道key在不在一个文件中,如果我们将这个文件全部加载到内存中,这是一种方式。
还有一种方式就是我们将这个具体的key存在文件中的时候我们先在布隆过滤器中做个标记(每存一个key,我们都在这个过滤器中做一个标记),未来我们想找到这个key在不在这个文件中,我们就可以先看看这个Key在不在这个布隆过滤器中,因为布隆过滤器占得内存小,而且在内存中,所以我们就可以快速知道他在不在这个文件中。这就是数据库rocksdb。
还有一种数据库,不如说我们的服务器还有MySQL,我们的服务器和MySQL要进行网络的交互。这时候我们要知道这个key在不在这个MySQL中,我们不想经过这个网络交互,并且在MySQL中查询。这个时候我们就可以在服务器部署一个布隆过滤器。然后我们就可以直接将这个key在布隆过滤器中查询,这时候就不需要经过网络交互。
构成
布隆过滤器是一种概率型数据结构,它的特点是高效地插入和查询,能确定某个字符串一定不存在或者可能存在;
布隆过滤器不存储具体数据,所以占用空间小,查询结果存在误差,但是误差可控,同时不支持删除操作;
它是由位图(BIT 数组)+ n 个 hash 函数构成的。
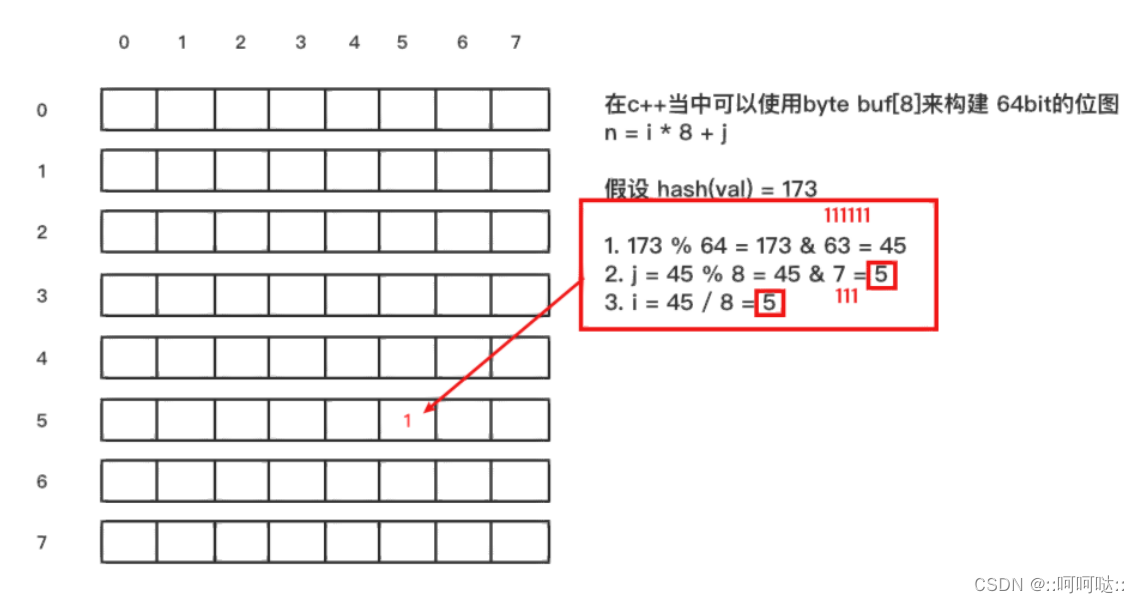
原理
当一个元素加入位图时,通过 k 个 hash 函数将这个元素映射到位图的 k 个点,并把它们置为 1;当检索时,再通过 k 个 hash函数运算检测位图的 k 个点是否都为 1;如果有不为 1 的点,那么认为该 key 不存在;如果全部为 1,则可能存在;
为什么不支持删除操作?
