







目录
目录

一、项目下载链接
基于 PyTorch 的图像生成模型,包含了 CycleGAN 和 pix2pix 两种模型,适合用于实现图像生成和风格迁移等任务。
论文:https://arxiv.org/pdf/1703.10593.pdf
代码:junyanz/pytorch-CycleGAN-and-pix2pix首页 - GitCode![]() https://gitcode.com/junyanz/pytorch-CycleGAN-and-pix2pix/overview junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch (github.com)
https://gitcode.com/junyanz/pytorch-CycleGAN-and-pix2pix/overview junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch (github.com)![]() https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
二、CycleGAN概述
在输入图像和输出图像之间,使用对齐图像对的训练集。但是,对于许多任务,配对训练数据将不可用。我们提出一个学习从源翻译图像的方法域 X 到目标域 Y,在没有配对的情况下例子。我们的目标是学习映射 G : X → Y使得来自 G(X) 的图像分布与使用对抗性损失的分布 Y 无法区分。由于此映射的约束非常不足,因此我们将其与逆映射 F : Y → X ,并引入强制执行 F(G(X)) ≈ X 的循环一致性损失(反之亦然)。在几个任务上呈现了定性结果不存在配对训练数据的地方,包括集合风格转移、对象变形、季节转移、照片增强等定量比较。
三、CycleGAN原理

(a) 我们的模型包含两个映射函数 G : X → Y 和 F : Y → X,以及相关的对抗函数鉴别器 DY 和 DX。DY 鼓励 G 将 X 转换为与域 Y 无法区分的输出,反之亦然用于 DX 和 F。为了进一步规范映射,我们引入了两个循环一致性损失函数,即如果我们从一个领域转换到另一个领域,然后再转换回来:(b)前向损失函数:x → G(x) → F(G(x)) ≈ x,以及 (c) 后向损失函数:y → F(y) → G(F(y)) ≈ y
四、CycleGAN的应用场景
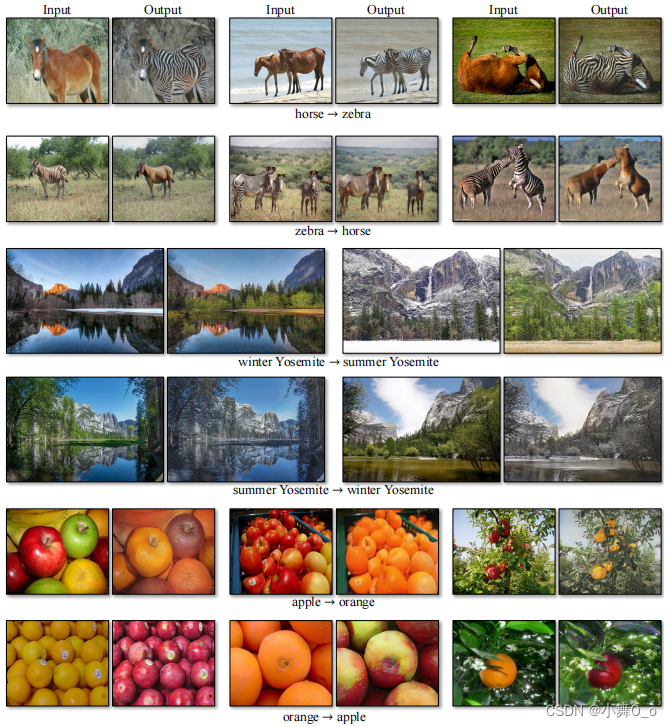
五、训练过程
(以马<——>斑马的训练过程为例)
(1)代码内容

(2) 环境配置
#操作命令:
pip install -r requirements.txt
requirements.txt内容如下:
torch>=1.4.0
torchvision>=0.5.0
dominate>=2.4.0
visdom>=0.1.8.8
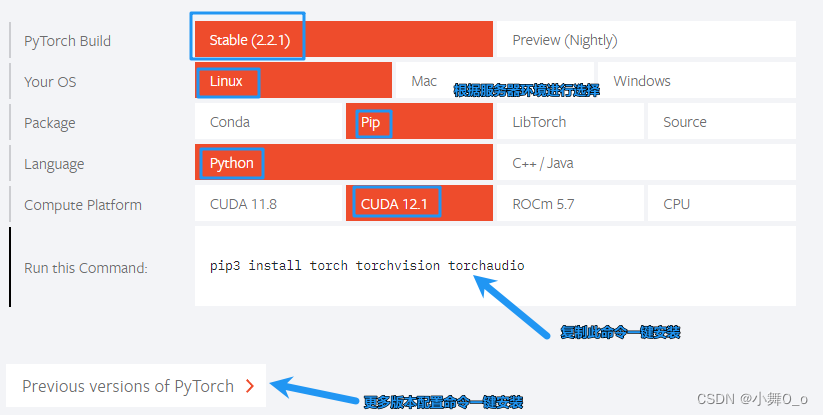
wandbtorch和torchvision安装建议直接官网配置:PyTorch
(3)预训练权重下载
进入到根目录pytorch-CycleGAN-and-pix2pix-master/下面:
运行命令:
bash ./scripts/download_cyclegan_model.sh horse2zebra下载到.//checkpoints/horse2zebra_pretrained目录下面

