









- 文章原创自微信公众号「机器学习炼丹术」
- 作者:炼丹兄
- 联系方式:微信cyx645016617
本篇文章主要讲解两个无监督2020年比较新比较火的论文:
- 论文名称:“Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning”
- 论文链接:https://arxiv.org/pdf/2006.07733.pdf
0 综述
BYOL是Boostrap Your Own Latent,这个无监督框架非常的优雅和简单,而且work。收到了很多人的称赞,上一个这样起名的在我认知中就是YOLO。两者都非常简单而优美。
1 数学符号
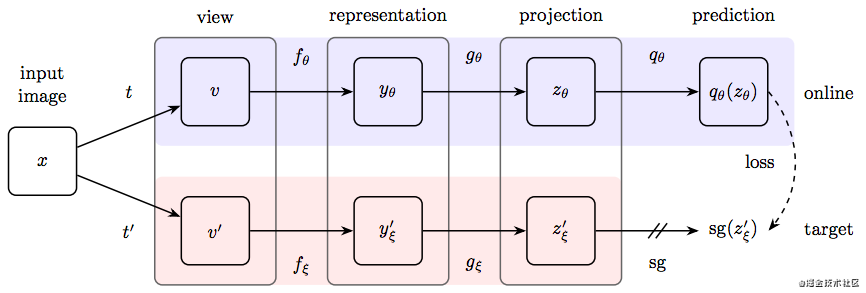
这个结构有两个网络,一个是online network,一个是target network。
- online network:用 θ \theta θ来表示online network的参数,包含,encoder f θ f_{\theta} fθ,projector g θ g_{\theta} gθ和predictor q θ q_\theta qθ
- target netowrk:使用 ξ \xi ξ来表示参数,也有 f ξ f_{\xi} fξ和 g ξ g_{\xi} gξ,但是没有predictor。
我们会更新online network,然后用滑动平均的方式,更新target network:
ξ ← τ ξ + ( 1 − τ ) θ \xi\leftarrow \tau\xi + (1-\tau)\theta ξ←τξ+(1−τ)θ
现在我们有一个图像数据集D,其中获取一个图片 x ∈ D x\in D x∈D,然后我们对这个D做不同的图像增强,得到了两个新的分布 T \Tau T和 T ′ \Tau' T′,然后从两个新分布中获取的图片,用 v v v和 v ′ v' v′标记。也就是说,如果用 t ( ) t() t()和 t ′ ( ) t'() t′()表示对图像做图像增强的过程,那么 v = t ( x ) , v ′ = t ′ ( x ) v=t(x),v'=t'(x) v=t(x),v′=t′(x)。
2 损失函数
我们现在有 v v v,经过encoder,得到 y = f θ ( v ) y=f_{\theta}(v) y=fθ(v),经过prejector,得到 z = g θ ( y ) z=g_{\theta}(y) z=gθ(y),经过predictor,得到 q θ ( z ) q_{\theta}(z) qθ(z);同理,target network也是如此,只是没有最后的predictor,最终得到 z ′ z' z′。
我们对 z ′ z' z′和 q θ ( z ) q_{\theta}(z) qθ(z)做l2-normalization,含义为取出这两个隐含变量的绝对大小,而保留其方向性,为后面要做的向量点乘做铺垫。
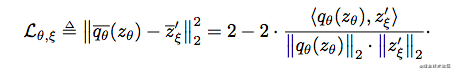
