






1. BaseInfo
| Title | Transformer-Based Visual Segmentation: A Survey |
| Adress | https://arxiv.org/pdf/2304.09854 |
| Journal/Time | T-PAMI, 2024 |
| Author | 南洋理工 |
| Code | https://github.com/lxtGH/Awesome-Segmentation-With-Transformer |
2. Concrete
1.1 ViT和DETR 的出现使得分割与检测领域有了十足的进展,目前几乎各个数据集基准上,排名靠前的方法都是基于Transformer的。为此有必要系统地总结与对比下这个方向的方法与技术特点。
1.2 近期的大模型架构均基于Transformer结构,包括多模态模型以及分割的基础模型(SAM),视觉各个任务向着统一的模型建模靠拢。
1.3 分割与检测衍生出来了很多相关下游任务,这些任务很多方法也是采用Transformer结构来解决。
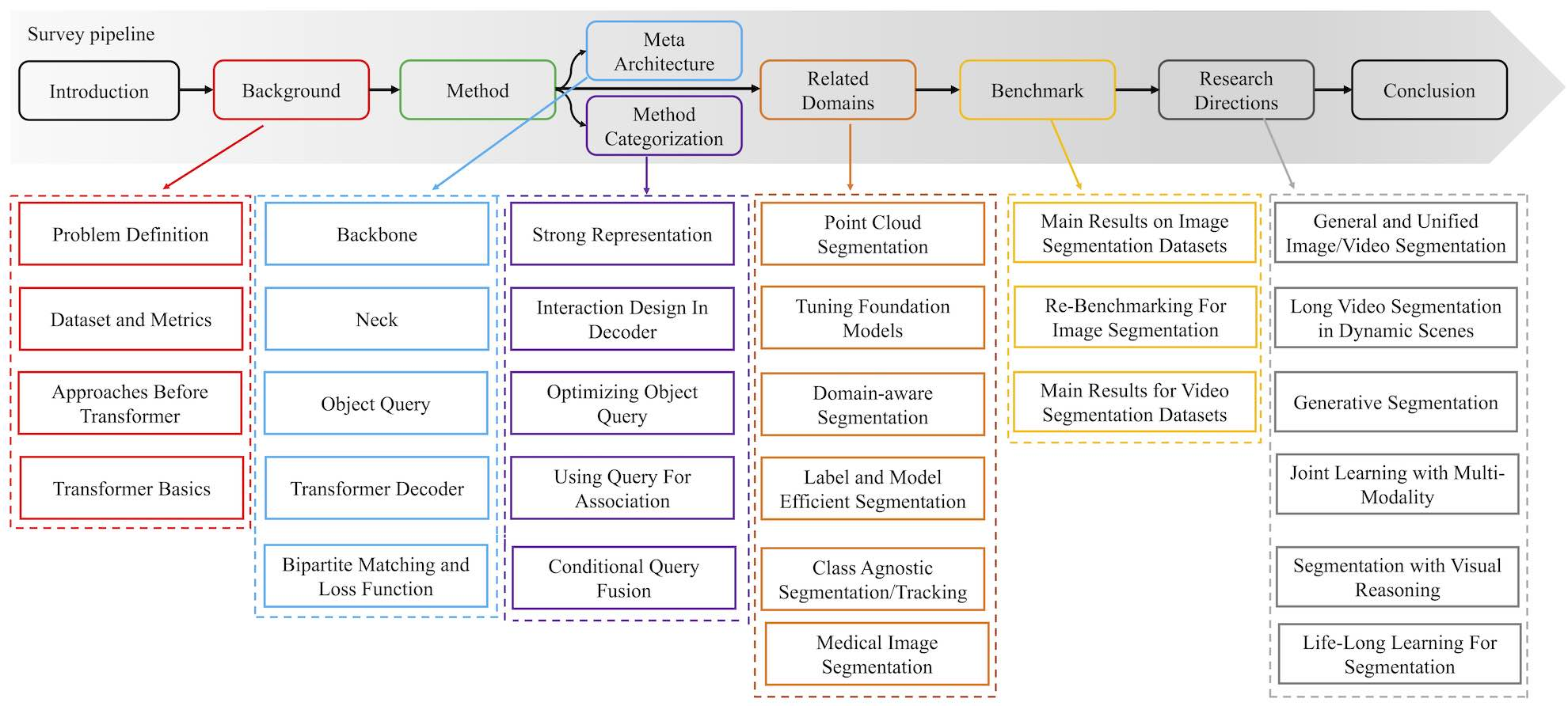
