







文章目录

本文发表在AAAI-21上
论文地址:https://arxiv.org/abs/2101.00797
github:https://github.com/bdy9527/FAGCN
1. Abstract
大多数现有的GNNS 通常利用节点特征的低频信号,这就产生了一个基本的问题:在现实世界的应用中,低频信息都是需要的吗?我们首先进行了一项实验研究,评估了低频信号和高频信号的作用,结果清楚地表明,仅使用低频信号不能在不同的网络中学到有效的节点表示。
我们如何在gnn中自适应地学习更多的低频信息?我们提出了一种具有自门机制的频率自适应图卷积网络(Frequency Adaptation Graph Convolutional Network,FAGCN),该网络可以在消息传递过程中自适应地集成不同的信号。
为了更深入的理解,我们从理论上分析了低频信号和高频信号在学习节点表示中的作用,这进一步解释了为什么FAGCN可以在不同类型的网络中表现良好。在6个真实网络上的大量实验证明,FAGCN不仅缓解了过度平滑的问题,而且比最新的技术有优势
2. Introduction
- 研究低频和高频信号在gnn中的作用,并验证高频信号对于异配网络是有用的。
- 提出FAGCN,它可以在不知道网络类型的情况下自适应地改变低频和高频信号的比例。
- 理论分析FAGCN是大多数现有gnn的推广,它可以自由地缩短或扩大节点表示之间的距离。
- 做了6个真实网络的实验,FAGCN不仅缓解了over-smoothing的问题,而且比最新的技术有优势
低频和高频信号作用
一般来说,gnn通过聚合来自邻居的信息来更新节点表示,这可以看作是低通滤波器的特殊形式(Wu et al. 2019; Li et al. 2019)。低频信息,是GNN成功的关键。但是,低频信息都是有用的吗?其他信息有什么作用呢?
首先,gnn中的低通滤波器主要保留了节点特征的共性,不可避免地忽略了差异,使得学习到的连通节点表示变得相似。由于低频信息的平滑性,可以很好地用于同配网络(assortative networks),即相似节点倾向于相互连接。然而,现实世界的网络并不总是协调性的,但有时是非协调性的,即来自不同类别的节点往往会相互联系。这里的低频信息不足以支持这种网络中的推理。在这种情况下,高频信息,捕捉节点之间的差异,也许更合适。
其次,当我们总是使用低通滤波器时,节点表示将变得难以区分,导致过平滑。
以低频和高频信号为例,并通过实验来评估它们的作用。结果清楚地表明,它们都有助于学习节点表征。具体地说,我们发现当网络表现出异配性时,高频信号比低频信号表现得更好。这意味着高频信息并非总是无用的,低频信息也并非总是对复杂网络最优的。
一旦识别出gnn中低频信息的弱点,一个自然的问题就是如何在gnn中使用不同频率的信号,同时使gnn适用于不同类型的网络?
要回答这个问题,需要解决两个挑战:
- 低频和高频信号都是原始特征的部分。传统的滤波器是针对某一特定信号而设计的,不能很好地同时提取不同频率的信号。
- 即使我们可以提取不同的信息,但是现实世界网络的assortativity 通常是不可知的,变化很大,而且任务与不同信息之间的相关性非常复杂,所以很难决定应该使用哪种信号:原始特征,低频信号,高频信号或它们的组合。
FAGCN怎么设计
- 首先定义了一个增强的低通和高通滤波器,从原始特征中分离低频和高频信号。
- 然后设计一种自门机制(a self-gating mechanism),在不了解网络分类的情况下,自适应地整合低频信号、高频信号和原始特征。
3. An Experimental Investigation

inter-connection:一条边相连的两个节点属于不同类
disassortative graphs:异配图,相邻节点不属于同一类
为了使网络表现出不同的性质,将inter-connection的概率从0增大到0.10,另一个固定为0.5。
在inter-connection很低的时候(图的左侧),网络就会表现出同配性,这种情况下,low-frequency signals会表现得很好。但是随着inter-connection的增大,网络会越来越表现出异配性,这时候high-frequency signals表现更好。
- Low-frequency signals perform better on assortative graphs
- High-frequency signals perform better on disassortative graphs
所以可以得出结论,高、低频信号都有作用
具体怎么实现的?
