









[2022]李宏毅深度学习与机器学习第三讲(选修和必修)听课笔记
做笔记的目的
1、监督自己把50多个小时的视频看下去,所以每看一部分内容做一下笔记,我认为这是比较有意义的一件事情。
2、路漫漫其修远兮,学习是不断重复和积累的过程。怕自己看完视频不及时做笔记,学习效果不好,因此想着做笔记,提高学习效果。
3、因为刚刚入门深度学习,听课的过程中,理解难免有偏差,也希望各位大佬指正。
CNN
如何理解CNN
Neuron Version Story
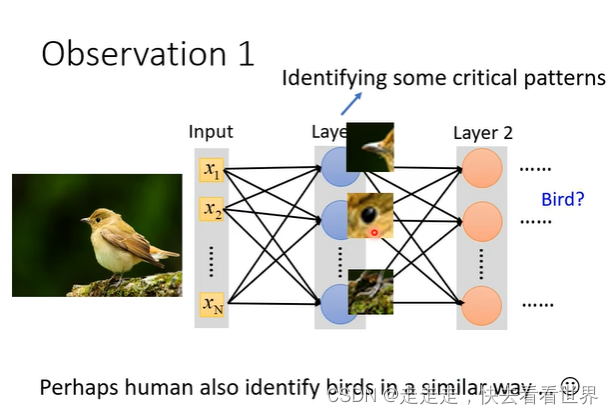
