







参考
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
太阳花的小绿豆:EfficientNet网络详解
EfficientNet内容
论文思想
探索了输入分辨率、网络深度、网络宽度(增加卷积核个数来增加特征矩阵的channel)的影响。最后得出同时增加宽度和深度
- 网络深度:可以获得更丰富、复杂的特征并且能很好的应用到其它任务中;但是过深会面临梯度消失,训练困难的问题。
- 网络宽度:可以获得更高细粒度的特征,并且也更容易训练;但如果网络很浅而宽度却很大会导致网络难以学习到更深层次的特征。
- 输入的图像分辨率:能潜在的获得更高细粒度的特征模板;但是对于高分辨率输入,准确率增益会减小,并且增加计算量。
利用了网络搜索技术(NAS)
结构
论文通过NAS搜索得到的EfficientNetB0结构如下
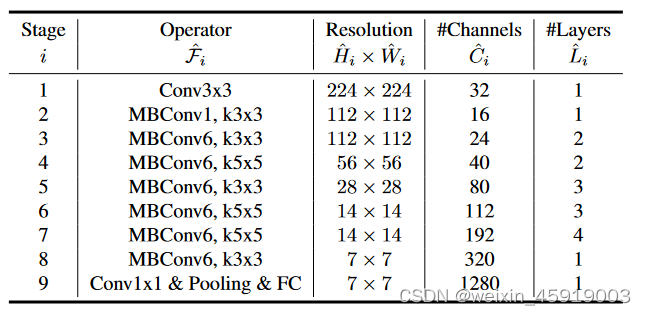
- stage分为1-9,stage1就是3x3的卷积,stage2-8再重复的堆叠MBConv(就是mobilenet的conv),stage9由1x1卷积、平均池化层和全连接层三部分组成。
- layers:为operator重复次数,如stage3,将MBConv重复两次。
- stage1-8的stride:2、1、2、2、2、1、2、1
- stage2为MBConv1,相当于是扩展倍率为1,如同MobileNet,为1时不需要第一个1x1卷积,后面的为MBConv6。
MBConv
与MobileNet中InvertedResidualBlock不同之处如下:
- 激活函数不同,efficientnet中使用的Swish;
- 在每个MBConv中加入了SE (Squeeze-and-Excitation) 模块(注意力机制)。
博主太阳花的小绿豆绘制的MBConv结构图如下:

如图所示,MBConv结构主要由一个1x1的普通卷积(升维作用,包含BN和Swish),一个k x k的Depthwise Conv卷积(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的普通卷积(降维作用,包含BN),一个Droupout层构成。
在源码中只有使用到shortcut连接(MBConv结构的输入和输出特征矩阵shape相同才存在)的MBconv模块才有dropout层。
其中SE模块由一个全局平均池化,两个全连接层组成。第一个全连接层时Swish激活函数,第二个全连接层时Sigmoid激活函数。
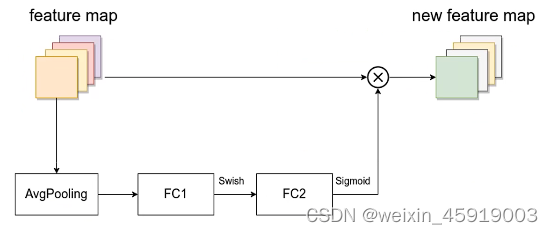
- SE模块的输入特征矩阵(dw卷积输出)的channel个数与第二个全连接层输出的channel相同,这样才能进行相乘。
- 第一个全连接层的节点个数是输入MBconv特征矩阵channel的1/4,并且使用的swish激活函数;
- 第二个全连接层的节点个数为dw卷积层输出特征矩阵channel,并且使用sigmoid激活函数。
其余EfficientNet参数设置
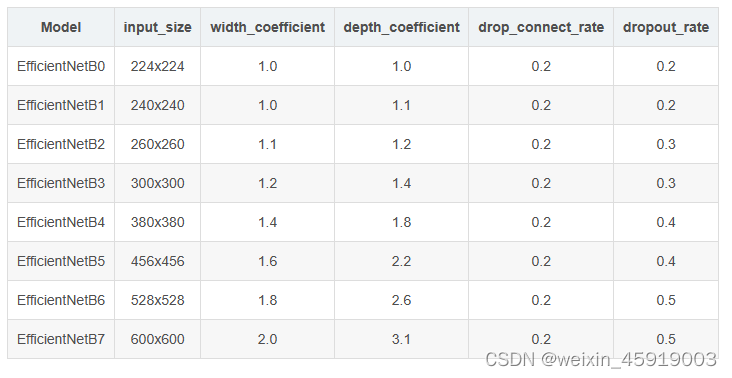
- width_coefficient:channel维度上的倍率因子,如在 EfficientNetB0中Stage1的3x3卷积层所使用的卷积核个数是32,那么在B6中就是32 × 1.8 = 57.6 接着取整到离它最近的8的整数倍即56,其它Stage同理。
- depth_coefficient:depth维度上的倍率因子(仅针对Stage2到Stage8),比如在EfficientNetB0中Stage7的Layers为 4,那么在B6中就是4 × 2.6 = 10.4 接着向上取整即11.