- 在位图中每个槽位只有两种状态(0 或者 1),一个槽位被设置为 1 状态,但不确定它被设置了多少次;也就是不知道被多少个 key 哈希映射而来以及是被具体哪个 hash 函数映射而来;
判断不存在 只要一个索引位为0就是不存在;如果都为1,是否一定存在?不一定,可控的(假阳率)。
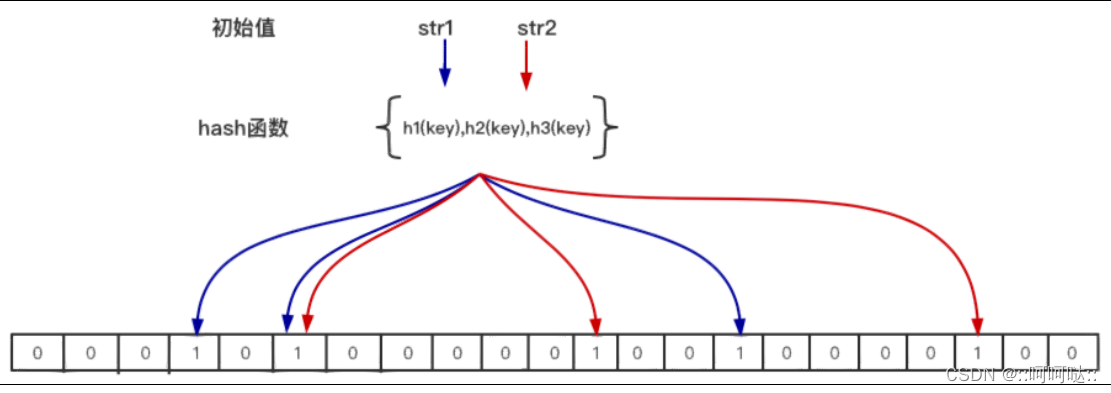
能确定一个key一定不存在,可控假阳率确定存在。
应用场景
布隆过滤器通常用于判断某个 key 一定不存在的场景,同时允许判断存在时有误差的情况;
常见处理场景:① 缓存穿透的解决;② 热 key 限流;
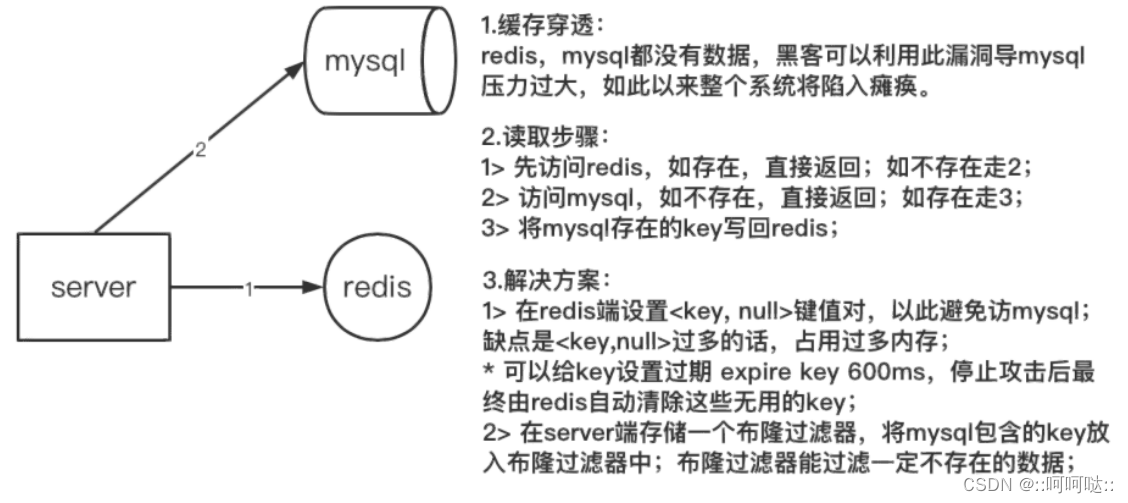
- 描述缓存场景,为了减轻数据库(mysql)的访问压力,在server 端与数据库(mysql)之间加入缓存用来存储热点数据;
- 描述缓存穿透,server端请求数据时,缓存和数据库都不包含该数据,最终请求压力全部涌向数据库;
- 数据请求步骤,如图中 2 所示;
- 发生原因:黑客利用漏洞伪造数据攻击或者内部业务 bug 造成
- 大量重复请求不存在的数据;
- 解决方案:如图中 3 所示;
应用分析
在实际应用中,该选择多少个 hash 函数?要分配多少空间的位图?预期存储多少元素?如何控制误差?