上图中, q θ ˉ ( z ) = q θ ( z ) ∣ ∣ q θ ( z ) ∣ ∣ 2 \bar{q_{\theta}}(z)=\frac{q_{\theta}(z)}{||q_{\theta}(z)||_2} qθˉ(z)=∣∣qθ(z)∣∣2qθ(z),损失函数不难,其实有点像是: 2 − 2 cos θ 2-2\cos\theta 2−2cosθ
上面,我们得到了损失 L θ , ξ L_{\theta,\xi} Lθ,ξ,接下来,我们需要计算symmetric loss,这个是把v和v‘分别放入target network和online network计算,得到的 L ~ θ , ξ \widetilde{L}_{\theta,\xi} L θ,ξ,然后论文中提到,通过SGD来最小化
L θ , ξ B Y O L = L θ , ξ + L ~ θ , ξ L^{BYOL}_{\theta,\xi}=L_{\theta,\xi} + \widetilde{L}_{\theta,\xi} Lθ,ξBYOL=Lθ,ξ+L θ,ξ
需要注意的是,这个优化的过程,仅仅更新online network,target network的参数不变化,目的是让online network逐渐拥有target network的性能
因此,这个BYOL的整个训练过程可以浓缩成下面的两行:
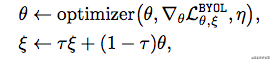
3 细节部分
3.1 图像增强

3.2 结构
上图中的encoder
f
θ
,
f
ξ
f_{\theta},f_{\xi}
fθ,fξ使用的是resnet50和post activation,这里第一次看到post activation,就去看了一下发现,其实就是先卷积还是先激活层,如果relu放在conv后面就是post activation,relu放在conv前面就是pre activation。
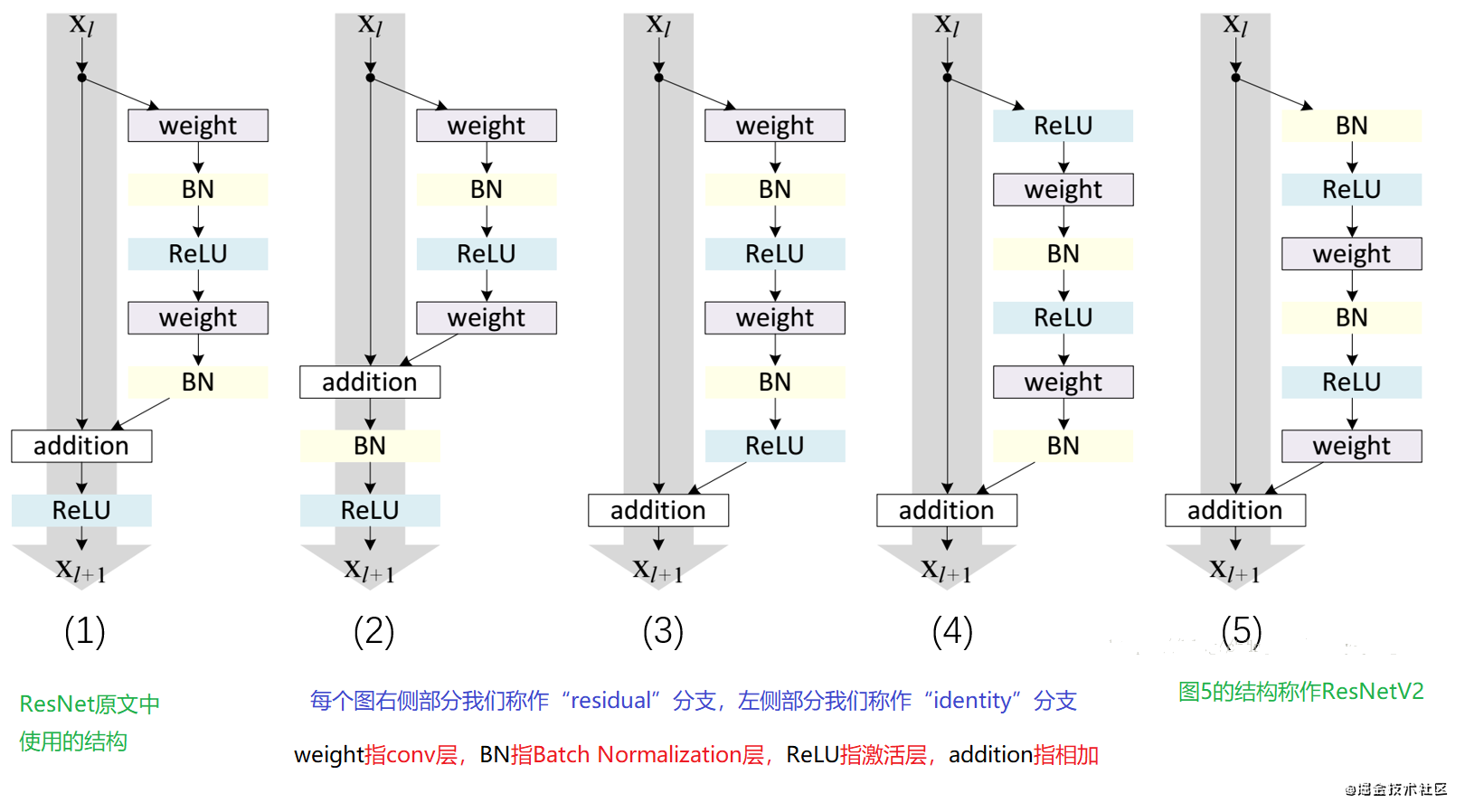
经过encoder,一个图片会输出2048个features,然后经过MLP,特征扩展到4096个特征,最终输出256个特征,在SimCLR模型中,MLP后跟了一个BN层和Relu激活层,但是在BYOP中没有BN层。
3.3 优化器
使用的是LARS优化器,使用cosine 学习率衰减策略,训练1000epoch,其中包含10个warn-up epoch。学习率设置的为0.2。
至于online更新到target的参数 τ \tau τ, τ b a s e = 0.996 \tau_{base}=0.996 τbase=0.996,
τ = 1 − ( 1 − τ b a s e ) ( cos π k K + 1 ) 1 2 \tau=1-(1-\tau_{base})(\cos\frac{\pi k}{K}+1)\frac{1}{2} τ=1−(1−τbase)(cosKπk+1)21
k is current training step and K is maximum training steps.