- drop_connect_rate是在MBConv结构中dropout层使用的drop_rate,在官方keras模块的实现中MBConv结构的drop_rate是从0递增到drop_connect_rate(在源码实现中只有使用shortcut的时候才有Dropout层)。还需要注意的是,这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。具体可参考Deep Networks with Stochastic Depth这篇文章。
- dropout_rate是最后一个全连接层前的dropout层(在stage9的Pooling与FC之间)的dropout_rate。
efficientnet准确率高,参数少,计算量少,但是非常占GPU的显存,速度慢,特别是B6,B7这些输入分辨率增加了的。
pytorch实现
定义ConvBNActivation
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # alias Swish (torch>=1.7)
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
- norm_layer为默认时设置BN,activation_layer为默认时为SiLU(swish激活函数)
SqueezeExcitation(SE模块)
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c: int, # block input channel
expand_c: int, # block expand channel
squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = input_c // squeeze_factor
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1)
self.ac1 = nn.SiLU() # alias Swish
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
self.ac2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale * x
初始化
- input_c对应的MBConv输入特征矩阵的channel;expand_c对应的第一个1 x 1卷积升维后的channel,后面的dw卷积不会改变channel;squeeze_factor:第一个全连接层节点个数=input_c / squeeze_factor
- squeeze_c 第一个全连接层节点个数
- 官方代码一般使用卷积层代替全连接层
InvertedResidualConfig(MBConv参数配置模块)
class InvertedResidualConfig:
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate
def __init__(self,
kernel: int, # 3 or 5
input_c: int,
out_c: int,
expanded_ratio: int, # 1 or 6
stride: int, # 1 or 2
use_se: bool, # True
drop_rate: float,
index: str, # 记录当前MBConv模块名称1a, 2a, 2b, ...
width_coefficient: float):
self.input_c = self.adjust_channels(input_c, width_coefficient)
self.kernel = kernel
self.expanded_c = self.input_c * expanded_ratio
self.out_c = self.adjust_channels(out_c, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
# 定义一个静态方法,根据width_coefficient调整channel
@staticmethod
def adjust_channels(channels: int, width_coefficient: float):
return _make_divisible(channels * width_coefficient, 8)
InvertedResidual模块(MBConv模块搭建)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers = OrderedDict()
activation_layer = nn.SiLU # alias Swish
# expand
if cnf.expanded_c != cnf.input_c:
layers.update({"expand_conv": ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# depthwise
layers.update({"dwconv": ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
if cnf.use_se:
layers.update({"se": SqueezeExcitation(cnf.input_c,
cnf.expanded_c)})
# project
layers.update({"project_conv": ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)})
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
# 只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and cnf.drop_rate > 0:
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result
初始化:
- 传入cnf(InvertedResidualConfig类),还传入norm_layer(BN结构)
- use_res_connect:是否使用shortcut连接(dw卷积的stride等于1,并且input_c= output_c,则使用)
- 定义一个有序的字典赋值给layers
- cnf.expanded_c = cnf.input_c就是第一个MBConv1(扩展因子为1,不需要第一个1 x 1卷积);cnf.expanded_c = cnf.input_c则直接调用ConvBNActivation。
- 然后添加dw卷积,输入输出均为expanded_c,dw卷积设置groups=cnf.expanded_c
- 接下来判断是否使用SE模块
- 最后定于最后一个1 x 1卷积,并且这个由于没有激活函数令activation_layer=nn.Identity,Identity即为不作任何处理。
- 使用Sequential将前面定义的添加到主分支block中
- 判断stride是否大于1,大于1则is_strided为true
正向传播
- 首先传入主分支block,再通过dropout
- 最后判断是否使用了shortcut分支,使用了则相加。
EfficientNet
class EfficientNet(nn.Module):
def __init__(self,
width_coefficient: float,
depth_coefficient: float,
num_classes: int = 1000,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None
):
super(EfficientNet, self).__init__()
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate, repeats
default_cnf = [[3, 32, 16, 1, 1, True, drop_connect_rate, 1],
[3, 16, 24, 6, 2, True, drop_connect_rate, 2],
[5, 24, 40, 6, 2, True, drop_connect_rate, 2],
[3, 40, 80, 6, 2, True, drop_connect_rate, 3],
[5, 80, 112, 6, 1, True, drop_connect_rate, 3],
[5, 112, 192, 6, 2, True, drop_connect_rate, 4],
[3, 192, 320, 6, 1, True, drop_connect_rate, 1]]
def round_repeats(repeats):
"""Round number of repeats based on depth multiplier."""