也可以网页直接下载:Index of /cyclegan/pretrained_models (berkeley.edu)

(4)下载训练数据
运行命令:
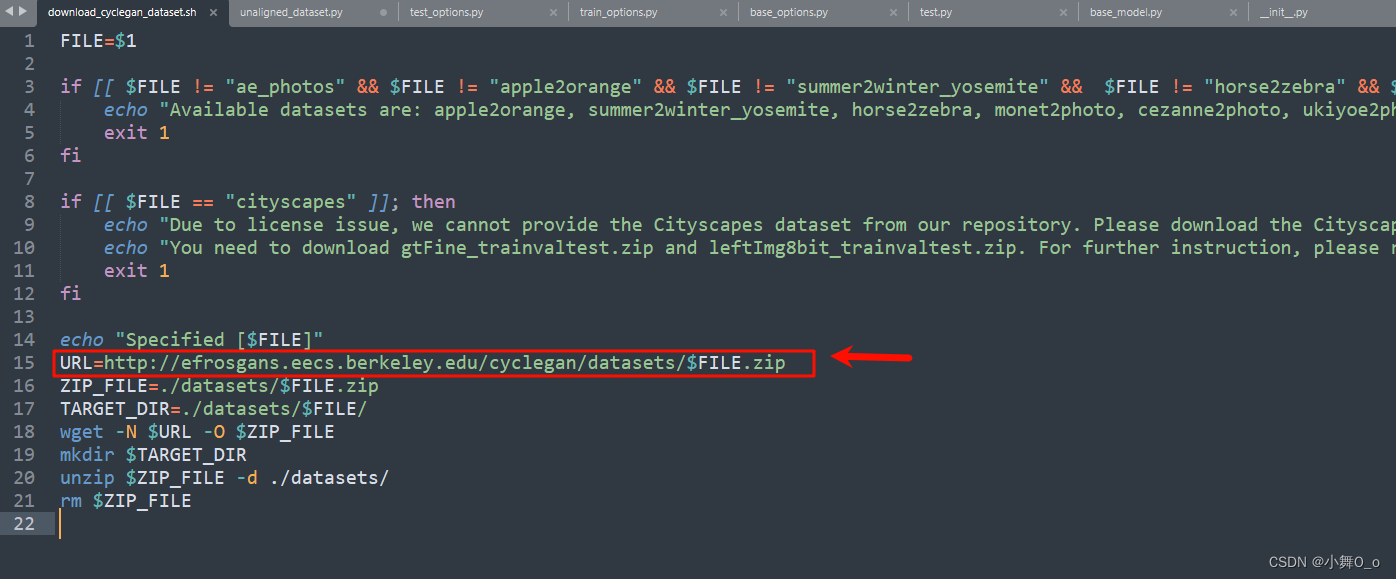
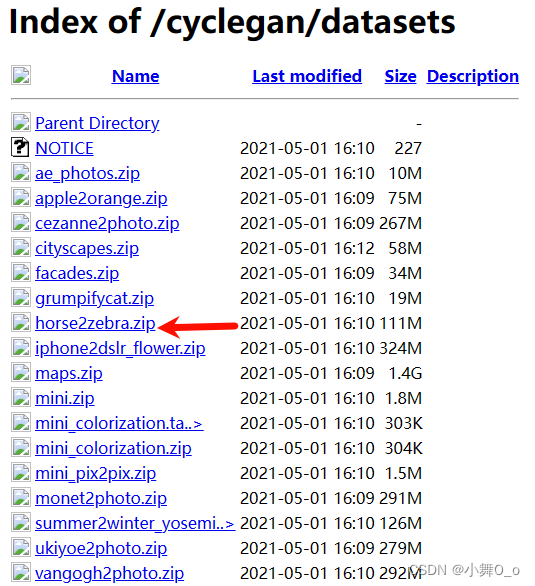
bash ./datasets/download_cyclegan_dataset.sh maps下载到:./datasets/horse2zebra目录下面

