







文章主要内容是在参考唐宇迪机器学习课程之后,根据对课程的学习提出理解以及仿照课程内容进行的代码实现。现在有一份数据集,这个数据集具备四维特征,两个分类,要求利用机器学习迭代模型的参数。
数学模型
逻辑回归是在线性回归当中的一种拓展,在线性回归模型当中插入中间函数,将拟合的回归模型转换成概率值,得到不同类型的概率结果。
回归模型:

偏置项可以作为默认值为1的 X0 的参数,在处理数据集的时候需要增加一列值全为1的数据特征。一般线性回归的最优解使得真实值与预测值的误差项达到最小,以此来得到参数θ的最优解,这个也就是最小二乘法的原理。逻辑回归中引入Sigmoid函数,自变量取值为任意实数,值域[0,1]
我们在线性回归中可以得到一个预测值,再将该值映射到Sigmoid 函数中这样就完成了由值到概率的转换,也就是分类任务
至此,逻辑回归预测模型就转换为:

预测函数代表概率值的话,整合后的预测模型表示在当前的θ条件下,各个样本对应实际标签的概率值,因为实际标签可以看作已发生的事件,既然已经发生那么各样本的概率必然要是最大的,将预测模型进行连乘得到似然函数,求解似然函数的最大值就是参数的最优解。

求解过程是一个迭代过程,在设定一个初始θ参数后,再求出在各个参数的偏导,结合所有偏导得到当前设定参数下的方向,在当前方向上以一定的步长更新参数,然后再继续重复以上工作,在这样的一个迭代过程中不断逼近最优解。

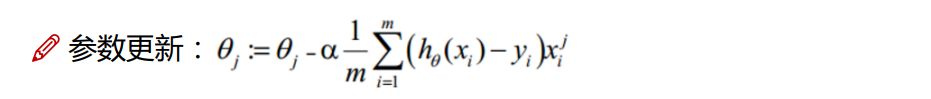
代码实现
项目实现过程可以概括成以下流程:
1、sigmoid函数:映射到概率的函数
2、model:返回预测结果值
3、cost:根据参数计算损失值
4、gradient:计算每个参数的梯度方向
5、descent:进行参数更新
6、accuracy:计算精度
引用所需要的模块
import pandas as pd
import numpy as np
import time
from matplotlib import pyplot as plt
sigmoid函数
#定义从值到概率的中间函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
预测结果值
#定义预测结果值,X,Xita都是数组,X是全样本特征数据,Xita是模型参数
def model(X,Xita 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7140
7140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