逐步增加合成网络的异配性,并观察这两种信号的性能如何变化。我们生成一个有200个节点的网络,并将其随机分为2类。对于第一类节点,我们从高斯分布 N ( 0.5 , 1 ) \mathcal{N}(0.5,1) N(0.5,1)中采样一个20维特征向量,而对于第二类节点,高斯分布 N ( − 0.5 , 1 ) \mathcal{N}(-0.5,1) N(−0.5,1)。
此外,同一类的连接是由 p = 0.05 p= 0.05 p=0.05的伯努利分布产生的,两个类之间的连接的概率 q q q在0.01到0.1之间。
为什么会出现这种情况?

现有的GNN聚合低频信息,但是在聚合低频信息的时候,不会去考虑节点(被聚合的)和自己是不是一类的,都要使表征变得相似,这样就会带来over-smooth
当网络失配时,高频信号的有效性就出现了,但如图1(a)所示,单个滤波器不能在所有情况下都达到最优结果。FAGCN聚合同类型的低频信号,使节点趋同,但又同时不同类型的高频信号,使节点变得不同,以取得比较好的效果
4. Model
4.1 filter定义
首先要做的工作就是寻找filter ,将高、低频的信息进行分离
基于图上的拉普拉斯矩阵设计了两个滤波器:
Low-pass Filter:
F
L
=
ε
I
+
D
−
1
/
2
A
D
−
1
/
2
=
(
ε
+
1
)
I
−
L
\mathcal{F}_{L}=\varepsilon I+D^{-1 / 2} A D^{-1 / 2}=(\varepsilon+1) I-L
FL=εI+D−1/2AD−1/2=(ε+1)I−L
High-pass Filter:
F
H
=
ε
I
−
D
−
1
/
2
A
D
−
1
/
2
=
(
ε
−
1
)
I
+
L
\mathcal{F}_{H}=\varepsilon I-D^{-1 / 2} A D^{-1 / 2}=(\varepsilon-1) I+L
FH=εI−D−1/2AD−1/2=(ε−1)I+L
对于信号
x
x
x和
f
f
f:
f
∗
G
x
=
U
(
(
U
⊤
f
)
⊙
(
U
⊤
x
)
)
=
U
g
θ
U
⊤
x
f *_{G} x=U\left(\left(U^{\top} f\right) \odot\left(U^{\top} x\right)\right)=U g_{\theta} U^{\top} x
f∗Gx=U((U⊤f)⊙(U⊤x))=UgθU⊤x
如果用
F
L
\mathcal{F}_{L}
FL和
F
H
\mathcal{F}_{H}
FH代替卷积核
f
f
f:
F
L
∗
G
x
=
U
[
(
ε
+
1
)
I
−
Λ
]
U
⊤
x
=
F
L
⋅
x
F
H
∗
G
x
=
U
[
(
ε
−
1
)
I
+
Λ
]
U
⊤
x
=
F
H
⋅
x
\begin{array}{l} \mathcal{F}_{L} *_{G} x=U[(\varepsilon+1) I-\Lambda] U^{\top} x=\mathcal{F}_{L} \cdot x \\ \mathcal{F}_{H} *_{G} x=U[(\varepsilon-1) I+\Lambda] U^{\top} x=\mathcal{F}_{H} \cdot x \end{array}
FL∗Gx=U[(ε+1)I−Λ]U⊤x=FL⋅xFH∗Gx=U[(ε−1)I+Λ]U⊤x=FH⋅x

图2 滤波器的频率响应函数
原来GCN的卷积核 g θ = I − Λ g_{\theta}=I-\Lambda gθ=I−Λ,现在变为 ( ε + 1 ) I − Λ (\varepsilon+1) I-\Lambda (ε+1)I−Λ,也可以写成 g θ ( λ i ) = ε + 1 − λ i g_{\theta}\left(\lambda_{i}\right)=\varepsilon+1-\lambda_{i} gθ(λi)=ε+1−λi,如图2(a),但是当 λ i > 1 + ε \lambda_{i}>1+\varepsilon λi>1+ε, g θ ( λ i ) < 0 g_{\theta}\left(\lambda_{i}\right)<0 gθ(λi)<0,出现 negative amplitude。
