







import scanpy as sc
adata=sc.read("./data/panc8.h5ad")
print(adata)
# 注意下面这句
adata.__dict__['_raw'].__dict__['_var'] = adata.__dict__['_raw'].__dict__['_var'].rename(columns={'_index': 'features'})
smartseq2_adata=adata[adata.obs["BATCH"].isin(["smartseq2"])]
smartseq2_adata.write("./data/smartseq2.h5ad")
indrop_adata=adata[adata.obs["BATCH"].isin(["indrop1","indrop2","indrop3","indrop4"])]
indrop_adata.write("./data/indrop.h5ad")
有的时候,一个环境的h5ad到另一个环境并不能成功读取,而是会报错,可能是h5py和anndata的问题。
报的错误就是
ValueError: '_index' is a reserved name for dataframe columns. Above error raised while writing key 'raw/var' of <class 'h5py._hl.files.File'> from /.
这个需要注意
今天我测试了另外一个错误
环境比较
desc环境
python 3.6.10 anndata 0.7.8 scanpy 1.7.2 h5py 3.1.0
base环境
python 3.9.13 anndata 0.8.0 scanpy 1.9.1 h5py 3.1.0
desc 环境测试
import scanpy as sc
adata = sc.read("/home/yxk/Desktop/test_dataset/pancreas_desc/celseq1.h5ad")
sc.pp.normalize_total(adata,target_sum=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata,n_top_genes=1000,subset=True)
sc.pp.scale(adata)
sc.tl.pca(adata)
sc.pp.neighbors(adata)
sc.tl.umap(adata)
sc.pl.umap(adata,color=["tech","celltype"])
结果如下
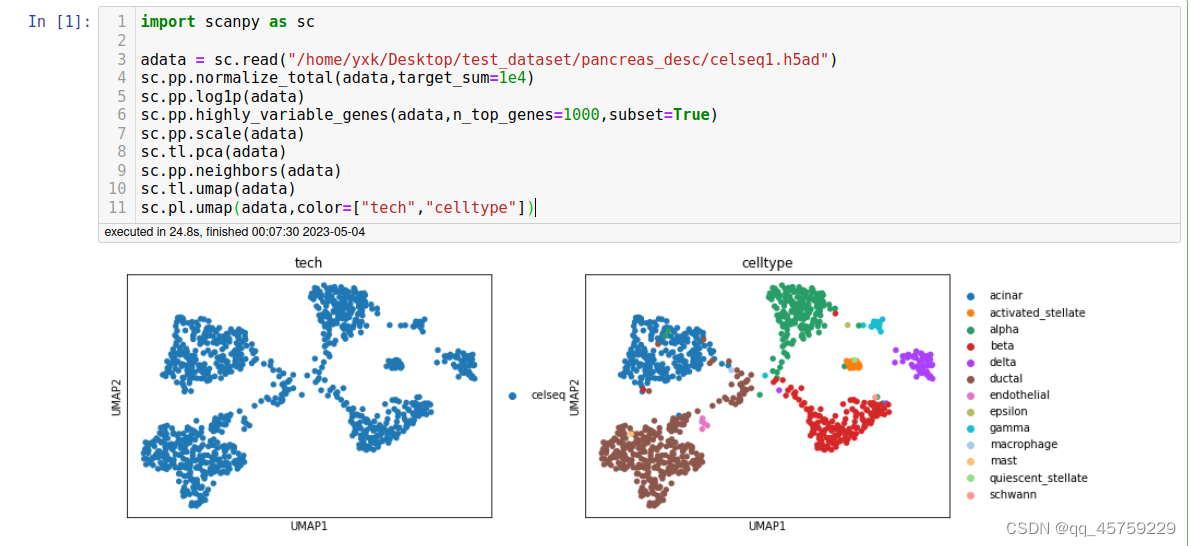

base环境测试
