







python处理数据基础
pandas dataframe处理基础
展示数据内容
#本身adata.obs就是dataframe类型
adata.obs # 展示全部数据内容
adata.obs['clusters_coarse'][0] # 展示对应列名第一行的某个单元格数据
获取某一列的数据 ,并将其赋值添加为新的一列
pred =adata.obs['clusters'].values
adata.obs['pred'] = pred #实现新增一列
adata.obs #可查看新增后的数据
统计某一列与另一列数据内容相等的比例
sum(adata.obs['clusters'] == adata.obs['pred']) # 先计算两列数据相同的个数
adata.shape[0] # 数据的行数
sum(adata.obs['clusters'] == adata.obs['pred'])/adata.shape[0]
查看adata.X的数据
(adata[:,['Erdr1']].X.toarray()==0).all() # 查看
查找某个数据的行
df[df['列名'].isin([相应的值])] 输出等于该值的行。
修改单个数据/单元格数据
# 查找某个数据的行
# df[df['列名'].isin([相应的值])] 输出等于该值的行。
data.iloc[8,'column_1'] = 'english'
筛选数据 str.contains(),isin()函数
str.contains()是字符串的模糊筛选,在SQL语音里用的是like。在pandas里面我们可以用str.contains()
df1 = marker[marker['cell'].str.contains('T cell')]
也可以用‘|’进行多个条件筛选:
df1 = marker[marker['cell'].str.contains('T cell|B cell')]
注意,这个‘|’是在引号内的,而不是将两个字符串分别引起来。
str.isin(),使用&可以筛选出同时满足的。.isin(['T cell','B cell']) 则是筛选出‘cell’这一列中’T cell’和’B cell’,类似‘|’或条件
df1 = marker[marker['cell'].isin(['T cell','B cell'])&marker['protein'].isin(['high'])]
总结:str.contains()是字符串的模糊筛选,而isin()是完全搜索
数据合并merge()函数
merge()函数示意图:
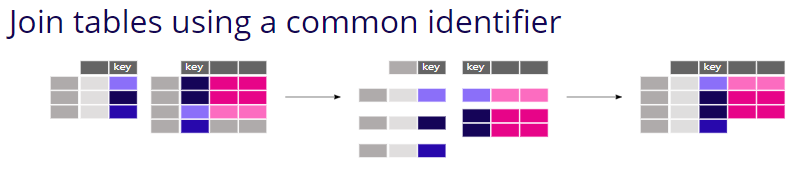 merge函数默认按相同字段名合并,且取两个都有的;
merge函数默认按相同字段名合并,且取两个都有的;
不同表的连接,选择两列作为key进行连接;
当左右连结字段名不相同时,使用left_on,right_on;
pd.merge(df1,df2,left_on='df1_key',right_on='df2_key')
# 默认内连接,即连接两边都有的值,两边都有,都一样的才合并
df1,df2代表不同的dataframe数据,‘df1_key’,'df2_key’代表不同的dataframe数据中需要连接的字段名
pd.merge(df1,df2,left_on='df1_key',right_on='df2_key',how='left') #左连接是左侧DataFrame取全部数据,右侧匹配左侧。
left 左连接,左侧取全部,右侧取部分
pandas 在csv文件后追加数据 concat()函数
删除行列的操作 drop()函数和dropna()函数
dropna()函数:删除dataframe中所有带空值的行或列
axis: default 0指行,1为列
how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;'all’指清除全是缺失值的
thresh: int,保留含有int个非空值的行
subset: 对特定的列进行缺失值删除处理
inplace: True表示直接在原数据上更改
b = a.dropna(subset=['Boy_Names'])#删除列名为Boy_Names那列中带有空值的行
drop()函数:删除 Series 的元素或 DataFrame 的某一行(列)
drop([ ],axis=0,inplace=True) drop([]),默认情况下删除某一行; 删除某列,需要axis=1;
参数inplace 默认情况下为False,表示保持原来的数据不变,True 则表示在原来的数据上改变。
a.drop(['a','b'])#默认删除了a b两行
a.drop(['sex','age'],axis=1)#默认删除了sex age两列
找出含有空值的特定行和列
本身下面代码的目的是筛选出ab两个表中某一列的内容在a表但是不在b表中的数据
#先merge a b两表
join = pd.merge(a,b,left_on='Names',right_on='x',how='left')
#没在b文件中'x'列找到的数据
b_notFound = join[join[['x']].isnull().T.any()]
b_notFound.to_csv('C:/Users/Desktop/b_notFound.csv',index = 0)
找出含有空值的特定行和列:参考链接















 1900
1900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









