









摘要
SimCLR论文下载:
https://arxiv.org/pdf/2002.05709.pdf
MOCO论文下载:
https://arxiv.org/pdf/1911.05722.pdf
简单做一些笔记然后介绍一下
SimCLR
大概的框架如下:
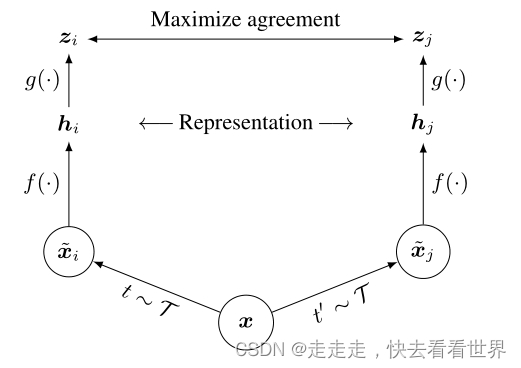
流程如下:
流程
框架是由一个数据增强模块、基于神经网络的编码器f()、小型神经网络投影投g()、对比损失

论文结论
-
大的Batch结果会比较好,模型越大数据越多,结果同样也会更好
-
作者比较系统的做了数据增强的实验,结果如下图
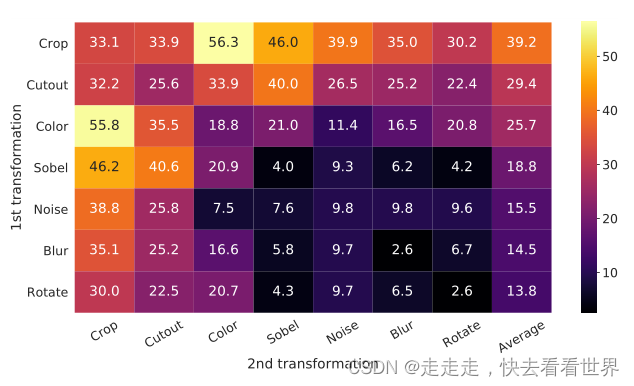
可以看到随机裁剪和颜色失真对对比学习来说比较重要。同时更广泛的数据增强组合可以进一步提升模型性能。 -
对于无监督学习(SimCLR)颜色失真比较重要,但是对于监督学习颜色失真显得不那么重要(甚至起到了负面效果),实验结果如下图:
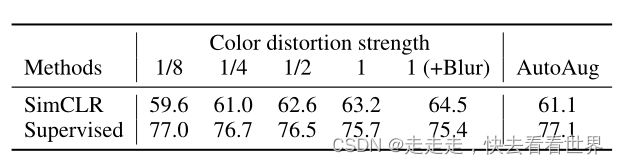
这个论文也证明了,尽管一些数据增强的方法对于监督学习没有帮助,但是可能对于无监督学习非常有用。具体来说g()被训练为对数据变化不变,因此 -
非线性投影头提高了之前图层的表示质量
非线性投影比线性投影结果好3%、比没有投影好了10%。同事投影前的向量比投影后的向量结果也要好10%。这就表明,非线性投影层的必要性,以及投影头前面的隐藏层的特征比投影头后面的层的特征更好。作者猜想这是由于对比损失引起的。以下是t-SEN图片。

MOCO
大体框架是下图的C
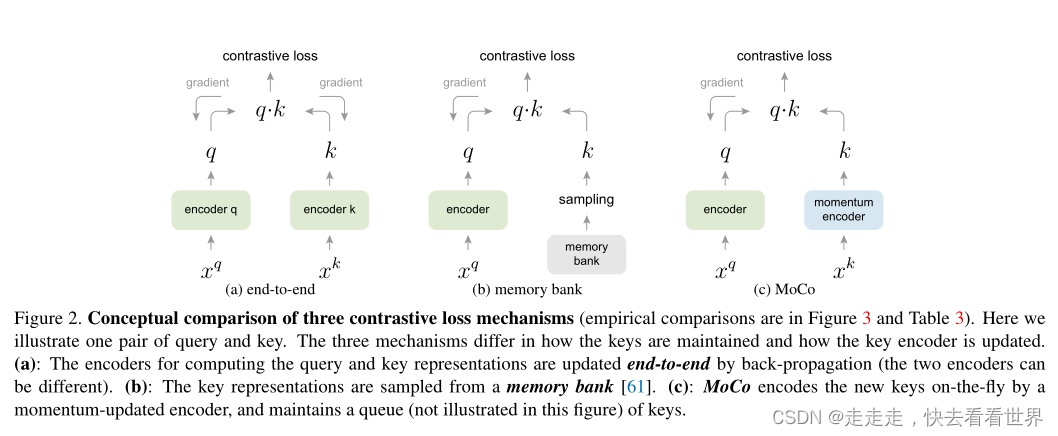
作者认为现阶段的对比学习大多受限于字典长度(a)或者字典内的一致性差(b),因此作者提出了MOCO,让字典大的同时保存了字典内向量的一致性。
补充一下(b)memory bank方法:从memory bank中sampling样本,计算对比损失后更新模型,之后在重新计算sampling样本的特征向量,用这些特征向量去更新memory bank中对应的特征向量。这样做的坏处是mempry bank内的特征一致性非常差,好处是字典变得非常大。Kaiming大神把a方法和b方法很好的结合了起来。利用动量更新momentum encoder让他变化的非常慢,同时训练过程中维持一个队列,每个最新的mini-batch数据进入队列,最旧的数据出队列,保持dictionary的large和consistent特性。
Momentum update的公式如下:

其中m=0.999时效果比较好。这篇论文里的对比损失采用的是infoNCE
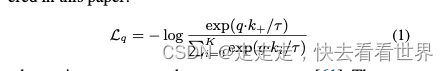
讨论
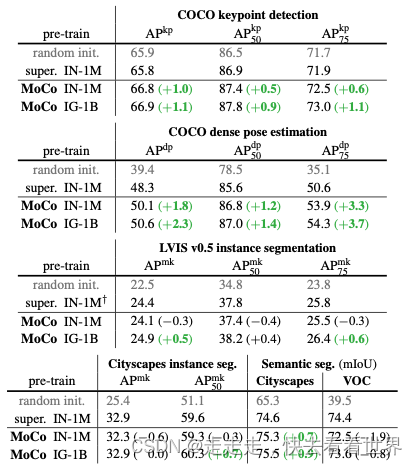
MOCO在各种计算机视觉任务和数据集中显示了无监督学习的积极结果。有几个悬而未决的问题值得讨论。MoCo从IN-1M到IG-1B的改进一直很明显,但相对较小,这表明可能无法充分利用更大规模的数据。我们希望一项先进的借口任务将改善这一情况。除了简单的实例判别任务之外,还可以将MoCo用于掩蔽自动编码等借口任务,例如在语言和视觉中。我们希望MoCo对其他涉及对比学习的借口任务有用。(好像这个就是后续的clip工作)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