我们看这张图片是否是鸟,主要看的是一些局部信息就可以判断。之前说过全连接的弹性非常大,所以为了让架构的弹性变小,可以让每个神经元只连接一些信息,这样神经元就只关注了局部信息。


receptive field可大可小,同时也可以只考虑某个channel,也可以不是正方形。
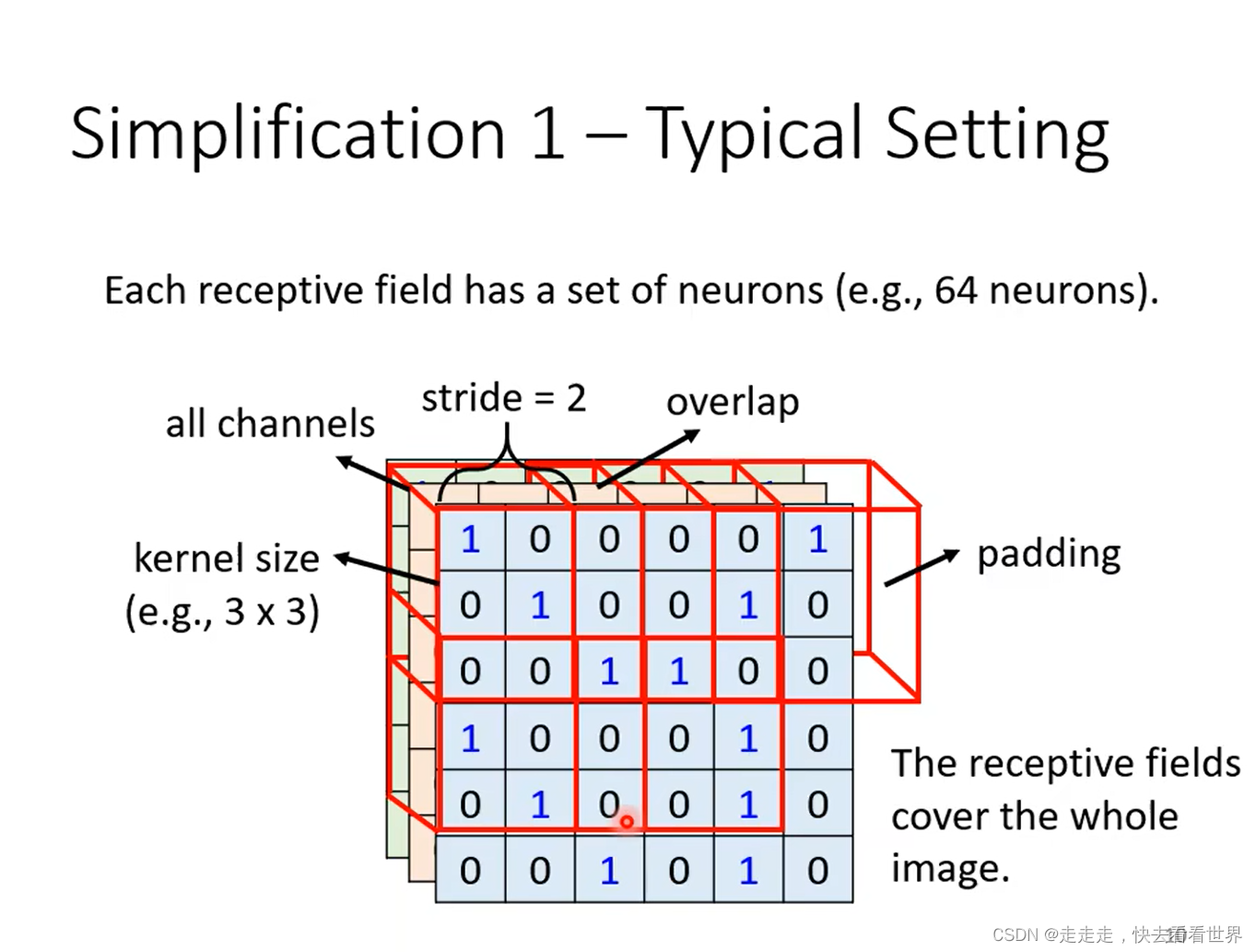
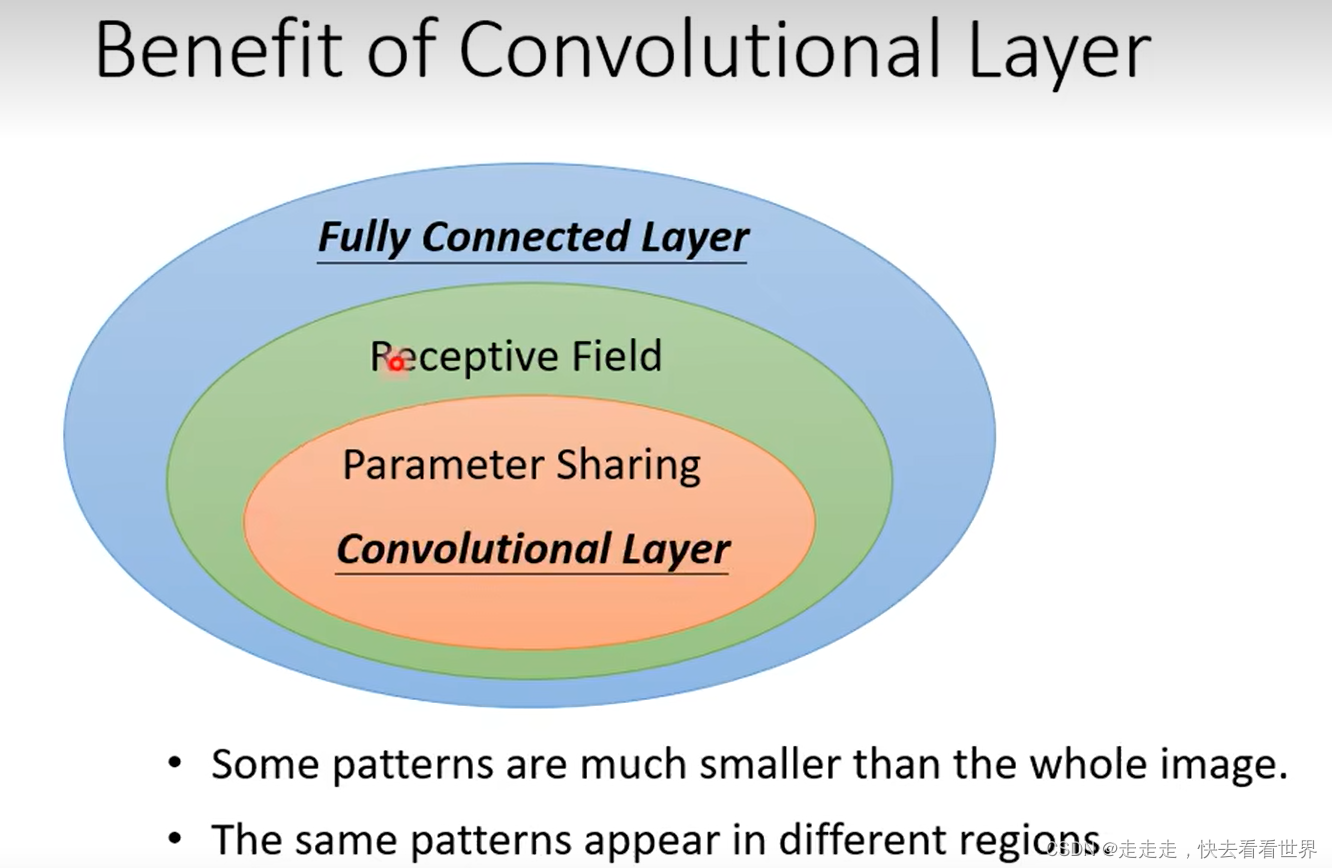