return int(math.ceil(depth_coefficient * repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
adjust_channels = partial(InvertedResidualConfig.adjust_channels,
width_coefficient=width_coefficient)
# build inverted_residual_setting
bneck_conf = partial(InvertedResidualConfig,
width_coefficient=width_coefficient)
b = 0 # 累计搭建MB模块的次数
num_blocks = float(sum(round_repeats(i[-1]) for i in default_cnf)) # 获取default_cnf最后一个元素,就是模块重复次数,求和得到重复MB模块的次数
inverted_residual_setting = []
for stage, args in enumerate(default_cnf):
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))): # 遍历每一个stage中的MBConv模块,然后将cnf中每一行最后一个元素pop出来,列表中就没有最后一个元素
if i > 0:
# strides equal 1 except first cnf
cnf[-3] = 1 # strides
cnf[1] = cnf[2] # input_channel equal output_channel
cnf[-1] = args[-2] * b / num_blocks # update dropout ratio
index = str(stage + 1) + chr(i + 97) # 1a, 2a, 2b, ...
inverted_residual_setting.append(bneck_conf(*cnf, index))
b += 1
# create layers
layers = OrderedDict()
# first conv
layers.update({"stem_conv": ConvBNActivation(in_planes=3,
out_planes=adjust_channels(32),
kernel_size=3,
stride=2,
norm_layer=norm_layer)})
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.update({cnf.index: block(cnf, norm_layer)})
# build top
last_conv_input_c = inverted_residual_setting[-1].out_c
last_conv_output_c = adjust_channels(1280)
layers.update({"top": ConvBNActivation(in_planes=last_conv_input_c,
out_planes=last_conv_output_c,
kernel_size=1,
norm_layer=norm_layer)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_rate > 0:
classifier.append(nn.Dropout(p=dropout_rate, inplace=True))
classifier.append(nn.Linear(last_conv_output_c, num_classes))
self.classifier = nn.Sequential(*classifier)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
初始化
- 参数:dropout_rate对应的stage9中FC层前面dropout随机失活比例;drop_connect_rate对应MBConv模块中dropout层随机失活比例 ; block:MBConv模块;
- 构建一个stage2-8的参数的表,默认都使用SE模块,因此为true
- 定义的round_repeats用来给模块重复次数repeats向上取整
- norm_layer通过partial将参数eps和momentum传递给BN;adjust_channels同理
- 第一个for循环使用enumerate遍历default_cnf得到返回数据的同时得到索引,stage, args。使用copy.copy对数据args进行复制赋值给cnf,在后期修改时不改变原数据
- 第二个for循环遍历每一个stage中的MBConv模块,然后将cnf中每一行最后一个元素pop出来,列表中就没有最后一个元素
- 更新dropout ratio:从0开始随着MBConv堆叠次数越来越多而变得越来越大,不过达不到0.2,这是因为b最后只到num_blocks-1。
- index:MBConv模块顺序,stage=0时对应的efficientnet结构表中stage2,后面i=0时97相当于a,i=1时就是b。也就是说stage2中第一个MBConv编号为1a,第二个为1b;stage3中第一个MBConv编号为2a
- 然后将每一个MBConv得到的配置cnf文件以及对应的index传入bneck_conf,也就是传入构建的InvertedResidualConfig类,然后通过append将获得的一系列参数添加到前面定义的inverted_residual_setting列表中
- 前面两个for循环就搭建出来了所有MBConv模块的配置信息
- 定义特征提取部分:创建一个layer,还是通过有序字典来构建
- 首先构建stage1,命名为stem_conv,输入chanel为3(RGB)
- 构建stage2-8:遍历配置文件列表inverted_residual_setting,命名就是用前面index配置的,通过这个for遍历就可以搭建所有MBConv模块
- 最后搭建stage9:调用最后一个MBConv模块的输出特征矩阵channel,赋值给last_conv_input_c,输出为adjust_channels(1280),命名为top。
- 将所有的layers 通过Sequential类就可以实例化,并得到self.features(就是stage1-8加上stage9中的卷积层)
- 定义分类器部分
- dropout_rate>0说明是需要dropout层,实例化后添加到classifier列表中,再添加一个全连接层(输入为last_conv_output_c,输出为分类类别个数)
- 最后通过Sequential类实例化得到self.classifier
正向传播:
- 先通过特征提取
- 然后最大池化
- 展平
- 通过分类器
通过EfficientNet类实现EfficientNet_b0-b7
def efficientnet_b0(num_classes=1000):
# input image size 224x224
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.0,
dropout_rate=0.2,
num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
# input image size 240x240
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.1,
dropout_rate=0.2,
num_classes=num_classes)

















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