公式如下
n -- 预期布隆过滤器中元素的个数,如上图 只有str1和str2 两
个元素 那么 n=2
p -- 假阳率,在0-1之间 0.000000~
m -- 位图所占空间
k -- hash函数的个数
公式如下:
n = ceil(m / (-k / log(1 - exp(log(p) / k))))
p = pow(1 - exp(-k / (m / n)), k)
m = ceil((n * log(p)) / log(1 / pow(2, log(2))));
k = round((m / n) * log(2));
也就是通过给定的n,p。我们可以算出具体的m和k。实际工程应用的时候我们通过n,p来计算出m,k。
变量关系
假定4个初始值:
n = 4000
p = 0.000000001
m = 172532
k = 30
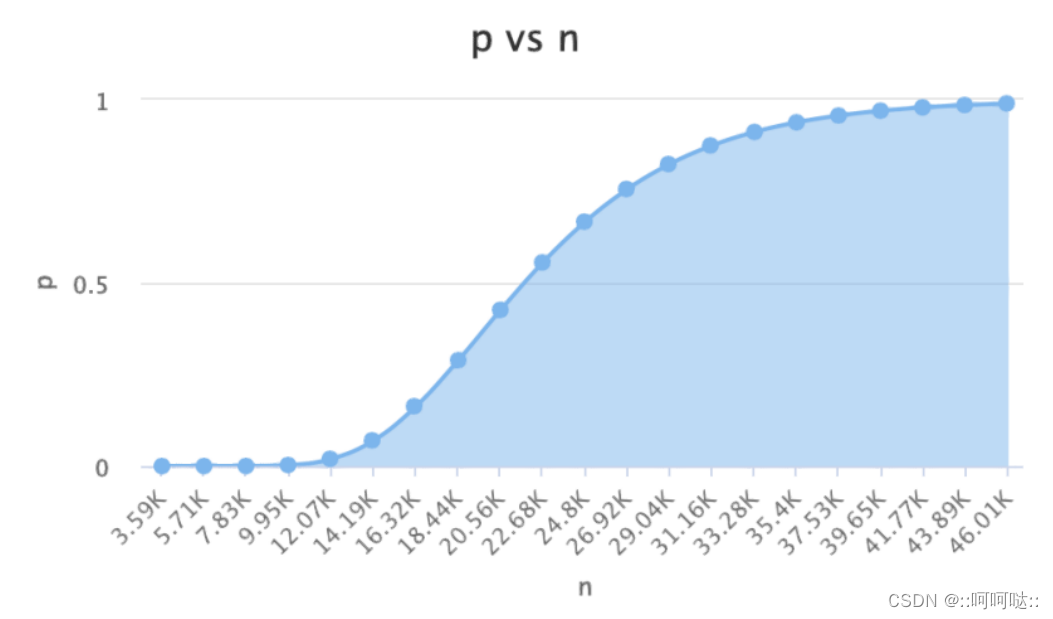
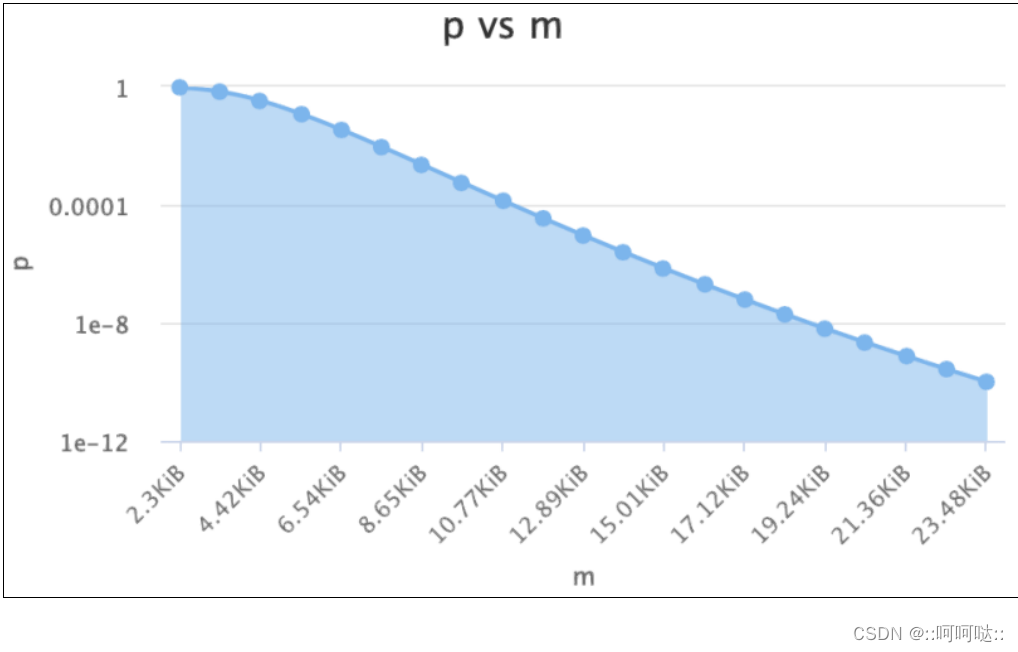
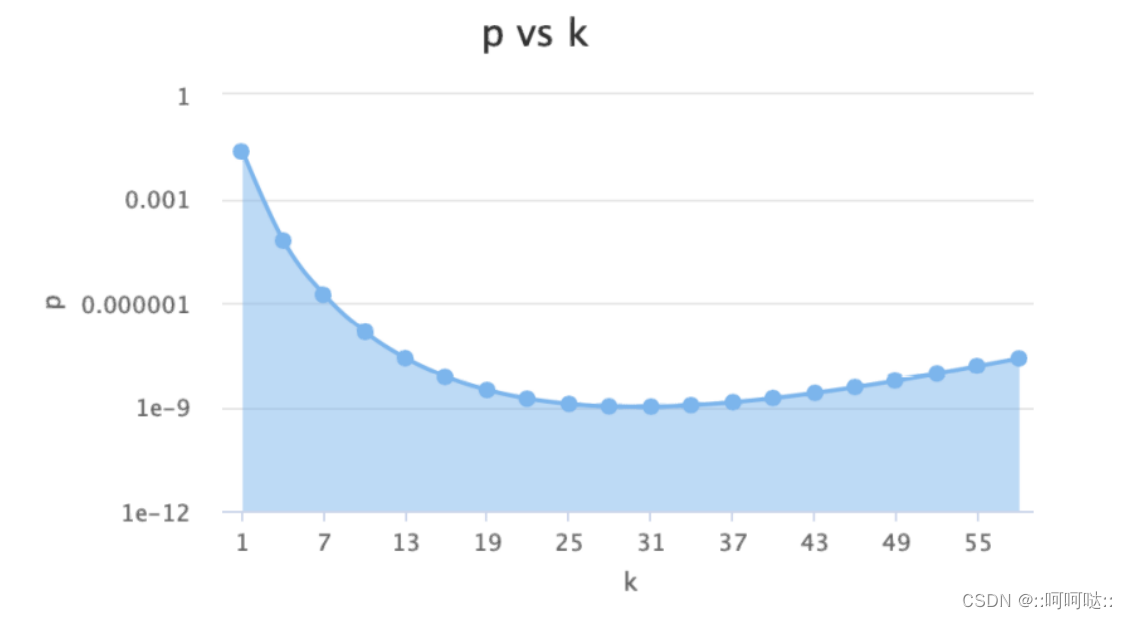
这个就是哈希函数和假阳率的表,这个时候我们可以看到31最小,也有一个面试题,为什么通常%31,这个是通过数学验证的。
确定 n 和 p
在实际使用布隆过滤器时,首先需要确定 n 和 p,通过上面的
运算得出 m 和 k;通常可以在下面这个网站上选出合适的值;
https://hur.st/bloomfilter
选择 hash 函数
选择一个 hash 函数,通过给 hash 传递不同的种子偏移值,采用线性探寻的方式构造多个 hash 函数;