特征可能会在不同的地方,这样可能就会出现重复工作,所以可以通过共享参数来让模型变小,防止过拟合,这样就可以限制模型弹性了

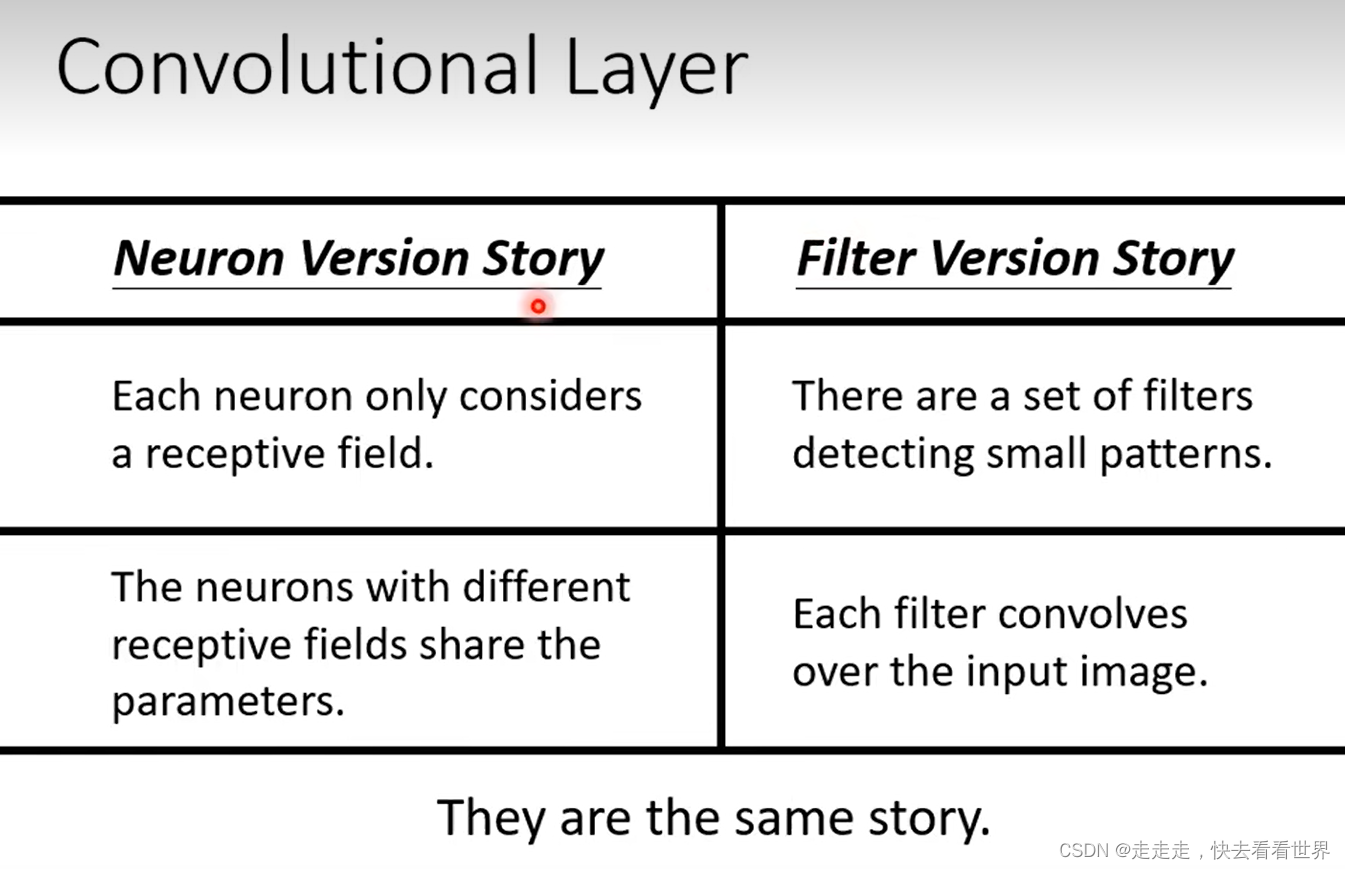
Filter Version Story
用Filter去抓取pattern

两种解释都是一个故事,不同角度
pooling

把大的图片缩小,不会影响图像的改观,所以可以用pooling来减少计算复杂度,也可以理解为图像去掉奇数行,把偶数行拼接在一起之后,图像变化不是很大。所以现阶段计算能力比较强,所以pooling在很多工作中被删除了。