







以下为b站视频的学习笔记:
1-3为:我是土堆L:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
4为:霹雳吧啦Wz:7.2.2 使用Pytorch搭建MobileNetV3并基于迁移学习训练
1.查看数据集中图片信息
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir) # 将两个地址连接起来
self.img_path = os.listdir(self.path) # 将图片排序成一个列表
def __getitem__(self, idx):
img_name = self.img_path[idx] # 获得对应idx图片的名称
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset # 将两个数据集加起来
print(ants_dataset[0])
img, lable = ants_dataset[1]
img.show()
len(train_dataset)
其中:
img = Image.open(img_item_path):读取图片属性,查看图片大小img.size;; 显示图片img.show()
img_path = os.listdir(self.path) :将图片排序成一个表; img_path_list[0]第一张图片的名称
path.join(self.root_dir, self.label_dir) :连接文件的作用 ,将两个地址连接起来
- 打印图片类型:print(type(img))
- 打印图片shape:print(img.shape)
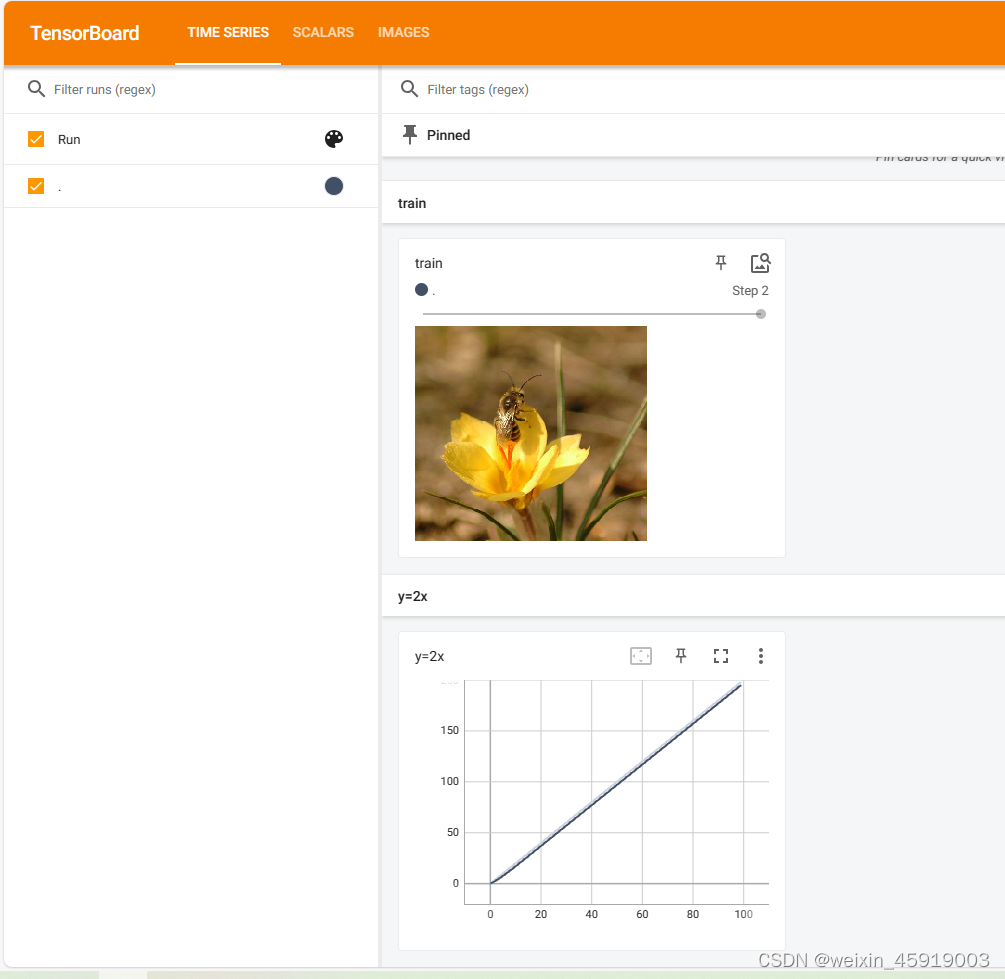
2. tensorboard 使用
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/val/bees/10870992_eebeeb3a12.jpg"
img_PIL = Image.open(image_path) # 类型是PIL
img_array = np.array(img_PIL) # PIL -> numpy 类型转换
print(type(img_array))
print(img_array.shape)
writer.add_image("train", img_array, 2, dataformats='HWC') # img_array的类型需是tensor或者是numpy或字符串
# 由于img_array的shape是(333, 500, 3)属于(H,W,3),所以需要设置dataformats
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
运行