#define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
uint64_t hash1 = MurmurHash2_x64(key, len, Seed);
uint64_t hash2 = MurmurHash2_x64(key, len,
MIX_UINT64(hash1));
for (i = 0; i < k; i++) // k 是hash函数的个数
{
Pos[i] = (hash1 + i*hash2) % m; // m 是位图的
⼤⼩
}
思考题
只用 2GB 内存在 20 亿(2e9)个整数中找到出现次数最多的数
k 整数
v 出现次数
散列表。
四个字节。uint32 4个字节
所以一个k v8个字节,2亿个数,需要1.6G内存,所以20亿需要16G内存。
我们需要抽象和拆分的思想。
拆分成若干等份
把20亿个整数的大文件拆分到多个文件中,目的把相同整数放在同一个文件中。我们用hash函数,强随机分布性

分布式一致性hash
背景
例如:我们有三个服务器节点,对于来的每一条数据我们进行hash,hash到这三个服务器节点中。
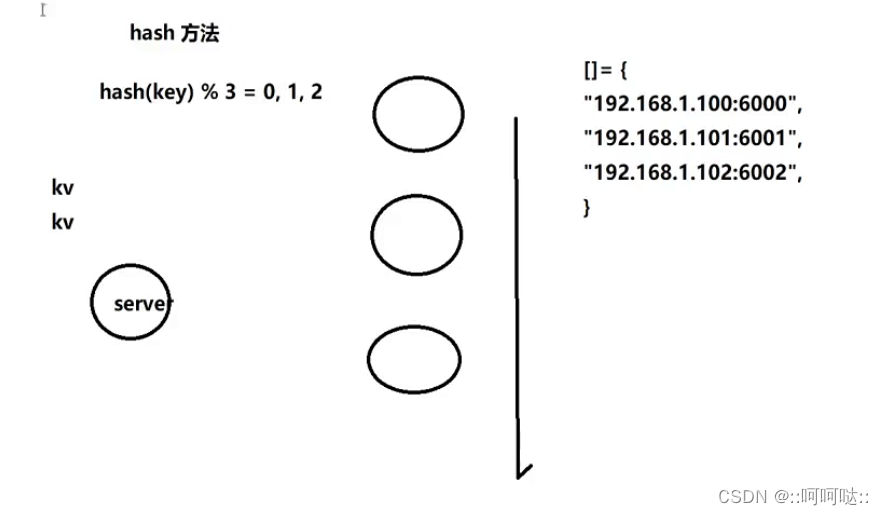
但是随着我们数据越来越多,我们增加了一个服务器节点。也就是有四个节点了,这时我们hash函数改成%4了。这样就造成了hash失效。也就是后面两个对应不上了。
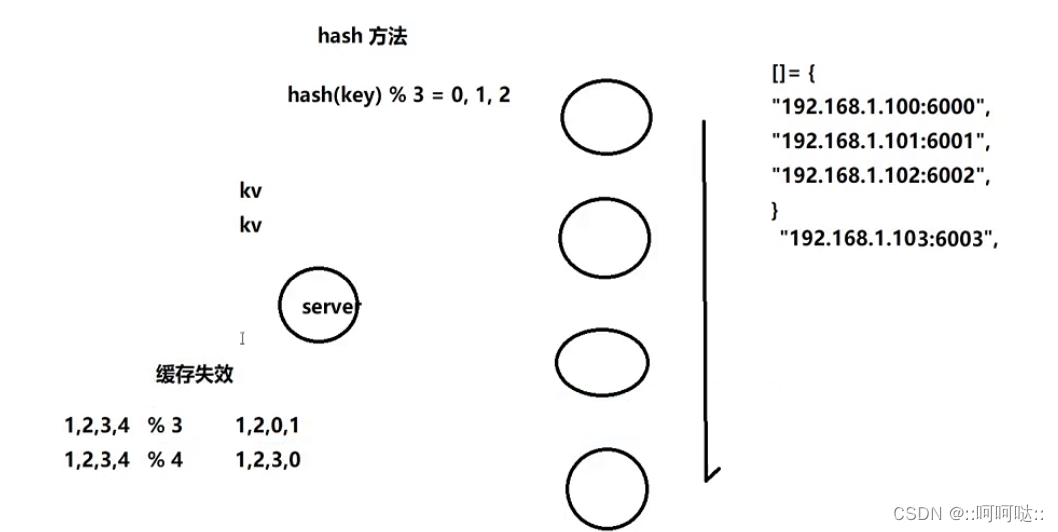
固定算法:
这个是解决哈希失效的一种方法
我们可以将这个取余的数固定比如说
h
a
s
h
(
k
e
y
)
hash(key)
hash(key) %