同时pooling在一些特定领域也不会被用到,比如围棋,因为围棋缩小之后,就变了。
整体架构
CNN的经典架构
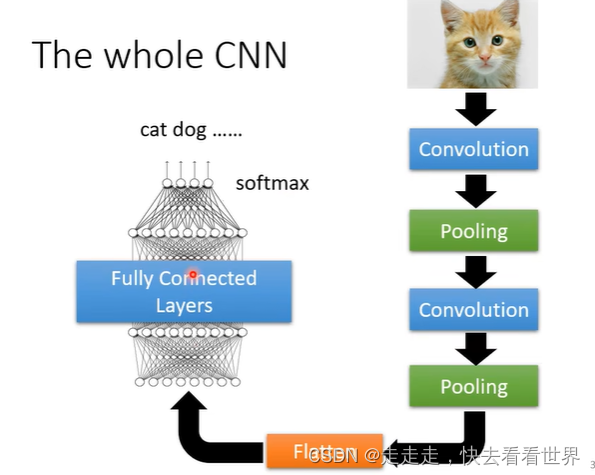
CNN的应用
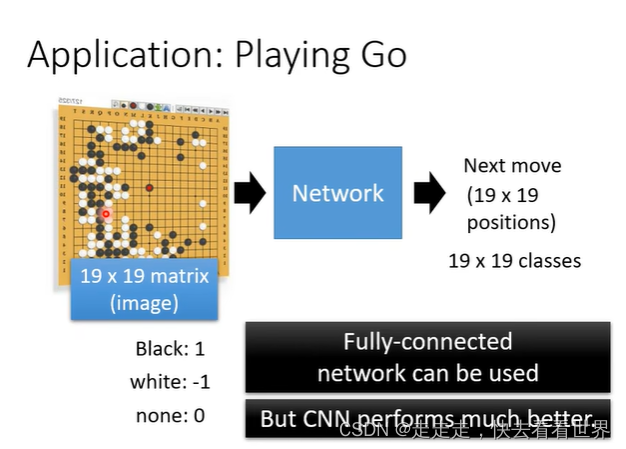
因为不符合用pooling的条件,所以就没有用pooling,他的结构如下图,所以就可以看到没有pooling层,以后在具体应用中也要注意要不要用pooling。

虽然CNN已经很强大了,但是仍然有不足,比如不能应对图片的放缩和旋转问题,所以需要进行改进。