使用PIL.Image.open()打开图片后如果要使用img.shape函数,需要先将image形式(PIL)转换成array数组
2.1 查看tensorboard
tensorboard --logdir=事件文件所在文件夹
tensorboard --logdir=logs

3. transforms的使用
对图片进行变换
3.1 数据类型从PIL转成tensor
transforms.ToTensor() :将PIL数据转换成tensor类型
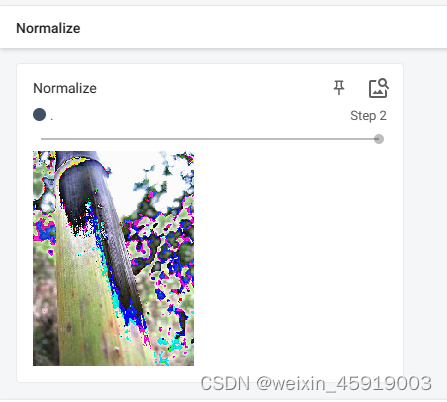
3.2 归一化
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 均值,方差,图片为RGB三通道,所以三个均值和三个方差
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("data/val/ants/8124241_36b290d372.jpg")
print(img)
# ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img) # 将PIL数据类型转换成tensor数据类型
writer.add_image("ToTensor", img_tensor) # 使用tensorboard显示名为ToTensor的图片
# Normalize
print(img_tensor[0][0][0]) # 第一层第一行第一列
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 均值,方差,图片为RGB三通道,所以三个均值和三个方差
img_norm = trans_norm(img_tensor)
# 归一化公式 output[channel] = (input[channel] - mean[channel]) / std[channel]
# (input-0.5)/0.5 = 2*input-1 input范围在[0,1],output[-1,1]
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 2)
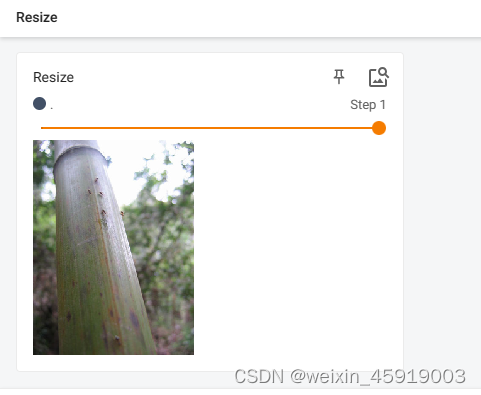
3.3 transforms.Resize((512, 512)) :改变PIL类型图片大小
# Resize使用
print(img.size)
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img) # img PIL ->resize -> img_resize PIL
img_resize = trans_totensor(img_resize) # img_resize PIL -> totensor -> img_resize tensor
writer.add_image("Resize", img_resize, 0)
print(img_resize)
3.4 transforms.Compose([trans_size_2, trans_totensor]) :将两个transform连接起来使用,但后面参数的输入与前面一个参数的输出必须匹配
# Compose -resize 2
trans_size_2 = transforms.Resize(512)
# PIL -> PIL ->tensor
trans_compose = transforms.Compose([trans_size_2, trans_totensor]) # 后面参数的输入与前面一个参数的输出必须匹配
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
3.5 transforms.RandomCrop((500, 256)) :随机裁剪
# RandomCrop 随即裁剪
trans_random = transforms.RandomCrop((500, 256))
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()

4 裁剪数据集,将数据集按照一定比列拆分为训练集和验证集
此代码来自b站up主霹雳吧啦Wz:7.2.2 使用Pytorch搭建MobileNetV3并基于迁移学习训练
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()















 2913
2913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









