






文章目录
R2 -CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images
Abstract
最近,卷积神经网络在目标检测方面取得了令人瞩目的进步。然而,在大规模遥感图像中检测微小目标仍然具有挑战性。首先,极大的输入尺寸使得现有的目标检测解决方案在实际应用中过于缓慢。其次,复杂的大量背景导致严重的 false alarms。此外,超微小目标增加了准确检测的难度。为了解决这些问题,我们提出了一种名为遥感区域卷积神经网络(R2-CNN)的self-reinforced network,由主干网络Tiny-Net、中间的全局注意力块和最终的分类器和检测器组成。Tiny-Net是一种lightweight residual结构,能够从输入中快速且有效地提取特征。全局注意力块基于Tiny-Net构建,以抑制false positives。分类器用于预测每个图块中是否存在目标,如果有,随后使用检测器进行精确定位。分类器和检测器通过端到端训练相互强化,进一步加速处理过程并避免误报。R2-CNN的有效性已在数百幅GF-1图像和GF-2图像上得到验证,它们的分辨率分别为18,000×18,192像素,2.0米resolution,和27,620×29,200像素,0.8米resolution。具体而言,我们可以在Titan X上仅使用单个线程在29.4秒内处理一张GF-1图像。据我们所知,以前没有解决方案可以在如此巨大的遥感图像上优雅地检测微小目标。我们相信,这是朝着实际实时遥感系统迈出的重要一步。
I. INTRODUCTION
由于光学遥感成像技术的发展,高分辨率图像可以很容易地获取。在遥感领域,目标检测、变化检测、语义分割等任务变得越来越受欢迎。
一些人提出了不同的方法来实现在遥感图像中进行目标检测,利用了深度卷积神经网络强大的特征提取能力。然而,这些方法主要集中在尺寸输入相比较小的区域段,因此,它们无法扩展到如此巨大的图像。Zhang等人首先尝试在大规模图像中检测机场以加快处理速度,但训练和测试图像都来自机场附近的区域,这使其逃避了复杂的背景。根据我们的实验,这对于实际应用来说不够稳健。
在大规模遥感图像中进行目标检测是非常具有挑战性的。首先,输入图像的规模太大,难以达到实际应用。计算时间和内存消耗成倍增加,使其在当前硬件上运行缓慢且不可行。其次,真实场景中出现的大量复杂背景可能引入更多的误报,例如沙漠地区或具有大量建筑结构的城市区域。此外,在微小目标(如8-32像素)方面的性能急剧下降,特别是在低分辨率图像中,这进一步增加了在遥感图像中检测微小目标的难度。
为了解决这些问题,我们提出了一种unified and selfreinforced convolutional neural network,称为R2-CNN(Remote Sensing Region-based Convolutional Neural Network),它由主干网络Tiny-Net、中间的全局注意力块和最终的分类器和检测器组成,使得整个网络在计算和内存消耗方面更加高效,并能够强力地检测微小目标。流程如图1所示。
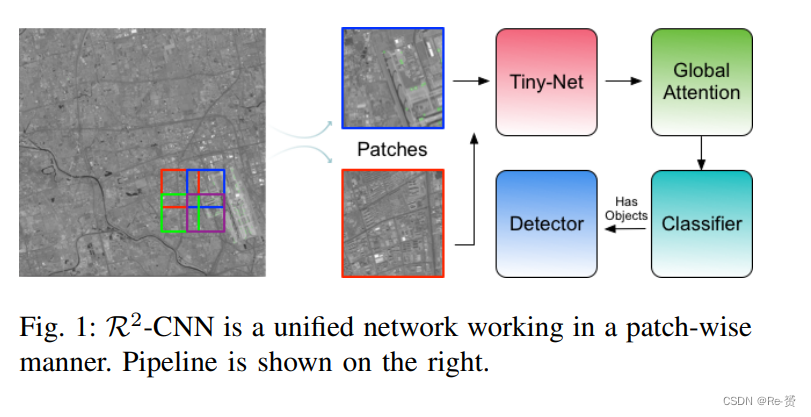