Spatial Transformer
特别的但是有用的架构
CNN不能处理图像的旋转和放缩(数据增量可以一定程度解决这一点),所以Spatial Transformer Layer 就是加在CNN的前面,提取出感兴趣的特征,在放进CNN里面。
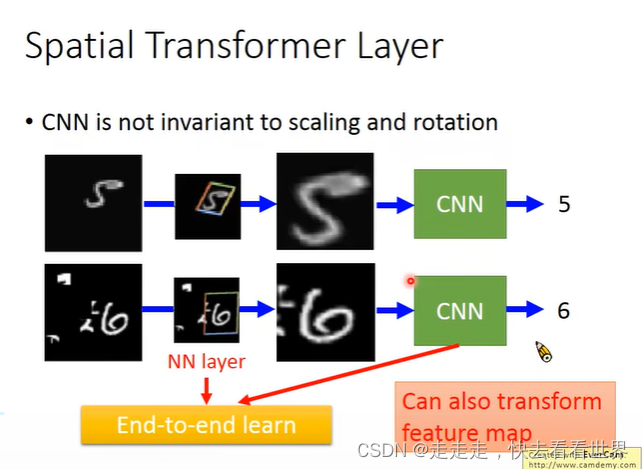

weight做不同的设计,就可以实现旋转缩放,让其变成矩阵运算,然后放到网络里去学习。
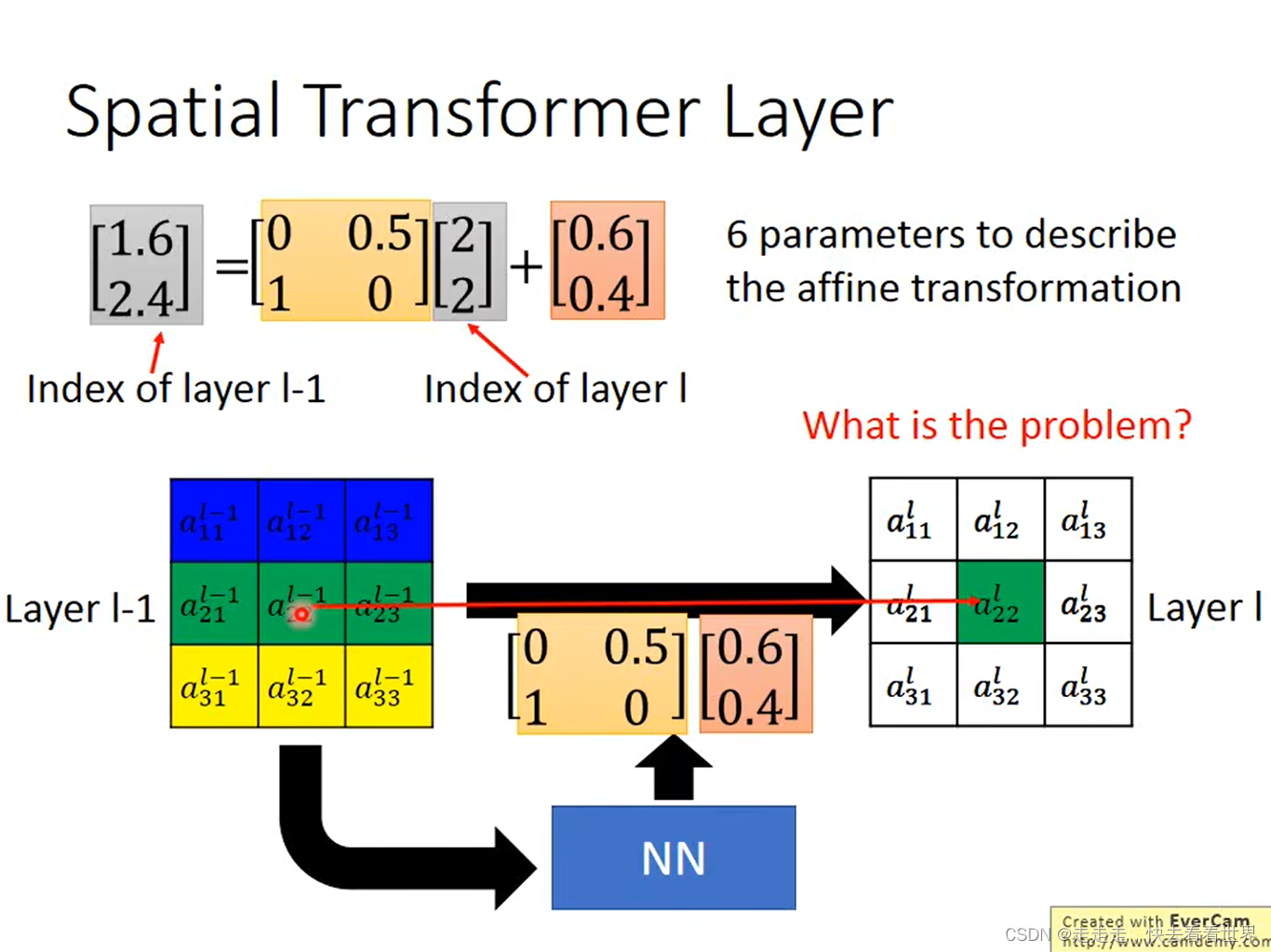