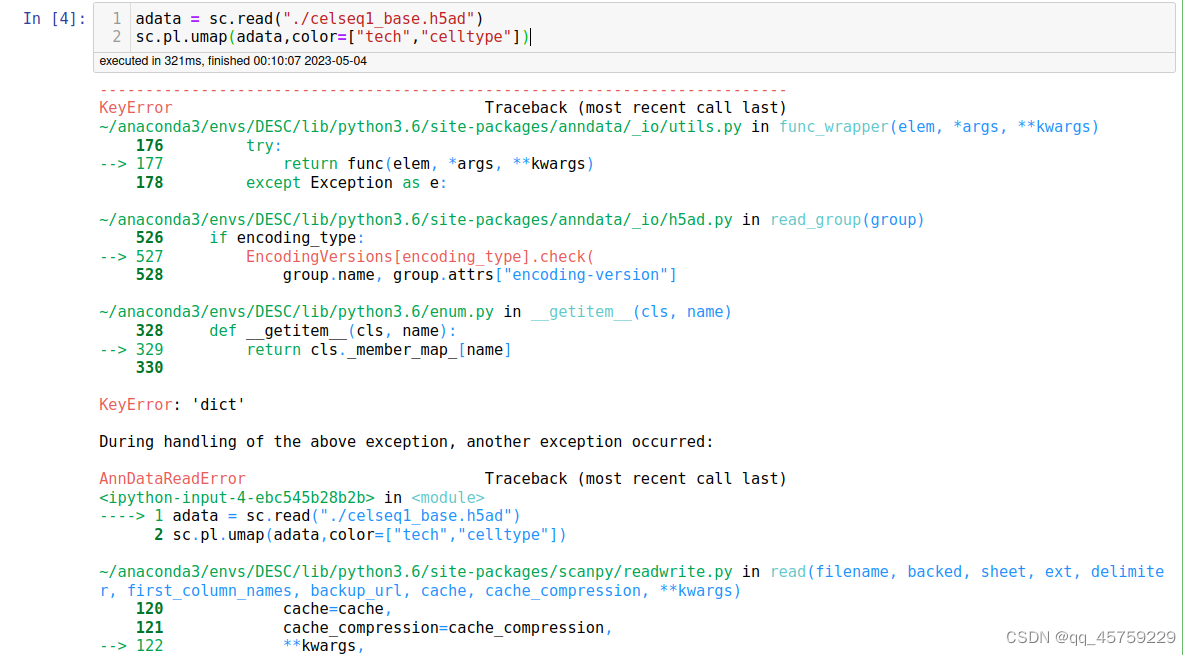
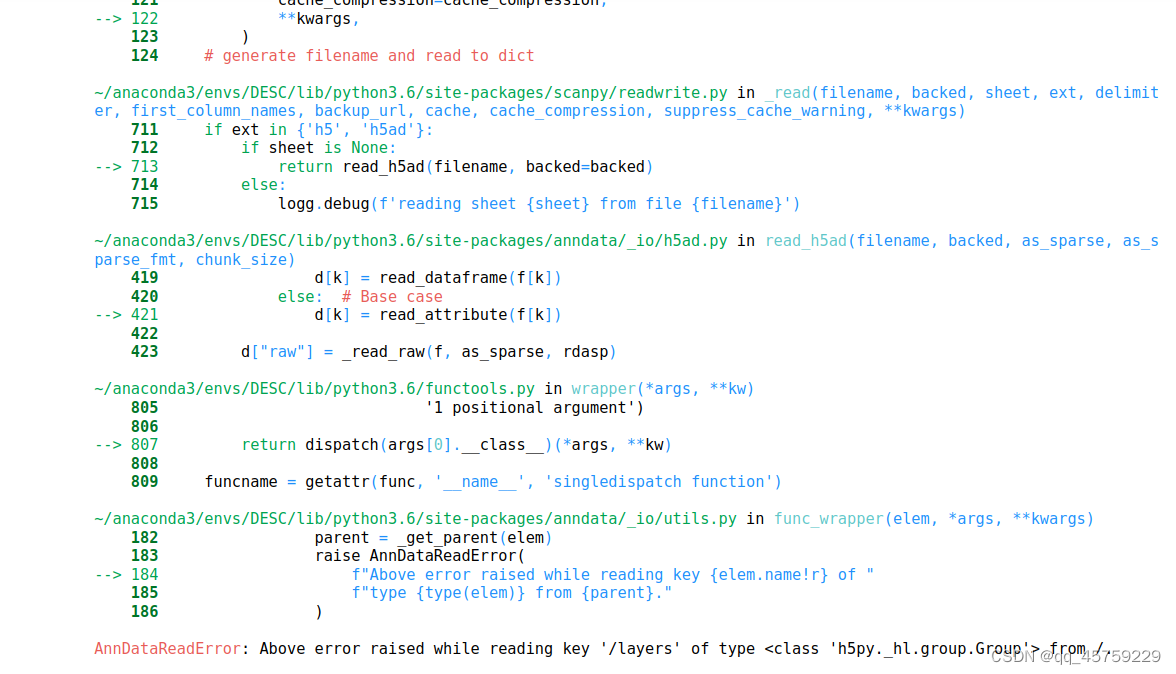
import scanpy as sc
adata = sc.read("/home/yxk/Desktop/test_dataset/pancreas_desc/celseq1.h5ad")
sc.pp.normalize_total(adata,target_sum=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata,n_top_genes=1000,subset=True)
sc.pp.scale(adata)
sc.tl.pca(adata)
sc.pp.neighbors(adata)
sc.tl.umap(adata)
sc.pl.umap(adata,color=["tech","celltype"])
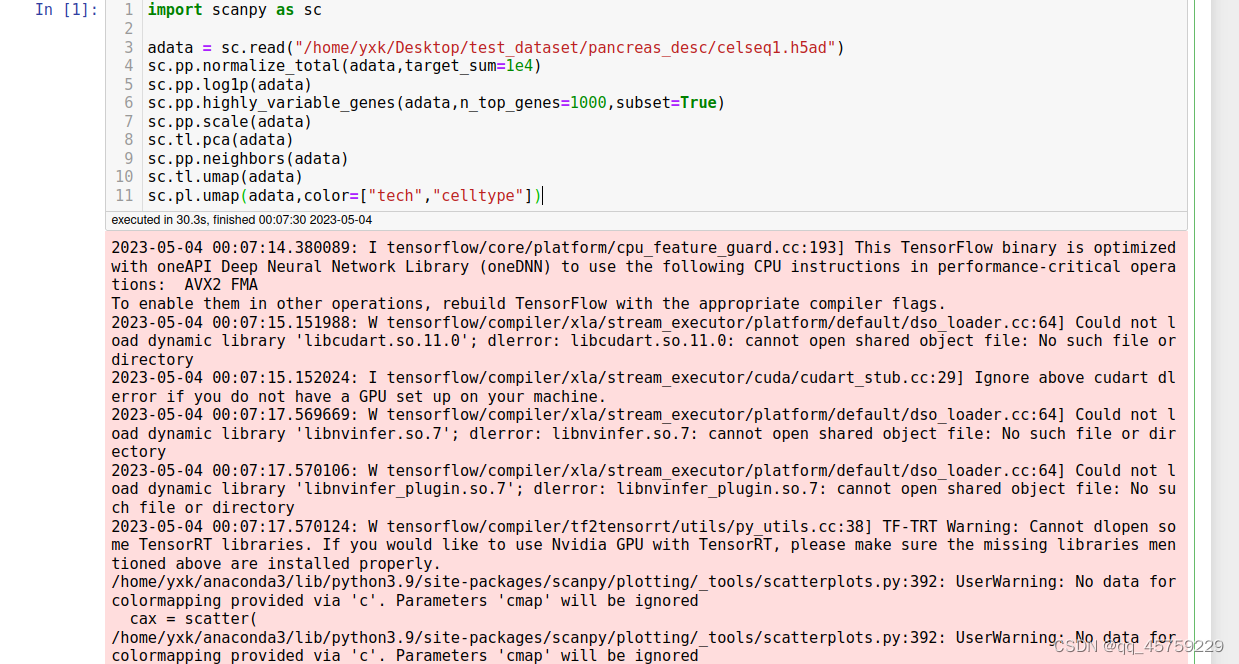


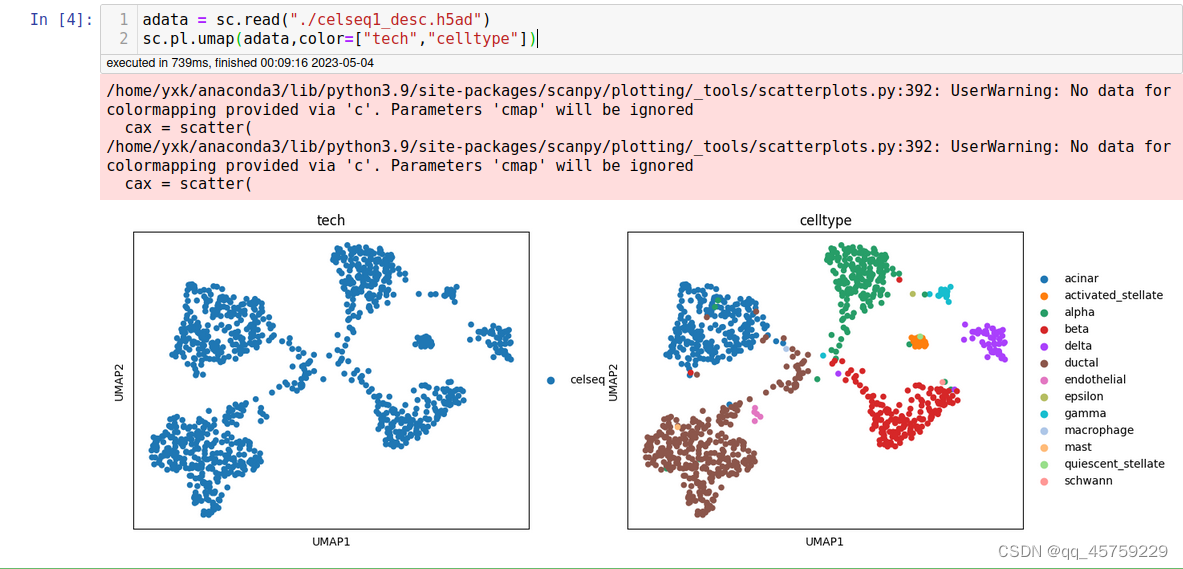
可以看到,至少desc(低版本)是不能读取高版本的anndata的,这个我有点奇怪

















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