2
32
2^{32}
232=index。但是我们不可能真的找一个
2
32
2^{32}
232的数组。我们联想成一个圆环,然后改变一下我们的映射关系。
h
a
s
h
(
k
e
y
)
hash(key)
hash(key) %
2
32
2^{32}
232=index
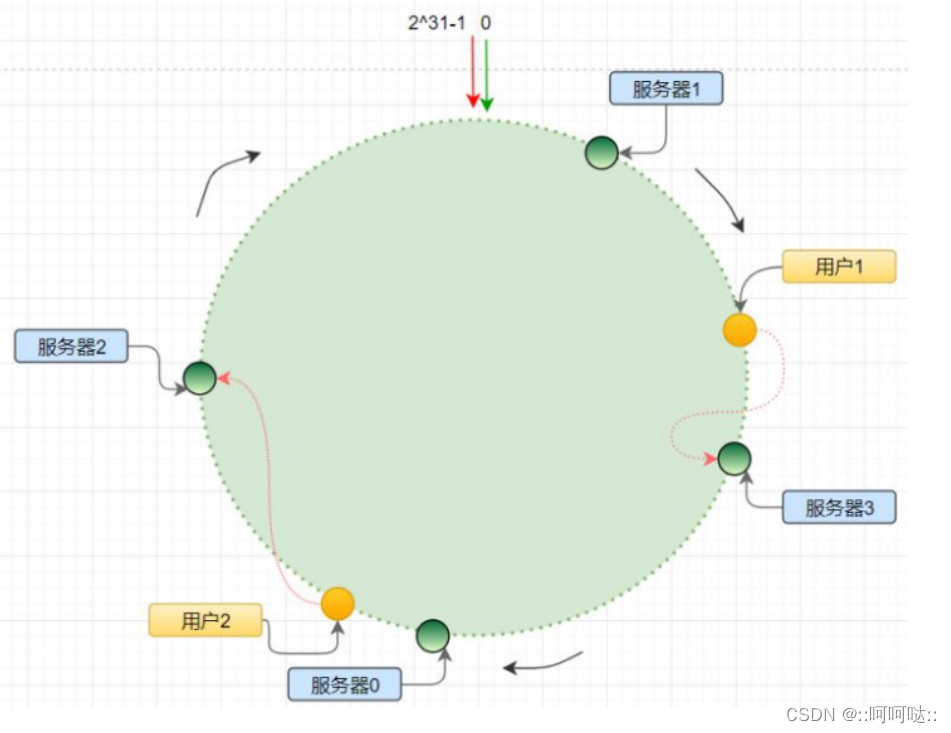
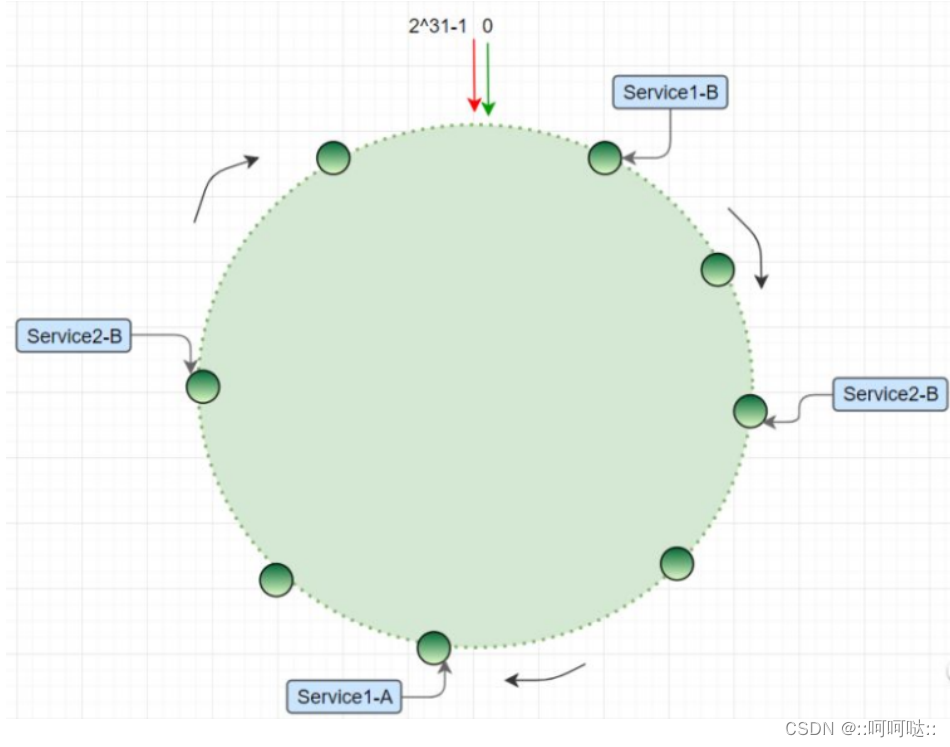
一开始我们有三个服务器节点(黑色),我们有四个数据进行插入(红色)。
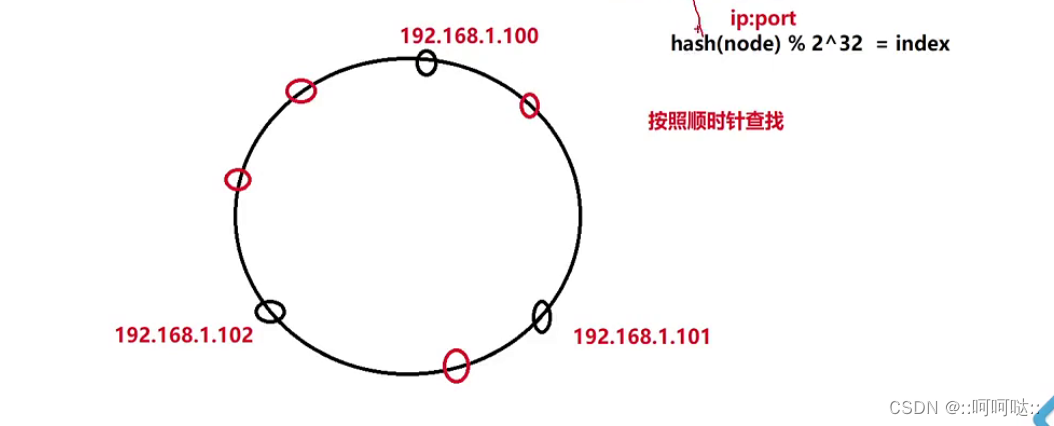
然后我们对这4个数据(红色的圈)进行hash后,我们顺时针就行查找最近的那个ip服务器地址(也就是黑色的圈)。
对于判断数据属于那个节点:
根据数据的哈希值,去哈希环找到第一个大于等于数据哈希值的机器(可以理解为离它最近)。如果数据的哈希值大于当前最大的机器哈希值,那么就把这个数据放在位置最靠前(哈希值最小)的机器上,因为是一个环;
然后现在新加入一个服务器节点:
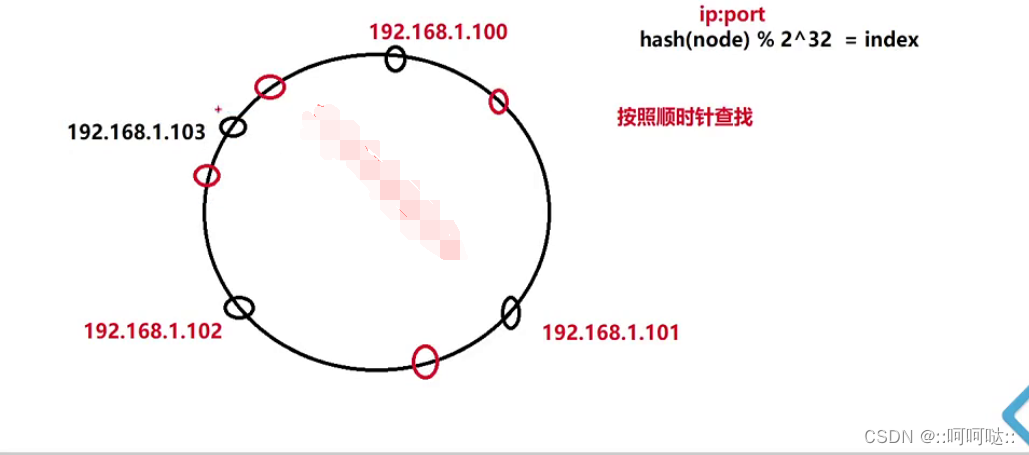
这个时候就出现一个问题,在没有增加103这个服务器节点的时候k4是映射到100的,增加了之后就映射到103了。这个时候还是有缓冲失效。
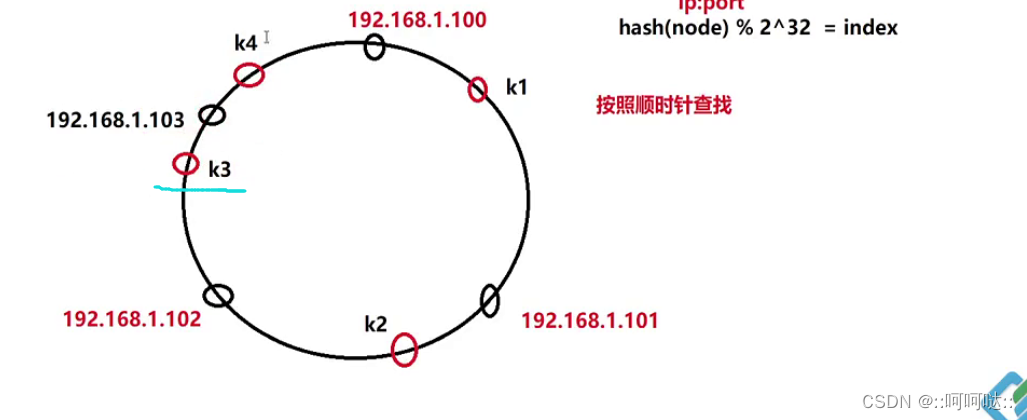
这个时候我们还是会有缓冲失效,不过是小面积的。局部缓冲失效。
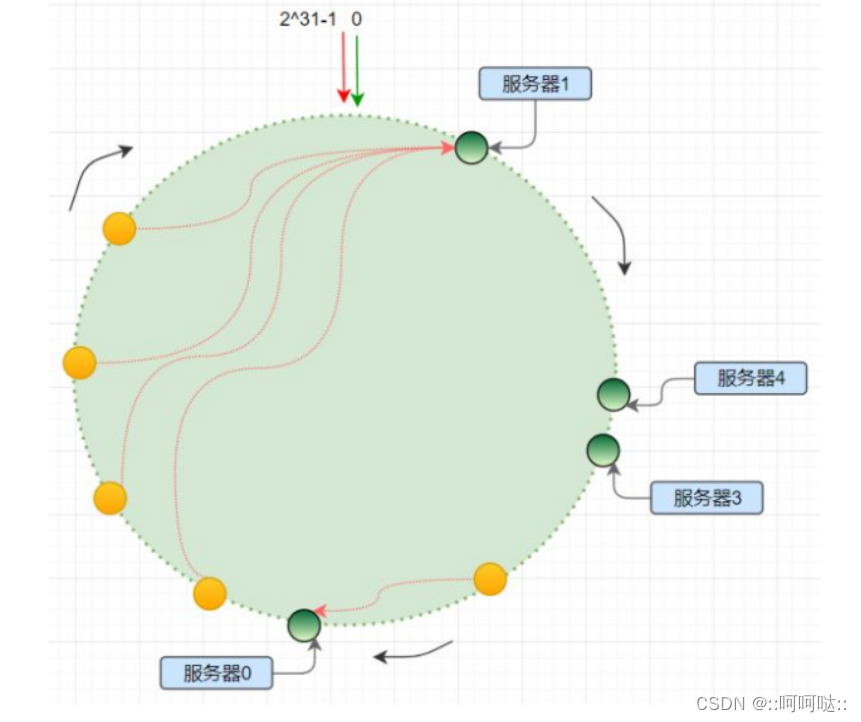