综述流程:
Object Query / Method Categorization 主要关注这一部分,还有 3.2 Specific Subfields 这部分,表示学习、解码器中的交互设计、使用查询优化对象查询关联和条件查询生成。。这个流程图挺详细的。
定义任务、数据集和基于 CNN 的方法,然后转向基于转换器的方法,涵盖现有方法和未来的工作方向。
3.1 基于 DETR
3 和 4 是代表性论文。
5 实验结果。
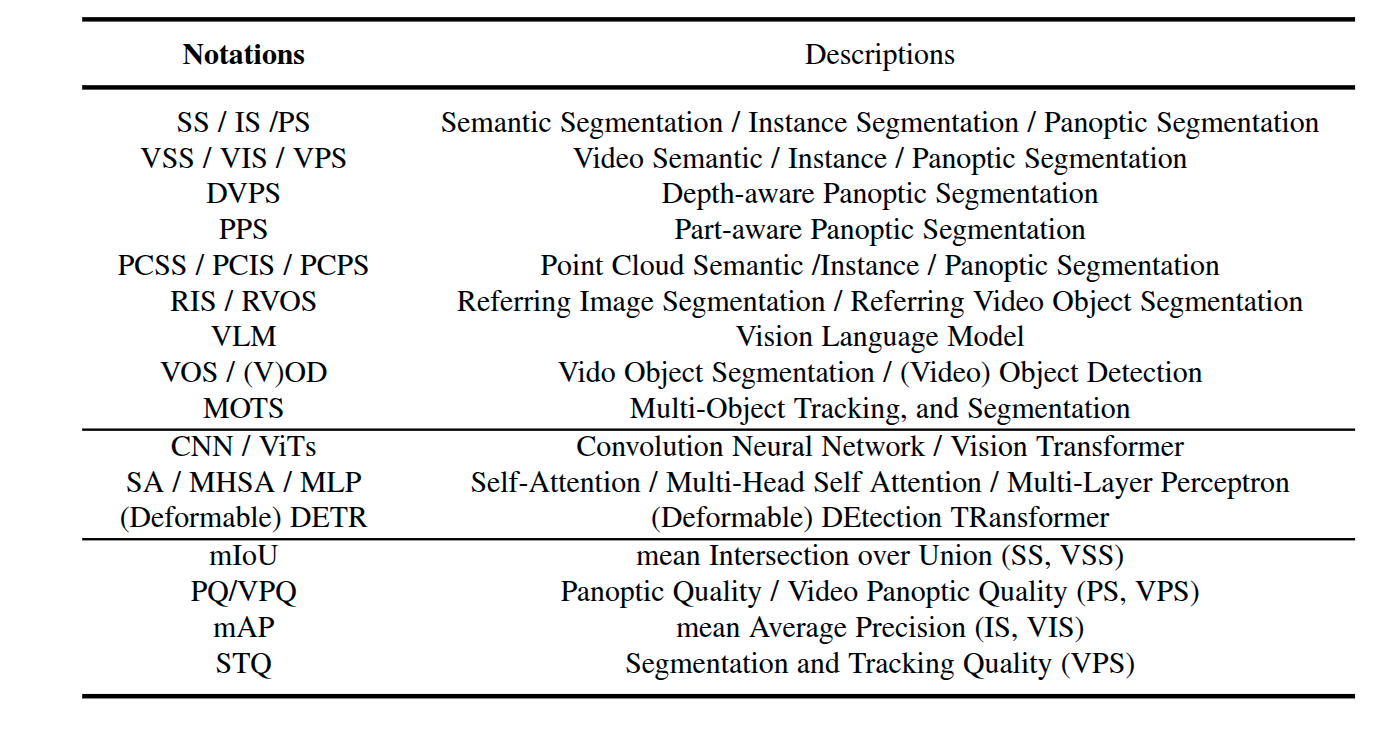
任务分类
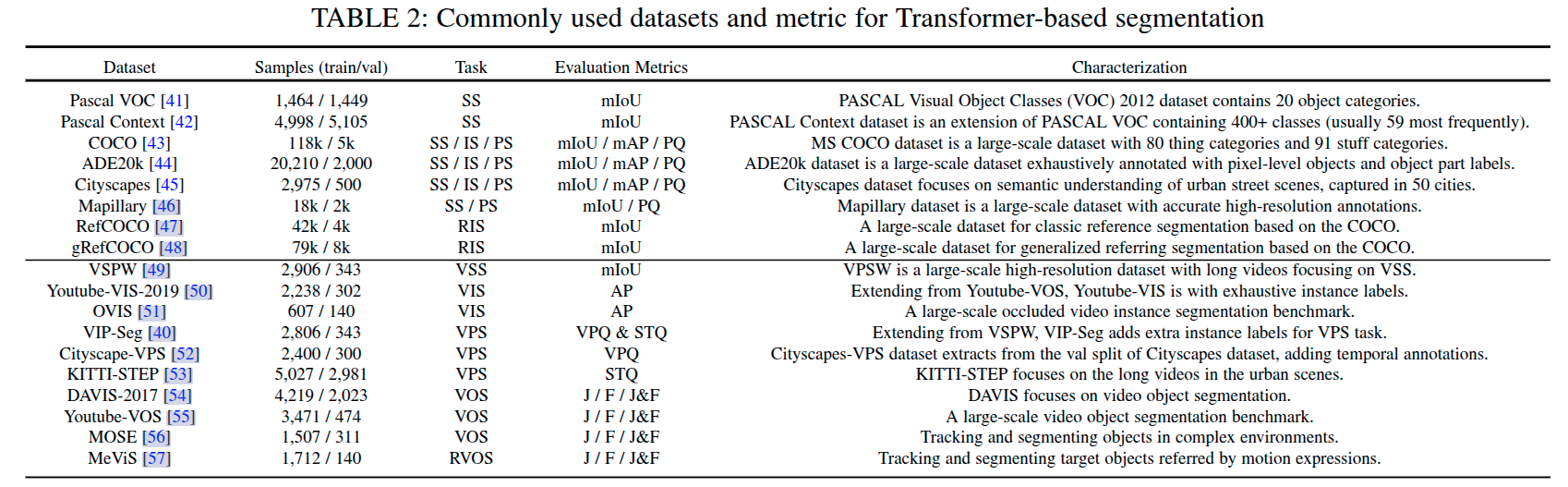
数据集
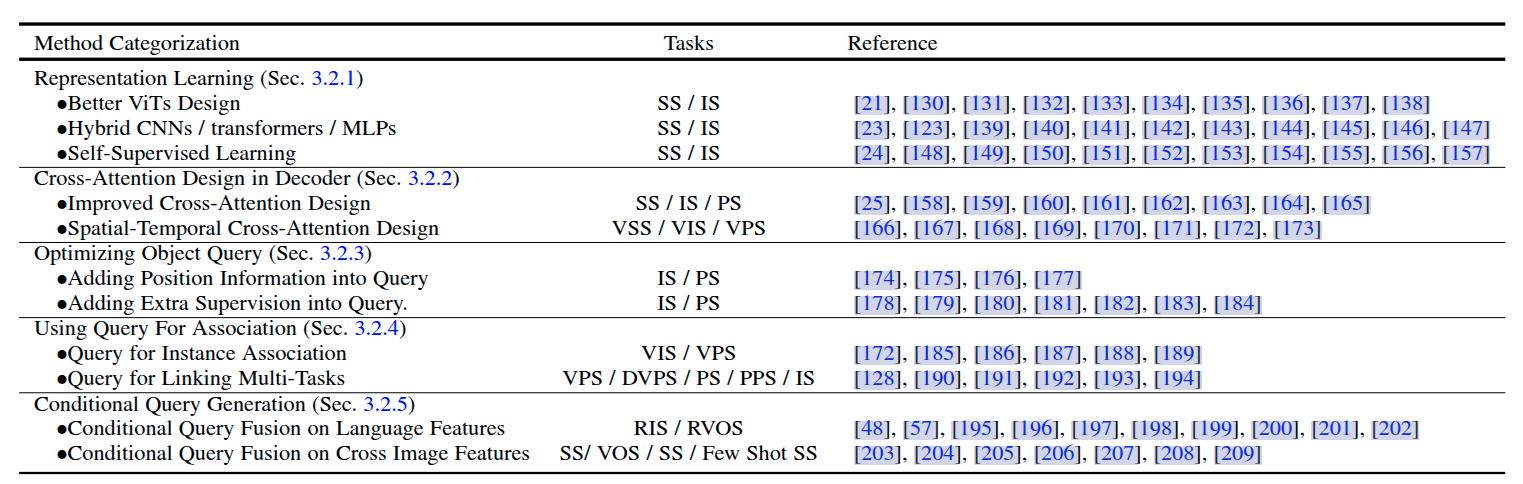
Chapter 3
DETR 目标查询(Object Query),类似于动态锚点(dynamic anchors)在实际应用中,目标查询是一个可学习的嵌入(learnable embedding)
3.1 更好的特征表达学习,Representation Learning。 强大的视觉特征表示始终会带来更好的分割结果。本文将相关工作分为三个方面:更好的视觉Transformer设计、混合CNN/Transformer/MLP以及自监督学习。
