







目录
A. Relationship with our previous work
B. Bootstrap Your Own Latent (BYOL)
Abstract
在现代机器学习系统各个领域中,预训练模型作为特征提取器是必不可少的。在这项研究中,作者假设对一般音频有效的表示应该提供输入声音的多个方面的鲁棒特征。为了识别声音,而不考虑诸如变化的音调或音色等扰动,特征应该对这些扰动具有鲁棒性。为了满足任务的不同需求,如情感或音乐类型的识别,表示应该提供多个方面的信息,如本地和全局特征。为了实现该原则,作者提出了一种自监督学习方法。BYOL-A预训练对音频数据增强不变的输入声音表示,这使得学习到的表示对声音扰动具有鲁棒性。而BYOL-A编码器结合了局部特征和全局特征,并计算它们的统计信息,使表示提供多方面的信息。因此,学习的表示应该提供健壮的和多方面的信息,以服务于不同任务的各种需求。
I. INTRODUCTION
预训练模型在各个领域中作为特征提取器起着至关重要的作用,作者的目标就是探索一种实现多功能的音频表示方法,该方法可以有效地完成各种任务,无须额外地努力如微调。如果可以将模型用作冻结参数的特征提取器,模型的适用性会提高,因为微调的影响是不可忽略的,例如仔细调整学习速率,以不破坏预先训练的有价值特征。因此,如果一个表示足够通用,那么它就是一个最终目标。
作者做了以下贡献:
- 提出了BYOL-A。BYOL-A学习对声音扰动鲁棒的表示,其编码器结合了局部和全局特征的统计数据,以提供多方面的信息。
- 制定了一个新的基准,能够评估不同音频任务的通用性。
- 使用基准证明了我们方法的通用性和有效性,同时将我们的方法与从传统最先进模型中提取的11种表示进行了比较。
- 进行了深入的消融研究,以阐明BYOL-A框架、增强和编码器网路架构的贡献。
BYOL-A框架图如下所示:
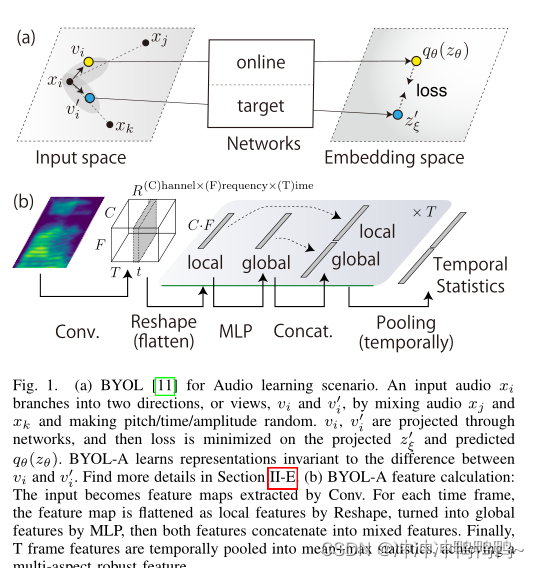
图中(a)通过混合音频xj和xk并使音调/时间/振幅随机,输入音频xi分支到两个方向,即视图vi和vi'。通过网络投影Vi, vi',使投影的zξ'值和预测的qθ(zθ)的损耗最小化。BYOL-A学习不受vi和v0i之差影响的表示。(b) BYOL-A特征计算:输入成为Conv提取的特征图。对于每个时间帧,特征图通过重塑平坦化为局部特征,通过MLP转化为全局特征,然后两个特征连接为混合特征。最后,对T帧特征进行均值+最大值统计,实现了多方面的鲁棒特征。
II. RELATED WORK
A. Relationship with our previous work
作者之前的工作提出的BYOL- A版本[1],它将BYOL扩展到用于学习特定目标的音频表示的音频数据增强,即前景声学事件声音和声音纹理细节。
[1]BYOL-A旧版本:https://arxiv.org/pdf/2103.06695.pdf
虽然它通过对这些目标的学习表示展示了最先进的性能,但比较仅限于在无监督学习方法之间,而且我们没有讨论编码器架构的改进。
在本文中,作者重新定义了一种假设,以更广泛的研究范围探索预先训练的通用音频表示。为了实现这个新目标,作者扩展了BYOL-A来学习不受声音扰动影响的表示。我们还扩展了BYOL-A编码器架构,以提供学习到的特性的多个方面。
具体不同有以下几个方面:
•重新定义了有效的通用音频表示的假设。
•重新解释BYOL-A,以学习不受数据增强引起的声音扰动影响的表示,而不是学习特定声音的表示。
•优化数据增强以提高性能。
•改进编码器架构,以结合信息的多个方面。
•在统一的基准下,用各种流行的模型和任务来评估。
•进行了密集的消融研究,以分析BYOL-A框架、增强和编码器网络架构的贡献。
B. Bootstrap Your Own Latent (BYOL)
BYOL是一个自监督学习算法,学习图像表示不变的数据增强。
如下图所示,BYOL由两个神经网络组成,分别成为在线网络和目标网络。在线网络由一组权重定义。目标网络与在线网络具有相同的体系结构,但是使用了不同的权重集
。首先,BYOL通过分别应用图像增广
和
,从图像x生成两个增广视图
和
,其中T和T’表示图像增广的两个分布。然后在线网络从第一个视图
输出一个表示
,一个投影
和一个预测结果
;另一方面,目标网络从第二个视图
种输出
和目标投影
。
最后,计算L2标准化预测和目标投影
之间的均方误差:

式中,表示内积,为了使损失
对称,
被定义为将v'输入到在线网络,v输入到目标网络的损失。最终的损失是两者相加。在每一步训练,BYOL只根据
来使损失最小,
是
的指数移动平均。
实证结果表明,在在线网络中加入预测因子和使用在线网络参数的移动平均作为目标网络相结合,可以在在线投影中编码越来越多的信息,避免了常数表示等崩溃解。

III. PROPOSED METHOD
A. BYOL for Audio (BYOL-A)
我们扩展BYOL,通过替换音频的数据增强来学习输入本身不受声音扰动影响的表示。如图2所示。
图3显示了BYOL-A增强模块由前/后归一化和三个增强块组成:Mixup、Random Resize Crop和Random Linear Fader组成。

BYOL-A编码器网络(如下图所示):为了支持提供多方面信息的表示,作者使BYOL-A编码器(i)在全局池中保留所有可用信息,(ii)优化局部特征的分辨率,(iii)结合局部和全局特征,(iv)及时结合平均和最大统计信息。
作者使用来自满足需求(i)的[2]的音频嵌入块作为基本架构。我们对这个基础架构进行修改,以实现剩下的(ii)-(iv)。
[2]Y . Koizumi, D. Takeuchi, Y . Ohishi, N. Harada, and K. Kashino, “The
NTT DCASE2020 challenge task 6 system: Automated audio captioning
with keywords and sentence length estimation,” DCASE2020 Challenge,
Tech. Rep., 2020. [Online]. Available: https://arxiv.org/abs/2007.00225















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