怎么解决这个问题呢,我们在假如103这个节点的时候我们会将102到103的数据从100迁移到103。这个就叫做哈希迁移。
哈希偏移
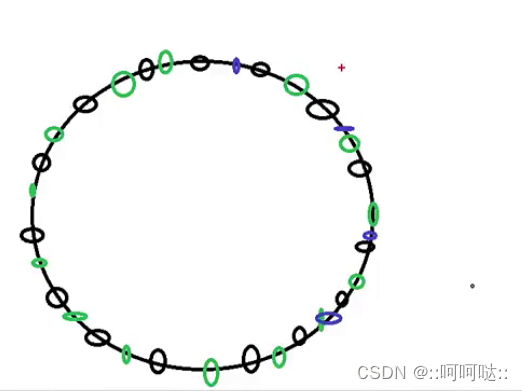
hash 算法得到的结果是随机的,不能保证服务器节点均匀分布在哈希环上;分布不均匀造成请求访问不均匀,服务器承受的压力不均匀;也就是说有的节点存储的很多,有的节点存储的很少。
例如:目前一共3个机器,机器A、B的哈希值分别为1和2,而另一个机器C的哈希值为 2^32-1,那么大部分的数据都会被分给机器C。
其根本就是样本数太少的原因。
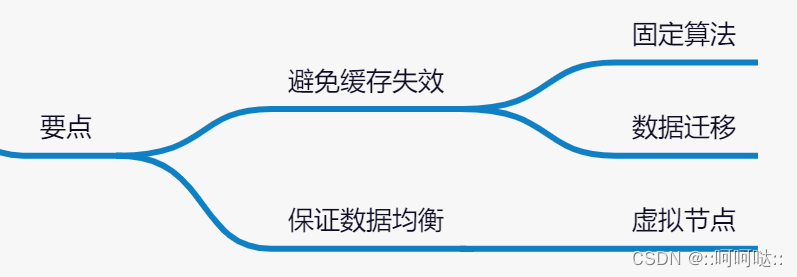
虚拟节点
引入了虚拟节点概念,虚拟节点相当于真实节点的分身,一个真实节点可以有很多个虚拟节点,当数据被分配给这些虚拟节点时,本质上是分给这个真实节点的。由于数量变多了,数据分布的均衡性会有所提高;
为了解决哈希偏移的问题,增加了虚拟节点的概念;理论上,哈希环上节点数越多,数据分布越均衡;为每个服务节点计算多个哈希节点(虚拟节点);通常做法
是,hash(“IP:PORT:seqno”) % 2 32 2^{32} 232;
这个时候我们就将4个变成了1000个了。
这时候就变成了这样

新增节点时:例如原本的节点哈希值列表为[1,100,500,1000],新增节点800后,在501~799范围内的数据原本是分给哈希值为1000的节点的,现在要把这部分数据迁移到节点800;
删除节点:例如原本的节点哈希值列表为[1,100,500,800,1000],删除节点500后,原本范围是101~500的数据要迁移到节点800.
这时候就不不会出现哈希偏移了,然后这时候哈希迁移数量也变少了。
