









[2022]李宏毅深度学习与机器学习课程内容总结
课程感受
没有想到自己可以完整的看完李宏毅老师的深度学习课程,并且坚持做笔记,这里给自己鼓掌。李宏毅老师讲课风格幽默有趣,让人可以全神贯注的听课。老师讲的课程内容注重基础的同时结合了很多最近几年的论文,非常有深度,让人眼前一亮。整体听完感觉自己收获了很多,所以在这里总结一下课程涉及到的知识内容。
第一讲必修
ML的三个步骤
第一讲选修
深度学习发展趋势
反向传播
从线性模型到神经网络
为什么要用正则化技术
为什么分类是用交叉熵损失函数而不是Square Error
Discriminative Vs Generative
第二讲必修
机器学习的任务攻略
在训练集上损失较大时
应该过拟合的方法
N-fold Cross Validation
local minima 和 saddle point
Small Batch vs Large Batch
Warm up
SGDM优化器
Adagrad
Adam
浅谈机器学习的原理——为什么参数越多越容易overfitting
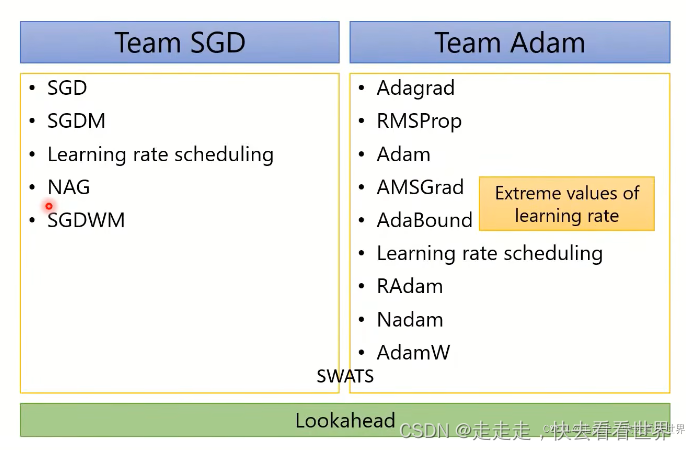
第二部分选修
SGD
SGDM
Adagrad
RMSProp
Adam
Adam vs SGDM
AMSGrad和AdaBound
RAdam
K-step forward,1 step back
正则化在优化里的应用如果
第三讲CNN
如何理解CNN
整体架构
Spatial Transformer
Deep learning 让鱼和熊掌兼得
解释为什么是deep learn而不是wide learn
第四讲必修Self-attention
Self-attention的具体实现
Self-attention的应用
Self-attention vs CNN
Self-attention vs RNN
Self-attention for Graph
第四讲选修GNN 和 RNN
为什么需要GNN
NN4G
DCNN
MoNET
GTA
GIN
RNN介绍
为什么RNN一开始训练不起来
LSTM
GRU
各式各样的Self-attention















 2063
2063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