3.4 财力
batchsize为4096,分布在512个TPU v3的核,训练encoder大约需要8个hour。
4 模型评估
在ImageNet上做监督学习,先用无监督训练好encoder后,然后用标准的resnet50进行监督微调:

前面同行,这里的监督训练也是获取ImageNet上的少部分数据集进行训练,所以叫做semi-supervised:
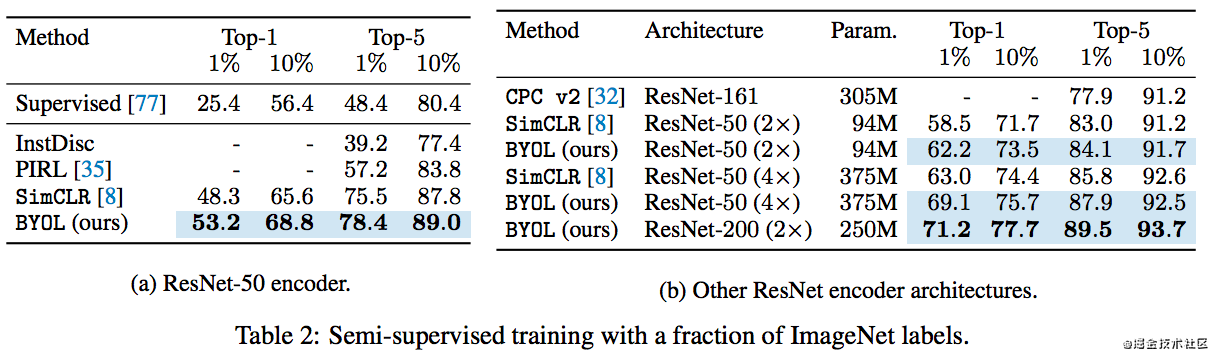
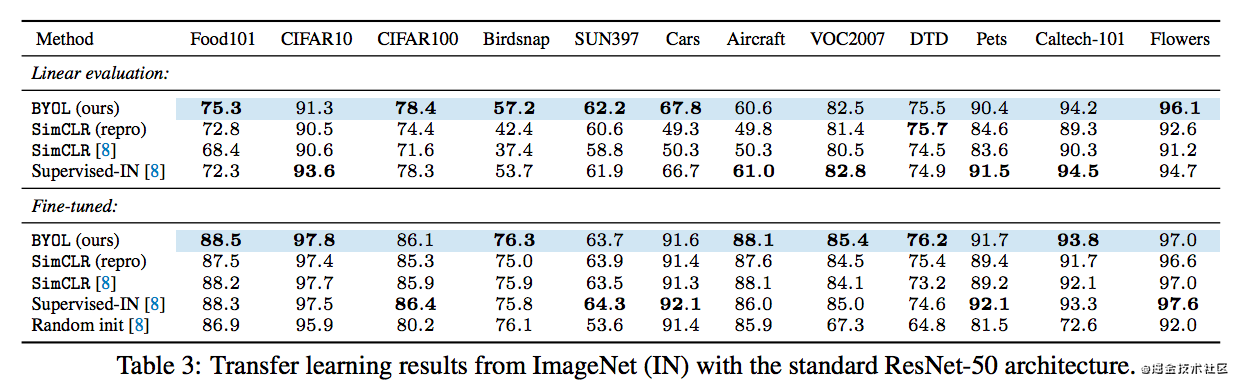
这样的方法在其他的分类数据集上的效果:
觉得笔记不错的,可以关注作者的微信公众号「机器学习炼丹术」。
















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