所以采用二阶的卷积核 g θ ( λ i ) = ( ε + 1 − λ i ) 2 g_{\theta}\left(\lambda_{i}\right)=(\varepsilon+1-\lambda_{i})^2 gθ(λi)=(ε+1−λi)2,在图2(b)中, λ i = 0 , g θ ( λ i ) = ( ε + 1 ) 2 > 1 \lambda_{i}= 0, g_{\theta}\left(\lambda_{i}\right)=(\varepsilon+1)^2>1 λi=0,gθ(λi)=(ε+1)2>1, λ i = 2 , g θ ( λ i ) = ( ε + 1 ) 2 < 1 \lambda_{i}= 2, g_{\theta}\left(\lambda_{i}\right)=(\varepsilon+1)^2<1 λi=2,gθ(λi)=(ε+1)2<1,在二阶的低通滤波器,对低频的信号有比较好的增益,同时对高频信号有比较好的抑制。高通滤波器相反。(思考2)
卷积低频信号 F L ⋅ x \mathcal{F}_{L} \cdot x FL⋅x的具体含义是空间域内节点特征与邻域特征的和,而高频信号 F H ⋅ x \mathcal{F}_{H} \cdot x FH⋅x代表空间域内节点特征与邻域特征的差异(解释在模型的 α i j G \alpha_{i j}^{G} αijG部分和最后距离分析)
4.2 Aggregation

图 3: compare the aggregation process of existing GNNs and FAGCN
左侧是传统的GAT,只需学习一个系数 a 12 a_{12} a12,对整体的特征做一个聚合;而新模型会先用低通、高通滤波器把特征拆分成低频和高频信息,分别学习一个系数。
4.3 Problems of signal combination
上面是比较初步的版本,有一些缺点:
signal combination:

👆进行特征提取,比如让低频滤波器与特征矩阵相乘,就可以提取结点的低频信息,然后对于低频信息学习一个系数 α i j L \alpha_{i j}^{L} αijL。
- 因为滤波器是定义在图的拉普拉斯矩阵上,必须要提前知道这个整个图长什么样子,你才可以去是利用这个滤波器。
- 如果图比较大的话,矩阵乘积的运算是开销比较大的,效率可能也不会太好。
我们在谱域上,虽然解释性比较好,能看到每个节点的低频和高频的权重到底大概是怎么分配的,但是上面的缺点也是不太能接受的,因此,需要一种能自适应地聚合低频和高频信号的有效方法。所以将谱域上的方法转到空域上。
4.4 Spatial vision of FAGCN
为了达到频率适应的目的,一个基本的想法是利用注意机制来学习低频和高频信号的比例
把滤波器全部用矩阵的形式展开:
h
~
i
=
α
i
j
L
(
F
L
⋅
H
)
i
+
α
i
j
H
(
F
H
⋅
H
)
i
=
ε
h
i
+
∑
j
∈
N
i
α
i
j
L
−
α
i
j
H
d
i
d
j
h
j
\tilde{\mathbf{h}}_{i}=\alpha_{i j}^{L}\left(\mathcal{F}_{L} \cdot \mathbf{H}\right)_{i}+\alpha_{i j}^{H}\left(\mathcal{F}_{H} \cdot \mathbf{H}\right)_{i}=\varepsilon \mathbf{h}_{i}+\sum_{j \in \mathcal{N}_{i}} \frac{\alpha_{i j}^{L}-\alpha_{i j}^{H}}{\sqrt{d_{i} d_{j}}} \mathbf{h}_{j}
h~i=αijL(FL⋅H)i+αijH(FH⋅H)i=εhi+j∈Ni∑didjαijL−αijHhj
模型输入的是结点的特征
H
=
{
h
1
,
h
2
,
⋯
,
h
N
}
∈
R
N
×
F
H=\left\{\mathbf{h}_{1}, \mathbf{h}_{2}, \cdots, \mathbf{h}_{N}\right\} \in \mathbb{R}^{N \times F}
H={h1,h2,⋯,hN}∈RN×F,
F
F
F是结点的维度,
h
i
\mathbf{h}_{i}
hi是
i
i
i结点自身特征,
N
i
\mathcal{N}_{i}
Ni是结点
i
i
i邻居的集合,
d
i
d_i
di是结点
i
i
i的度,
α
i
j
L
\alpha_{i j}^{L}
αijL和
α
i
j
H
\alpha_{i j}^{H}
αijH代表结点
j
j
j对于结点
i
i
i高低频信息的比例,
整体来看, ε h i \varepsilon \mathbf{h}_{i} εhi是 i i i结点自身特征,后面是 i i i节点的邻居的一个聚合,标量实际就是聚合时边权重的系数。
4.5 系数 α i j G \alpha_{i j}^{G} αijG
两种解释
在谱域下低频、高频信号的和应该是1,
α
i
j
L
+
α
i
j
H
=
1