也可以直接网页下载:打开./datasets路径下的download_cyclegan_dataset文件查看到数据下载路径为:Index of /cyclegan/datasets
(5)参数设置
./options目录下
基础参数配置:base_options.py文件
def initialize(self, parser):
"""Define the common options that are used in both training and test."""
# basic parameters
parser.add_argument('--dataroot', required=True, help='path to images (should have subfolders trainA, trainB, valA, valB, etc)')
parser.add_argument('--name', type=str, default='experiment_name', help='name of the experiment. It decides where to store samples and models')
parser.add_argument('--gpu_ids', type=str, default='0,5,6,7', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
parser.add_argument('--checkpoints_dir', type=str, default='./checkpoints', help='models are saved here')
# model parameters
parser.add_argument('--model', type=str, default='cycle_gan', help='chooses which model to use. [cycle_gan | pix2pix | test | colorization]')
parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--output_nc', type=int, default=3, help='# of output image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in the last conv layer')
parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in the first conv layer')
parser.add_argument('--netD', type=str, default='basic', help='specify discriminator architecture [basic | n_layers | pixel]. The basic model is a 70x70 PatchGAN. n_layers allows you to specify the layers in the discriminator')
parser.add_argument('--netG', type=str, default='resnet_9blocks', help='specify generator architecture [resnet_9blocks | resnet_6blocks | unet_256 | unet_128]')
parser.add_argument('--n_layers_D', type=int, default=3, help='only used if netD==n_layers')
parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization [instance | batch | none]')
parser.add_argument('--init_type', type=str, default='normal', help='network initialization [normal | xavier | kaiming | orthogonal]')
parser.add_argument('--init_gain', type=float, default=0.02, help='scaling factor for normal, xavier and orthogonal.')
parser.add_argument('--no_dropout', action='store_true', help='no dropout for the generator')
# dataset parameters
parser.add_argument('--dataset_mode', type=str, default='unaligned', help='chooses how datasets are loaded. [unaligned | aligned | single | colorization]')
parser.add_argument('--direction', type=str, default='AtoB', help='AtoB or BtoA')
parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
parser.add_argument('--num_threads', default=4, type=int, help='# threads for loading data')
parser.add_argument('--batch_size', type=int, default=32, help='input batch size')
parser.add_argument('--load_size', type=int, default=286, help='scale images to this size')
parser.add_argument('--crop_size', type=int, default=256, help='then crop to this size')
parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
parser.add_argument('--preprocess', type=str, default='resize_and_crop', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')
parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data augmentation')
parser.add_argument('--display_winsize', type=int, default=256, help='display window size for both visdom and HTML')
# additional parameters
parser.add_argument('--epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
parser.add_argument('--load_iter', type=int, default='0', help='which iteration to load? if load_iter > 0, the code will load models by iter_[load_iter]; otherwise, the code will load models by [epoch]')
parser.add_argument('--verbose', action='store_true', help='if specified, print more debugging information')
parser.add_argument('--suffix', default='', type=str, help='customized suffix: opt.name = opt.name + suffix: e.g., {model}_{netG}_size{load_size}')
self.initialized = True
return parser训练参数设置:train_options.py
def initialize(self, parser):
parser = BaseOptions.initialize(self, parser)
# visdom and HTML visualization parameters
parser.add_argument('--display_freq', type=int, default=400, help='frequency of showing training results on screen')
parser.add_argument('--display_ncols', type=int, default=4, help='if positive, display all images in a single visdom web panel with certain number of images per row.')
parser.add_argument('--display_id', type=int, default=1, help='window id of the web display')
parser.add_argument('--display_server', type=str, default="http://localhost", help='visdom server of the web display')
parser.add_argument('--display_env', type=str, default='main', help='visdom display environment name (default is "main")')
parser.add_argument('--display_port', type=int, default=8097, help='visdom port of the web display')
parser.add_argument('--update_html_freq', type=int, default=1000, help='frequency of saving training results to html')
parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
# network saving and loading parameters
parser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')
parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')
parser.add_argument('--save_by_iter', action='store_true', help='whether saves model by iteration')
parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')
parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
# training parameters ##总共epoch niter+niter_decay=200轮
parser.add_argument('--niter', type=int, default=100, help='# of iter at starting learning rate')
parser.add_argument('--niter_decay', type=int, default=100, help='# of iter to linearly decay learning rate to zero')
parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
parser.add_argument('--gan_mode', type=str, default='lsgan', help='the type of GAN objective. [vanilla| lsgan | wgangp]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')
parser.add_argument('--pool_size', type=int, default=50, help='the size of image buffer that stores previously generated images')
parser.add_argument('--lr_policy', type=str, default='linear', help='learning rate policy. [linear | step | plateau | cosine]')
parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')测试参数配置:test_options.py
def initialize(self, parser):
parser = BaseOptions.initialize(self, parser) # define shared options
parser.add_argument('--ntest', type=int, default=float("inf"), help='# of test examples.')
parser.add_argument('--results_dir', type=str, default='./results/', help='saves results here.')
parser.add_argument('--aspect_ratio', type=float, default=1.0, help='aspect ratio of result images')
parser.add_argument('--phase', type=str, default='test', help='train, val, test, etc')
# Dropout and Batchnorm has different behavioir during training and test.
parser.add_argument('--eval', action='store_true', help='use eval mode during test time.')
parser.add_argument('--num_test', type=int, default=50, help='how many test images to run')
# rewrite devalue values
parser.set_defaults(model='test')
# To avoid cropping, the load_size should be the same as crop_size
parser.set_defaults(load_size=parser.get_default('crop_size'))(6)训练操作
命令:
python train.py --dataroot ./datasets/horse2zebra --name maps_cyclegan --model cycle_gan(7)训练界面

(8)训练结果
保存在:./checkpoints/maps_cyclegan文件下面

六、测试操作
(1) 测试命令
python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan 
(2)测试结果
在路径.results\maps_cyclegan\test_latest_maps下可以看到测试结果

real为原图,fake为具有原图风格的假图,rec为根据假图复原原图的图。
















 1623
1623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