3.2 解码器端的方法设计,Interaction Design in Decoder。 本章节回顾了新的Transformer解码器设计。本文将解码器设计分为两组:一组用于改进图像分割中的交叉注意力设计,另一组用于视频分割中的时空交叉注意力设计。前者侧重于设计一个更好的解码器,以改进原始DETR中的解码器。后者将基于查询对象的目标检测器和分割器扩展到视频领域,用于视频目标检测(VOD)、视频实例分割(VIS)和视频像素分割(VPS),重点在建模时间一致性和关联性。
3.3 尝试从查询对象优化的角度,Optimizing Object Query。 与Faster-RCNN相比,DETR要更长的收敛时间表。由于查询对象的关键作用,现有的一些方法已经展开了研究,以加快训练速度和提高性能。根据对象查询的方法,本文将下面的文献分为两个方面:添加位置信息和采用额外监督。位置信息提供了对查询特征进行快速训练采样的线索。额外监督着重设计了除DETR默认损失函数之外的特定损失函数。
3.4 使用查询对象来做特征和实例的关联,Using Query For Association。 受益于查询对象的简单性,最近的多个研究将其作为关联工具来解决下游任务。主要有两种用法:一种是实例级别的关联,另一种是任务级别的关联。前者采用实例判别的思想,用于解决视频中的实例级匹配问题,例如视频的分割和跟踪。后者使用查询对象来桥接不同子任务实现高效的多任务学习。
3.5 多模态的条件查询对象生成,Conditional Query Generation。 这一章节主要关注多模态分割任务。条件查询查询对象主要来处理跨模态和跨图像的特征匹配任务。根据任务输入条件而确定的,解码器头部使用不同的查询来获取相应的分割掩码。根据不同输入的来源,本文将这些工作分为两个方面:语言特征和图像特征。这些方法基于不同模型特征融合查询对象的策略,在多个多模态的分割任务以及few-shot分割上取得了不错的结果。
1,基于Transformer的点云分割方法。2, 视觉与多模态大模型调优。3,域相关的分割模型研究,包括域迁移学习,域泛化学习。4,高效语义分割:无监督与弱监督分割模型。5,类无关的分割与跟踪。6,医学图像分割。

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