首先,作为一个unified and self-reinforced的框架,R2-CNN首先将大规模图像裁剪为更小的尺寸(例如640×640像素),并采用20%的重叠来处理过大的输入尺寸。通过异步处理图块,有限的内存不再是问题。然后,将卷积主干结构应用于输入,从而实现强大的特征提取。基于discriminative features,分类器首先在当前图块中预测检测目标的存在,然后如果可能,跟随一个检测器来精确定位它们。分类器和检测器在端到端训练框架下相互强化。这种self-reinforced的架构有以下两个优点:
-
在大规模遥感图像中,大多数crops不包含有效目标,因此约有99%的图块无需通过繁重的检测器分支。轻量级的分类器分支可以在不增加较重检测器成本的情况下过滤掉空白图块。
-
由于大多数false positives通常出现在大规模背景中,得益于 self-reinforced框架,分类器可以通过来自检测器的细粒度特征识别出 difficult situation,即使图块中只有一个微小目标。另一方面,由于分类器将大多数false positive 候选项过滤掉,因此检测器收到的false positive 候选项较少。即使分类器错误地将某些图块错误分类,检测器仍然可以在后续对结果进行修正。
其次,我们特意设计了一种轻量级残差网络,称为Tiny-Net,以减少推理成本并保留用于目标检测的强大特征。由于参数较少,Tiny-Net可以使用cycle training schedule从头开始进行训练,这使得该框架不受训练样本和自然图像与遥感图像之间domain gap的影响。
第三,为了进一步抑制false positives,我们还在Tiny-Net的顶部使用特征金字塔池化作为全局注意力块。首先,特征图在不同的金字塔级别进行池化,例如1×1、2×2和4×4。然后,我们使用bilinear
interpolation将池化后的特征还原到它们的原始尺寸。接下来,进一步融合特征图。特征图获取更多的上下文信息,并且感受野也扩大到整个图像。借助更多的上下文信息,检测器更具有辨别性。我们可以发现,通过这个模块,false positives的置信度明显降低,证明了它的有效性。
最后,为了使该框架能够强力地检测微小目标,我们对为何在微小目标上检测性能急剧下降进行了综合分析,并提出了一种scale invariant anchor策略来合理地铺设锚点,特别适用于小目标,该策略基区域建议网络(RPN)。另一方面,我们在Tiny-Net中插入了一种高效的(zoom-out)和(zoom-in)架构,以扩大特征图,从而明显提高微小目标的召回率。我们还使用了Position sensitive region of interests(RoI)池化来共享所有检测器对整个图像的计算,并获取更多的空间信息。
我们的贡献可以总结为四个方面:
-
我们提出了一个名为R2-CNN的unified and self-reinforced 框架,它在计算和内存消耗方面高效,并能够强力地检测微小目标。
-
我们提出了Tiny-Net,一种轻量级残差网络,可以从scratch开始训练,并进一步提高了效率。
-