解决两个问题:
- 不会出现哈希偏移
- 哈希迁移数量也变少
这里面是是一个map<int,string>mm;
然后我们找的时候用upper_bound(map.find(hash(key)))就行
大文件hash 拆成小文件
单台机器分流到多台机器
代码实现过程的一些思考
理解原理其实不难,但实现的时候需要考虑的东西就有很多了,比如要怎么处理虚拟节点和实际节点的对应关系、新增或者删除节点后的数据要怎么处理。
下面直接说数据存放在某个虚拟节点,其实是存在这个虚拟节点对应的实际节点上的,为了描述方便才这样说的。虚拟节点本身其实并不是实际存在的,只是为了让数据分布的更加均匀而设置的。
哈希值怎么得到
使用了 Murmurhash算法,它是一种非加密型哈希函数,适用于一般的哈希检索操作。高运算性能,低碰撞率,由Austin Appleby创建于2008年,现已应用到Hadoop、libstdc++、nginx、libmemcached等开源系统。2011年Appleby被Google雇佣,随后Google推出其变种的CityHash算法。代码里直接复用了MurmurHash2的实现。
unsigned int my_getMurMurHash(const void *key, int len)
如何找到第一个大于等于当前数据哈希值的节点
在哈希类中存储一个有序的虚拟节点哈希值列表this->sorted_node_hash_list,在这个列表中使用二分查找,返回值为节点在列表中的位置,从而方便在添加、删除节点时,复用这个函数然后找到当前位置后面的节点。
unsigned int consistent_hash::find_nearest_node(unsigned int hash_value)
