









做笔记的目的
1、读完了论文,做一下笔记让自己别忘的那么快
2、蹭一波热度(好像有点晚了)
3、这是第一次看纯工程论文,所以做一下笔记
介绍
大的自然语言模型,在自然语言处理任务上展现出了强大的能力,但难以处理视觉任务。同时大的视觉模型在特定的任务上表现的非常好,但受限于输入输出格式等等不如语言模型一样灵活。对于如何让ChatGPT支持多模态聊天这个问题,比较直观的想法是训练一个多模态聊天模型,但是这样做需要耗费大量的数据和计算资源,同时可拓展性也不高。因此作者从Prompt工程出发,构建了Visual ChatGPT,将ChatGPT和22个视觉模型一起包在一个壳里面,组成了Visual ChatGPT。
论文贡献
- We propose Visual ChatGPT, which opens the door of combining ChatGPT and Visual Foundation Models and enables ChatGPT to handle complex visual tasks;
- We design a Prompt Manager, in which we involve 22 different VFMs and define the internal correlation among them for better interaction and combination;
- Massive zero-shot experiments are conducted and abundant cases are shown to verify the understanding and generation ability of Visual ChatGPT.
Visual ChatGPT
总体框架

整体框架如上图所示,就是在query输入ChatGPT之前添加一些Prompt来让ChatGPT能够知道要掉用什么模型。
首先输入的是系统准则P,主要包括:
- 系统是Visual ChatGPT能够调用很多视觉模型
- Visual ChatGPT对文件命名非常严格(帮助系统区分图片文件)
- 定义推理格式
- 忠于图片内容不乱扯
- Chain-of-Thought,让模型能够连续处理视觉问题
**
M(F)是关于视觉模型的描述:
1.名字
2.用法
3.输入输出格式
大概的样子长这样