我们在R2-CNN中插入了一个全局注意力块,以进一步抑制误报。
-
我们对为何在微小目标上检测性能急剧下降进行了全面分析,并进一步使该框架能够强力地检测微小目标。
II. RELATED WORK
略过
III. PROPOSED METHOD
R2-CNN的架构如图2所示,由主干网络Tiny-Net、中间的全局注意力块和最终的分类器和检测器组成。
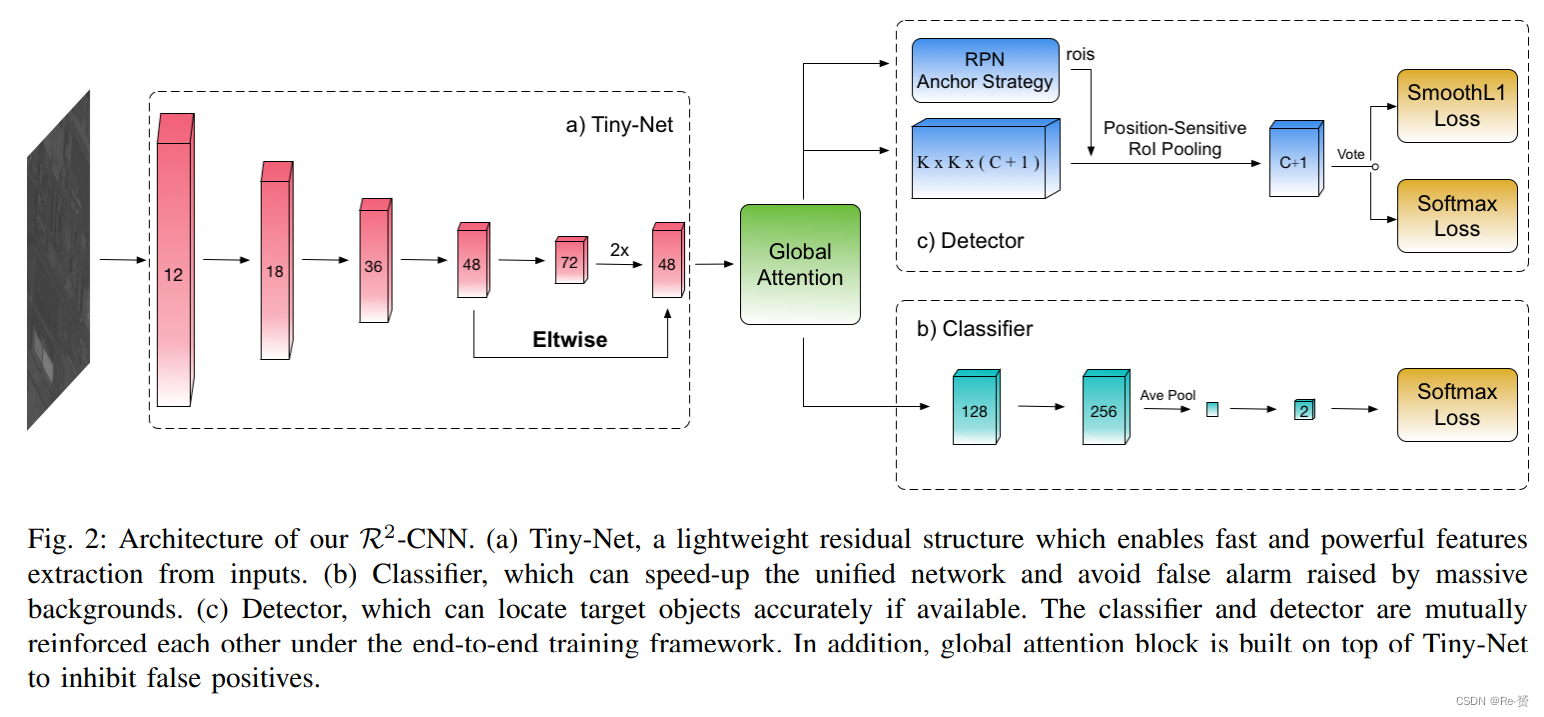
A. R2-CNN
R2-CNN是一种unified and self-reinforced的框架,以端到端的方式工作。考虑到大尺寸输入图像使计算时间和内存消耗成倍增加,我们对大规模遥感图像(例如20,000×20,000像素)进行裁剪,得到更小尺寸的图块(例如640×640像素),并采用20%的重叠。通过异步处理图块,有限的内存不再是问题。
然后,将卷积主干结构应用于输入,实现强大的特征提取。基于这些辨别性特征,分类器首先在当前图块中预测检测目标的存在,然后如果可能,跟随一个检测器来精确定位。分类器和检测器在端到端训练框架下相互强化。这种自我强化的架构有以下两个优点:
首先,轻量级的分类器分支可以在不增加较重检测器成本的情况下过滤掉空白图块。分类器的架构如图2-(b)所示,我们仅使用两个CONV-BN-RELU块从前一层的特征中提取特征。然后,全局平均池化和一个1×1的卷积操作被附加在其上。采用Softmax损失来引导分类器的训练。考虑到在遥感图像中,大多数裁剪图块不包含有效目标,约有99%的图块无需通过较重的检测器分支。
其次,真实场景中出现的大量复杂背景(例如沙漠地区或带有大量建筑结构的城市区域)可能会引入更多的false positives。这些false positives首先通过分类器和检测器之间的mutual reinforcement来抑制。
一方面,分类器可以在图块中只有一个微小目标(例如12×12像素)的情况下识别出困难情况。我们解释这一提升主要是由于从检测器提取的fine-grained feature。另一方面,由于分类器过滤掉了大多数误报候选项,检测器接收到的false positive候选项较少。即使分类器错误地将一些图块错误分类,检测器后续仍可以纠正结果。
我们的网络有三个输出。分类器的一个输出m表示对应图块是否存在目标对象的概率。检测器的两个输出表示每个感兴趣区域(RoI)对应的K+1个类别的离散概率(p = (p0,…,pk))分布,以及每个目标类别k的边界框回归偏移量tk = (tkx,tky,tkw,tkh)。我们使用参数化方法来表示tk,其中tk表示与object proposal相对的scale invariant translation和log-space height/width shift。每个训练图块用一个二进制的ground-truth 进行labeled,而检测器中的每个RoI用 ground-truth 类别u和 ground-truth 边界框回归目标v进行labeled。我们在每个图块上使用统一的多任务损失L来联合分类器和检测器:
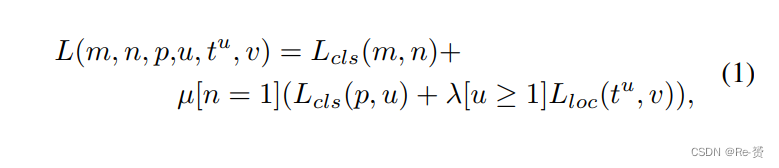