新增一个实际节点
看了Github上一些别人实现的一致性哈希,大多都没考虑新增节点时数据的迁移问题。在新增一个实际节点后,会为它生成一些虚拟节点,每个虚拟节点有一个自己的哈希值,会对应到哈希环中的一个位置,插入新虚拟节点后可能会需要从后面位置的虚拟节点上“抢”一些数据。抢夺的数据可能与当前的虚拟节点是属于同一个实际节点的,例如:原本的虚拟节点列表为[1,100,500,1500],在新增实际节点A时,先生成了一个虚拟节点1000,那么它会从1500节点上“抢”走范围在501 ~ 1000的数据;然后节点A又生成了一个哈希值为800的虚拟节点,那么就会从节点1000上“抢”走范围在501 ~ 800的数据。
void consistent_hash::add_real_node(string ip, unsigned int virtual_node_num)
删除一个实际节点
删除一个实际节点时,属于它的虚拟节点也要删除。如果在删除过程中,某个虚拟节点有存放数据,那么就要从当前虚拟节点的位置向后遍历,找到第一个不属于要被删除实际节点的虚拟节点。例如目前哈希值为1000、属于A实际节点的虚拟节点要被删掉了,1500节点也属于A,不能把数据迁移到这里;2000节点属于B,因此选择把1000节点上的数据迁移到2000节点。
void consistent_hash::drop_real_node(string ip)
详情可以看看这个链接
总结
















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









