







参考网址:
一、定义:
程序定义的数据都要存放到内存中,如果数据起始的内存地址是自身长度的整数倍那么该数据的内存是对齐的。
二、为什么要内存对齐?
内存对齐会使得数据的读写效率相比于非内存对齐高效很多。
例子:
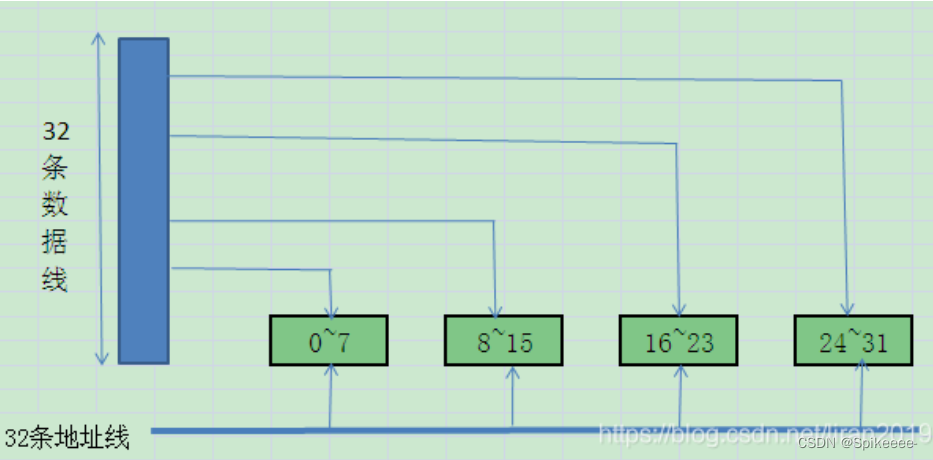
如32位的cpu它的数据总线是32位,每次cpu都会读取4个字节的数据。cpu会根据地址总线确定读取的位置。
如果数据排布是左边这种情况(非内存对齐),那么cpu需要通过数据总线读取两次,才能获得完整的数据。
如果数据排布是右边这种情况(内存对齐),那么cpu只需要读取一次就可以获得完整的数据。

三、对齐规则:
- 第一个成员在与结构体偏移量为0的地址处。
- 其他成员变量要对齐某个数字(对齐数)的整数倍地址处。
注:对其数 = 编译器默认的对齐数(VS为8)与该成员大小的较小值。- 结构体的总大小:最大对齐数(Min{结构体内最大变量类型, 编译器默认对其参数})的整数倍。
- 如若结构体内嵌套有结构体,则将嵌套结构体当作一个单独变量类型计算(3步骤)。
四、演示样例:
例1:
class A1
{
int a;
char b;
}
计算类A1时,大小并不是4+1=5字节,是因为变量a占据了4个字节,变量b占据一个字节,此时为5个字节。
遵循对齐原则中的第三条:
默认对齐数为8,所有变量类型最大者是int型为4,4的整数倍为8,所以类A1的字节大小为8。
例2:
class A2
{
char b;
int a;
}
计算类A2时,char类型变量b的大小为1,占据在结构体偏移量为0的地址处,重点在于int a变量,它并不是在char类型后直接就占据了地址,int a变量在开辟空间的时候,遵循对齐原则中的第二条:
他认为内存空间是为自己开辟的,所以存放的位置是在自己宽度的整数倍上开始的。
| 地址 | 类型名 |
|---|---|
| 0 | a(char) |
| 1 | |
| 2 | |
| 3 | |
| 4 | b(int)01 |
| 5 | b(int)02 |
| 6 | b(int)03 |
| 7 | b(int)04 |
例3:
class A3
{
char a;
double b;
int c;
}
计算A3时,可能会根据前面的A2计算方法计算出为8+8+4=20,但是实际结果是24,原因还是要遵循最大对齐数的整数倍,最大对齐数为double型为8字节,20不是8的整数倍,所以要向后延续到24字节。
| 地址 | 类型名 |
|---|---|
| 0 | a(char) |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | b(double)01 |
| 9 | b(double)02 |
| 10 | b(double)03 |
| 11 | b(double)04 |
| 12 | b(double)05 |
| 13 | b(double)06 |
| 14 | b(double)07 |
| 15 | b(double)08 |
| 16 | c(int)01 |
| 17 | c(int)02 |
| 18 | c(int)03 |
| 19 | c(int)04 |
| 20 | 补齐至3*8=24 |
| 21 | 补齐至3*8=24 |
| 22 | 补齐至3*8=24 |
| 23 | 补齐至3*8=24 |















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