其中,Lcls(p, u)和Lcls(m, n)是softmax损失,而Lloc是 smooth-L1损失。超参数λ和µ控制着三个任务损失之间的平衡。所有实验中,我们使用λ = 1和µ = 1。在训练时,只有在对应的图块中存在检测目标时,我们才会反向传播检测器的损失。整个网络高效、稳健且强大。
B. Tiny-Net
最近,基于CNN的方法通常使用VGG或ResNets作为特征提取器。这些模型在ImageNet 上进行预训练,ImageNet是一个包含数百万张图像的大规模分层图像数据库,这样可以应对有限的训练样本并且更快地达到收敛。然而,在使用这些预训练模型时仍然存在许多缺点。首先,这些模型过于庞大,无法实现实时效率。其次,这些模型专门设计用于图像分类,导致特征分辨率可能不足以用于目标检测。最后,考虑到参数庞大,从头开始训练相当困难,尤其是在训练样本有限的情况下。当将预训练模型应用于遥感框架时,自然图像与遥感图像之间的domain gap可能使得模型表现不佳。
Tiny-Net的架构如表I所示。其中3×3块是ResNet 中的残差块,除了conv-1。我们没有在conv-1中应用下采样操作,这样可以使特征图对于小目标检测更具有区分性,这与ImageNet预训练模型(如VGG 和ResNets)不同。Tiny-Net的参数比ResNets要少得多。得益于这种轻量级的架构,Tiny-Net可以从头开始训练,并且只需要一个cycle training schedule就能很好地收敛,该计划会两次或更多次地迭代更新步长学习率。在这种情况下,Tiny-Net不会受到自然图像与遥感图像之间的domain gap的影响。

由于这些特点的优势,Tiny-Net可以降低推理成本并保留用于遥感图像中小目标检测的强大特征,从而进一步提高了R2-CNN的效率。
C. Global Attention
得益于统一的分类器和检测器,许多空白区域被分类器过滤掉,从而显著减少了false positives。然而,由于模型的limited receptive field,问题仍然存在。当你看到两个外观相似的目标时,如果没有上下文信息,你可能不确定它们到底是什么。例如,在图3-(a)中看到顶部的图像时,你可能感到困惑并想知道:“它们究竟是什么?” 但是,当你看到底部的两个图像时,你可以轻松地将它们区分开来。
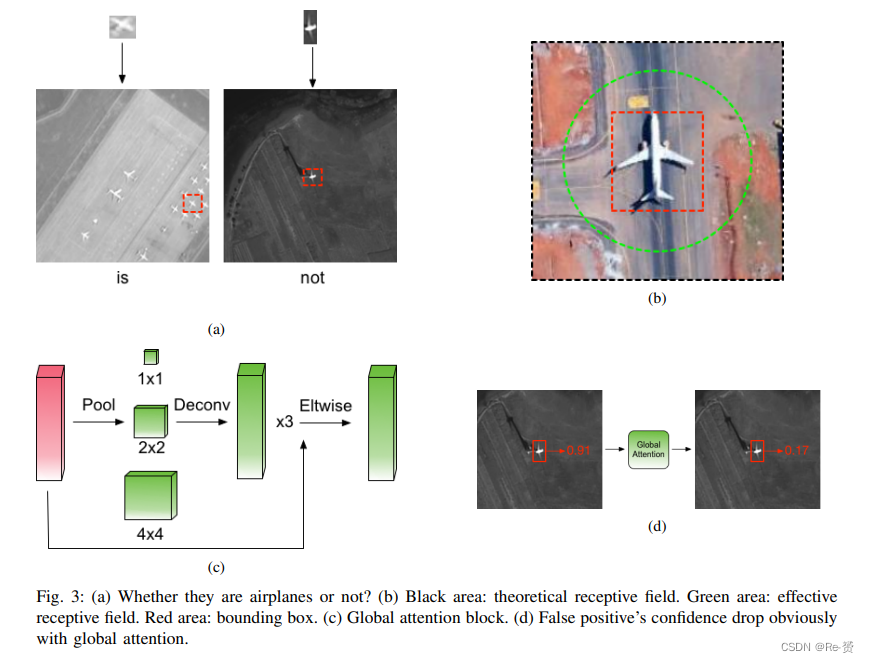
卷积神经网络具有两种感受野:theoretical receptive field 和effective receptive field。理论感受野指的是在理论上可以影响某个单元值的输入区域。然而,并不是理论感受野中的每个像素对最终输出值都有相同的贡献。只有该区域的一个子集对输出值有有效影响,这被称为有效感受野。有效感受野比理论感受野要小,如图3-(b)所示。有限的有效感受野使得最终特征图获取的上下文信息较少,从而导致更多的误报。