\alpha_{i j}^{L}+\alpha_{i j}^{H}=1
αijL+αijH=1,在这里,建模的是低频与高频信号的差值(范围
[
−
1
,
1
]
[-1,1]
[−1,1]):
α
i
j
G
=
α
i
j
L
−
α
i
j
H
\alpha_{i j}^{G}=\alpha_{i j}^{L}-\alpha_{i j}^{H}
αijG=αijL−αijH
- α i j L − α i j H \alpha_{i j}^{L}-\alpha_{i j}^{H} αijL−αijH这个差代表什么?大于0,低频主导,小于0,高频主导。学边上的权重价于低频信号和高频信号的一个比重(减下面的公式),我们之前是要分别去学它的低频线性和高频信号的值到底是多少。但是在这里,就不需要学它们的值到底是多少,只需要去建模他这个差就可以了。
- 另一种是 α i j G \alpha_{i j}^{G} αijG表示邻居结点在聚合中的系数。 α i j G > 0 \alpha_{i j}^{G}>0 αijG>0表示节点特征和邻域特征的和,即 h i + h j h_i+h_j hi+hj,而 α i j G < 0 \alpha_{i j}^{G}<0 αijG<0表示它们之间的差,即 h i − h j h_i-h_j hi−hj(正如模型刚开始分析的)。此外,当 α i j G ≈ 0 \alpha_{i j}^{G}≈0 αijG≈0时,邻居的贡献几乎为0,此时原始特征将占据节点表示的主导地位。
学习系数
α
i
j
G
\alpha_{i j}^{G}
αijG
我们需要考虑节点本身及其邻居的特征。因此,提出了一种自门机制
α
i
j
G
=
tanh
(
g
⊤
[
h
i
∥
h
j
]
)
\quad \alpha_{i j}^{G}=\tanh \left(\mathbf{g}^{\top}\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]\right)
αijG=tanh(g⊤[hi∥hj])
类似于GAT,
g
∈
R
2
F
\mathrm{g} \in \mathbb{R}^{2 F}
g∈R2F看作共享卷积核,但是没有用Softmax,而是用tanh去激活,把值限制在[-1,1]之间(其实GAT用Softmax也说明了是一种低通滤波器)
4.6 模型整体框架
我们首先使用多层感知器(MLP)对原始特征应用非线性变换。然后我们通过方程6传播这些表示。FAGCN的数学表达式定义为:
Feature transformation 对原始特征做特征变换:
h
i
(
0
)
=
ϕ
(
W
1
h
i
)
∈
R
F
′
×
1
\mathbf{h}_{i}^{(0)}=\phi\left(\mathbf{W}_{1} \mathbf{h}_{i}\right) \quad \in \mathbb{R}^{F^{\prime} \times 1}
hi(0)=ϕ(W1hi)∈RF′×1
Propagation (每次都把第一层特征加进来)
h
i
(
l
)
=
ε
h
i
(
0
)
+
∑
j
∈
N
i
α
i
j
G
d
i
d
j
h
j
(
l
−
1
)
∈
R
F
′
×
1
\mathbf{h}_{i}^{(l)} =\varepsilon \mathbf{h}_{i}^{(0)}+\sum_{j \in \mathcal{N}_{i}} \frac{\alpha_{i j}^{G}}{\sqrt{d_{i} d_{j}}} \mathbf{h}_{j}^{(l-1)} \in \mathbb{R}^{F^{\prime} \times 1}
hi(l)=εhi(0)+j∈Ni∑didjαijGhj(l−1)∈RF′×1
Classification
h
out
=
W
2
h
i
(
L
)
∈
R
K
×
1
\mathbf{h}_{\text {out }} =\mathbf{W}_{2} \mathbf{h}_{i}^{(L)} \in \mathbb{R}^{K \times 1}
hout =W2hi(L)∈RK×1
W
1
∈
R
F
×
F
′
\mathbf{W}_{1} \in \mathbb{R}^{F \times F^{\prime}}
W1∈RF×F′和
W
2
∈
R
F
×
K
\mathbf{W}_{2} \in \mathbb{R}^{F \times K}
W2∈RF×K是权重矩阵,
ϕ
\phi
ϕ是激活函数,
F
′
F^{\prime}
F′是隐藏层的维数,
l
l
l表示层数(1到L层)
FAGCN的表达能力
为什么低通滤波会让表征相似,高通滤波会让表征不同?