算出的结果可能是小数,如何四舍五入就不能微分,所以按照下面做,用四个值来近似。
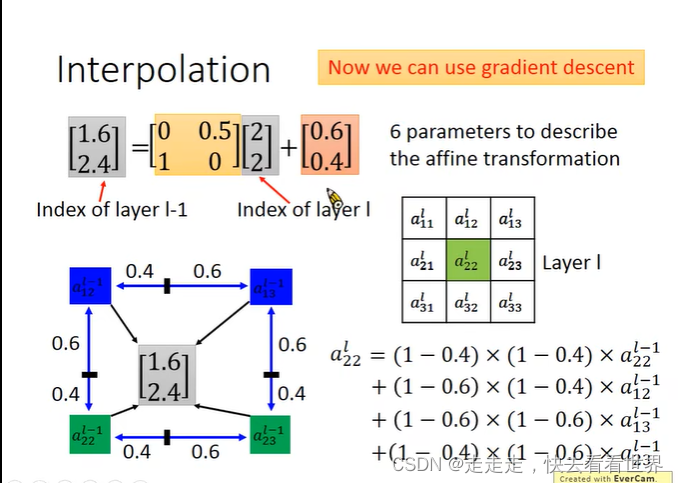
这一项技术不止可以用在CNN前面,其实也可以用在别的地方,甚至两个一起用,生成两个框,来进行识别。

一些例子
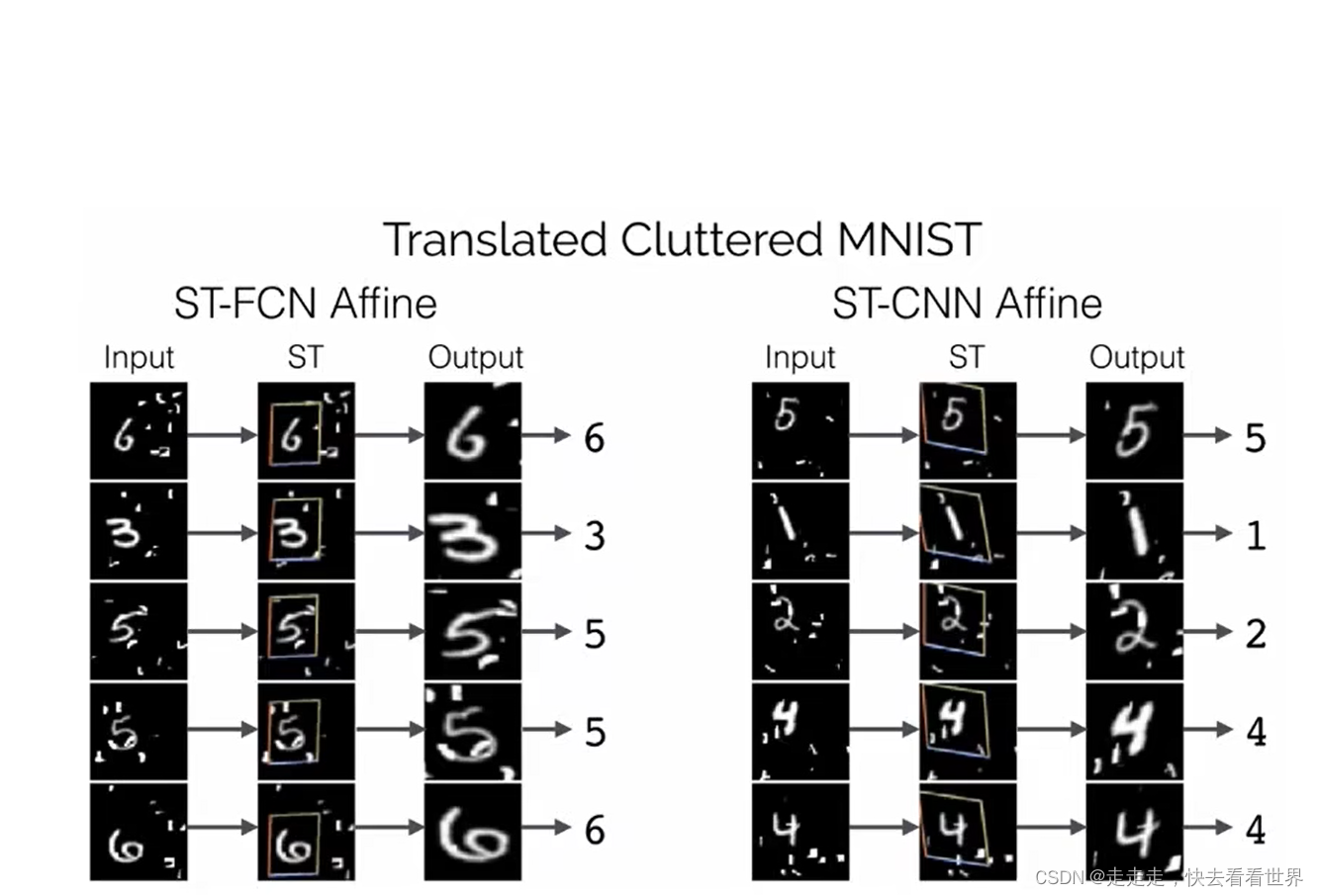
两个框
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