受到这一现象的启发,我们在Tiny-Net的顶部使用了特征金字塔池化作为全局注意力块。其架构如图3-©所示。首先,将特征图在不同的金字塔层级(如1×1、2×2和4×4)上进行池化。然后,使用双线性插值将池化后的特征还原到其原始尺度。接下来,对特征图进行进一步融合。这样,特征图能够获取更多的上下文信息,感受野也会扩大到整个图像。全局注意力模块将来自不同金字塔层级的特征进行融合,使得检测器更加关注整个图像,借助更多的上下文信息,检测器具有更强的区分性。我们发现,在使用这个模块后,false positives的置信度明显下降,如图3-(d)所示,证明了它的有效性。
D. Detector
我们的R2-CNN在检测小目标方面表现出色。检测分支的架构如图2-©所示。目前最先进的目标检测器主要基于RPN框架,该框架使用anchors生成object proposals。anchors是一组预定义的框,以多个尺度和长宽比规律地平铺在图像平面上。然而,基于锚点的检测器在检测像素尺寸小于16×16的小目标时性能显著下降,而这些小目标在遥感图像中占据了大多数,比如飞机、船舶和汽车。为了解决这个问题,我们首先研究了为什么会出现这种情况,并提出了一种scale-invariant的锚点策略,合理地铺设锚点,尤其是针对小目标。另一方面,我们在Tiny-Net中插入了一个高效的缩放结构,用于在不增加边缘成本的情况下扩大特征图,从而明显提高了小目标的召回率。还使用了 Position sensitive的RoI池化来获取更多的空间信息。通过这些方法,我们在小目标检测方面取得了出色的结果。
1)为什么会出现这种情况?如图4-(a)所示,最低 anchor-associated层的步幅大小太大(例如,16像素或32像素),在池化层的降采样过程中导致了特征的丢失。因此,小目标在这些层上被 highly squeezed,并且用于检测的特征非常有限。例如,一架飞机在最终的特征图中可能只有1×1像素大小。
此外,锚点的尺度是离散的(例如,16、32、64、… 2k),而目标的尺度是连续的。在训练过程中,如果一个锚点与某个ground-truth目标框的交并比(IoU)最高,或者其IoU高于阈值Th,那么该锚点将被分配给这个目标框。当目标的尺度接近某个锚点的尺度时,会有更多锚点与之相匹配,从而更容易定位。人脸检测器S3FD 使用了SSD 的架构,适当地解释了这一现象,并且我们在Fig 4-(b)中推测了它们的统计数据。图中显示了在16、32、64、… 2k 锚点尺度下,不同脸部尺度匹配的锚点数量。如果一个目标的尺度超过了平均线,那么它将与足够数量的锚点相匹配。然而,小目标只与很少的锚点相匹配,导致性能显著下降。

2)我们的方法:为了更合理地铺设锚点,我们分析了训练数据集中边界框的尺度分布,如图4-(d)所示。可以看出,其中大部分是小目标。为了避免手动选择锚点,我们对训练集进行k-means聚类,以自动找到合适的先验尺度。我们训练集的边界框尺度为X: (x1, x2, …, xn)。我们希望得到 k 个anchor scales,并且它们的中心尺度为(µ1, µ2, …, µk)。尺度被聚类成(s1, s2, …, sk)。通过最小化以下表达式来实现:
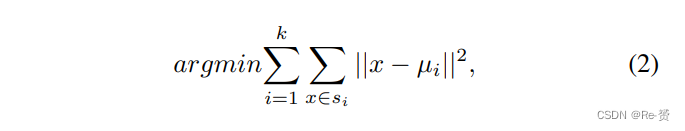