M(Q)是对query进行处理:
- 产生唯一的文件名(帮助ChatGPT根据名字区分不同图片)
- 让Visual ChatGPT强制思考需不需要调用VFM
M
(
F
(
A
i
(
j
)
)
)
M(F(A_i^{(j)}))
M(F(Ai(j)))是对模型返回的结果进行处理
1.首先是定义了链式命名(让模型知道这个图片由哪张图片变过来,做了什么,可以让模型知道还需不需要调用VFM)
2.Call for more VFMs,让Visual ChatGPT自动的调用更多的VFM,来完成多个视觉相关指令。
总体流程
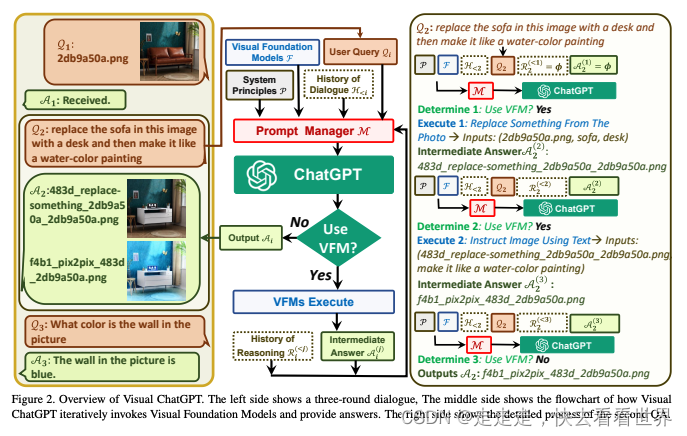
每次输入的P和F是相同的,历史对话是直接加进去和历史reasoning都是直接加进去的。当输入
Q
2
Q_2
Q2时由于还没有进行推理,也没有调用语言模型所以
R
2
(
<
1
)
R_2^{(<1)}
R2(<1)和
A
2
1
A_2^{1}
A21都等于
ϕ
\phi
ϕ。将Prompt输入ChatGPT输出,判断输出的内容是需要调用模型,并且ChatGPT会自动将要调用的模型名字和输入输出的样式给出,之后自动化调用VFM就可以。完成第一次后,更新
R
2
(
<
1
)
R_2^{(<1)}
R2(<1)和
A
2
1
A_2^{1}
A21,在输入到ChatGPT中,第二次也需要调用VFM,因此重复上面的步骤。当ChatGPT判断不需要VFM的时候就输出结果,一次Visual ChatGPT的调用就结束了。可以看到一次Visual ChatGPT的调用可能涉及多次ChatGPT的调用。
实验
使用的ChatGPT模型是“text-davinci-003“,使用的视觉模型是从HuggingFace Transformers,Maskformer 和ControlNet 上收集的。
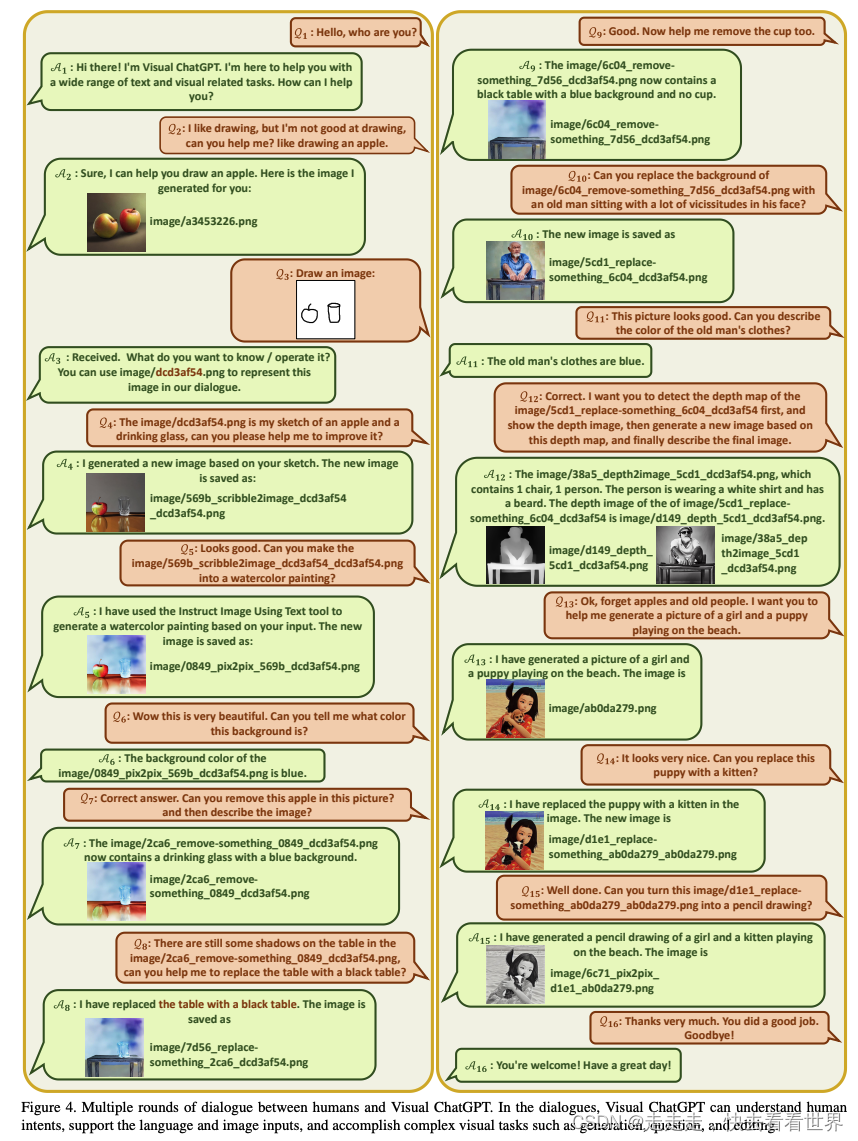
实验主要是验证了总体框架中的每个部分都不少,不然Visual ChatGPT可能工作的不是很好。下面是Visual ChatGPT的对话实例:
下面这张图证明了P的每一个部分都很有必要

下面这张图证明了M(F)的名字、用处、输入输出格式很重要,样例可有可无;

下面这种图证明了剩下的部分设计的很有必要

限制
- Dependence on ChatGPT and VFMs 模型的效果依赖于ChatGPT模型效果和VFMs模型的效果
- Heavy Prompt Engineering 需要大量的Prompt工作
- Limited Real-time Capabilities 由于ChatGPT没有实时能力,Visual ChatGPT当然也没有这个能力
- Token Length Limitation ChatGPT的token限制让这个系统不能无限制的加入模型,同时由于输入了很多Prompt,可能query并不能很长。
- Security and Privacy 可能有隐私问题
总结
在这项工作中,我们提出了Visual ChatGPT,这是一个集成了不同VFM的开放系统,使用户能够超越语言格式与ChatGPT进行交互。构建这样一个系统,我们精心设计了一系列提示帮助将视觉信息注入ChatGPT从而可以逐步解决复杂的视觉问题。大量实验和选定的案例已经证明Visual ChatGPT的巨大潜力和能力不同的任务。除了上述限制之外,另一个令人担忧的问题是,由于VFM的故障和促使因此,一个自校正模块对于检查执行结果与人类意图之间的一致性,并相应地做出编辑。这种自我纠正行为会导致更多模型的复杂思维,显著增加推理时间。我们将来会解决这样一个问题。















 4098
4098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