假设Raw feature
D
=
∥
h
u
−
h
v
∥
2
\mathcal{D}=\left\|\mathbf{h}_{u}-\mathbf{h}_{v}\right\|_{2}
D=∥hu−hv∥2
h
u
,
h
v
h_u,h_v
hu,hv是节点
u
,
v
u,v
u,v没经过滤波的原始特征,二范数表示距离
Low/High frequency:
D
L
=
∥
(
ε
h
u
+
h
v
)
−
(
ε
h
v
+
h
u
)
∥
2
=
∣
1
−
ε
∣
D
D
H
=
∥
(
ε
h
u
−
h
v
)
−
(
ε
h
v
−
h
u
)
∥
2
=
∣
1
+
ε
∣
D
\mathcal{D}_{L}=\left\|\left(\varepsilon \mathbf{h}_{u}+\mathbf{h}_{v}\right)-\left(\varepsilon \mathbf{h}_{v}+\mathbf{h}_{u}\right)\right\|_{2}=|1-\varepsilon| \mathcal{D}\\ \mathcal{D}_{H}=\left\|\left(\varepsilon \mathbf{h}_{u}-\mathbf{h}_{v}\right)-\left(\varepsilon \mathbf{h}_{v}-\mathbf{h}_{u}\right)\right\|_{2}=|1+\varepsilon| \mathcal{D}
DL=∥(εhu+hv)−(εhv+hu)∥2=∣1−ε∣DDH=∥(εhu−hv)−(εhv−hu)∥2=∣1+ε∣D
低通滤波用正权重(正权重会让低频信号做主导),让
u
,
v
u,v
u,v聚合后各自得到新的表征,此时再算距离就变成
∣
1
−
ε
∣
D
|1-\varepsilon| \mathcal{D}
∣1−ε∣D,这个值一定会小于
D
\mathcal{D}
D,也就是说,低频滤波器表征的距离一定比原始的小。
高通滤波器同理,一定会比原来的距离大。
这就证明了,低通滤波让表征变相似,高通滤波让表征有判别性。
(这里再看作者的视频)
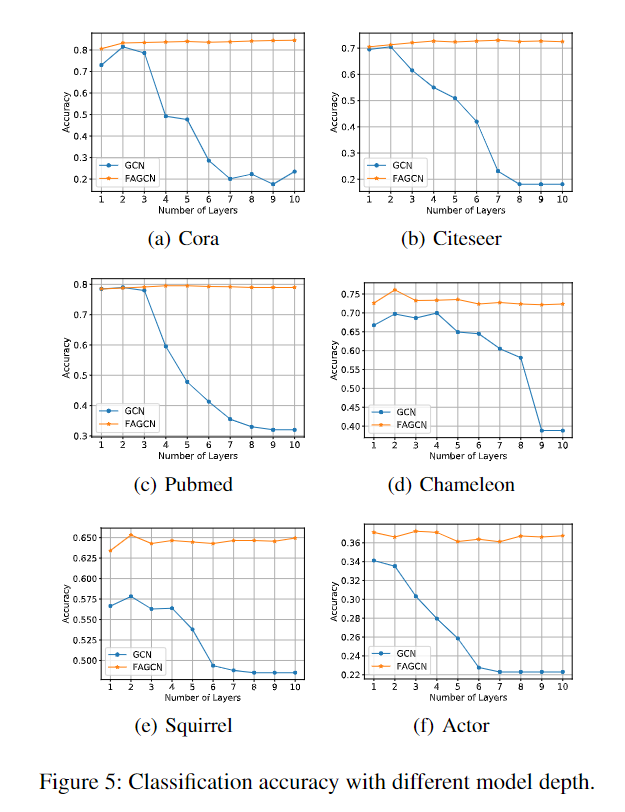
实验















 1631
1631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