为了提取有利于小目标检测的特征,一种方法是通过使用zoom-out 和zoom-in的架构来减小锚点的步幅。如图4-©所示,我们首先通过残差块对特征图进行缩放输出,从而使其锚点步幅为16像素。然后,我们使用 zoom-in运算符将特征图恢复到其原始尺度。此外,我们在步幅为8的层和上采样层之间使用了skip connection。我们发现步幅为16的层可以提取更多的高级特征,这对目标检测是有益的。skip connection可以融合低级特征和高级特征,使得最终的特征图更具区分性。
考虑到遥感图像的复杂背景,我们在检测器中使用了 position-sensitive RoI池化而不是RoI池化。RoI池化对每个区域应用了子网络数百次。如果有1000个proposals,检测器将被浪费性地测试1000次。相比之下,位置敏感的RoI池化是全卷积的,几乎所有的计算都在整个图像上共享。这样可以节省大量计算。另一方面,位置敏感的RoI池化可以解决图像分类中的平移不变性和目标检测中的平移变化之间的困境。它提取了更多的空间信息,从而带来更好的性能。
IV. EXPERIMENTS
略过
V. CONCLUSION
We proposed R2-CNN, a unified and self-reinforced convolutional neural network under the end-to-end training framework, which joint the classifier and detector elegantly. The lightweight backbone Tiny-Net extracts powerful features from the inputs quickly, and the intermediate global attention block enlarges the receptive field to inhibit false positives. The classifier first predict the existence of detection target in the current patch, and the specifically designed detector is followed to locate them accurately if available. The high recall and precision in GF-1 and GF-2 validate the effectiveness of our network. Specifically, we can process a GF-1 image in 29.4s on Titian X just with single thread. All those experiments prove our R2-CNN is efficient in both computation and memory consumption, robust to false positives and strong to detect tiny objects.
















 1369
1369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









