







本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、选择题、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert等)
本篇主要讲解文本相似度应用场景。本系列代码和数据集都上传到GitHub上:https://github.com/forever1986/bert_task
目录
1 环境说明
1)本次实践的框架采用torch-2.1+transformer-4.37
2)另外还采用或依赖其它一些库,如:evaluate、pandas、datasets、accelerate等
2 前期准备
2.1 了解Bert的输入输出
Bert模型是一个只包含transformer的encoder部分,并采用双向上下文和预测下一句训练而成的预训练模型。可以基于该模型做很多下游任务。
2.1 了解Bert的输入输出
Bert的输入:input_ids(使用tokenizer将句子向量化),attention_mask,token_type_ids(句子序号)、labels(结果)
Bert的输出:
last_hidden_state:最后一层encoder的输出;大小是(batch_size, sequence_length, hidden_size)
pooler_output:这是序列的第一个token(classification token)的最后一层的隐藏状态,输出的大小是(batch_size, hidden_size),它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)。(注意:这是关键输出,本次任务就需要获取该值,并进行相似度计算)
hidden_states: 这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)
attentions:这是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
2.2 数据集与模型
1)数据集来自:Chinese_Text_Similarity
2)模型权重使用:bert-base-chinese
2.3 任务说明
1)文本相似度任务就是判断2段文本的相似程度,可以理解为是否表达相同的意思。这时可能想到的最简单的方法就是将2段文本作为输入,label是0或1这样一个分类方法,可以采用系列1(情感分类)的方式。但是如果找是一段文本对应多个文本之间的相似度呢?或许你会想到系列3(选择题)的方式。但是如果是一段文本对应几十万的文本之间的相似度呢?虽然系列3(选择题)也能解决问题,但是会很慢,因为你要一一匹配。这里我们可以采用一个特征提取方式,先将文本输入到模型做特征,最后在通过相似度比较函数对2段文本的特征进行比较即可,虽然也是需要每段文本都做比较,但是好处是先将文本做好特征。
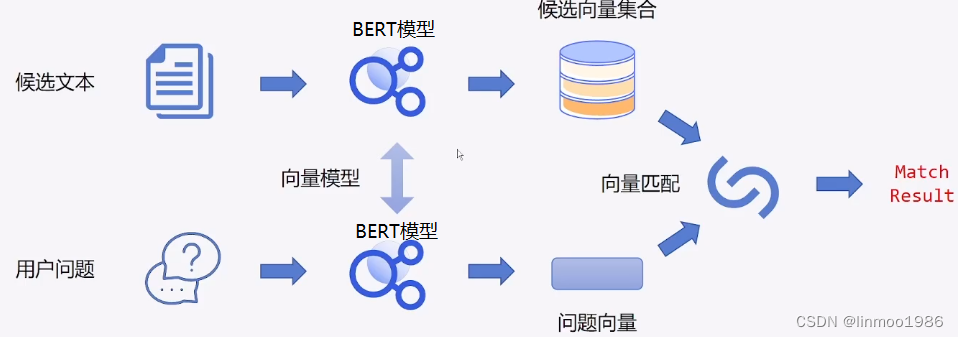
2)这时候我们需要做的是分别将数据放入同一个BERT模型进行特征提取,然后通过相似度和余弦相似度损失计算进行模型训练即可
2.4 实现关键
1)将数据处理成对放入模型中
2)自定义模型,在forward中对2个句子分别通过bert做特征提取,然后计算相似度和余弦相似度损失
3 关键代码
3.1 数据集处理
Chinese_Text_Similarity数据集是一个txt文件,每一行分别存储“句子1”、“句子2”、“相似度”。下面代码就是读取数据并处理为模型想要的类型
# 读取数据
df = pd.read_csv(data_path, sep='\s+')
df = df.sample(n=5000) # 取其中5000条
datasets = Dataset.from_pandas(df)
# 划分训练集和测试集
datasets = datasets.train_test_split(test_size=0.1, shuffle=True, seed=42)
# 划分训练集和验证集
train_datasets = datasets["train"].train_test_split(test_size=0.05, shuffle=True, seed=42)
datasets["train"] = train_datasets["train"]
datasets["validation"] = train_datasets["test"]
tokenizer = BertTokenizerFast.from_pretrained(model_path)
# 数据处理函数
def process_function(datas):
sentences = []
labels = []
for sentence1, sentence2, label in zip(datas["句子1"], datas["句子2"], datas["相似度"]):
sentences.append(sentence1)
sentences.append(sentence2)
labels.append(1 if int(label) == 1 else -1)
tokenized_datas = tokenizer(sentences, max_length=256, truncation=True, padding="max_length")
# 关键点:这里将2条数据合并为一组,也就是reshape,从(2倍datas数量 * max_length),变成(datas数量 * 2 * max_length)
tokenized_datas = {k: [v[i: i + 2] for i in range(0, len(v), 2)] for k, v in tokenized_datas.items()}
tokenized_datas["labels"] = labels
return tokenized_datas
new_datasets = datasets.map(process_function, batched=True)
3.2 模型加载
自定义模型,模仿transformers中的其它BERT模型,继承BertPreTrainedModel(为了方便使用XXX.from_pretrained()获取模型),参照其它BERT模型写法,重新init和forward方法
class SimilarityModel(BertPreTrainedModel):
# 不需要增加其它层
def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.bert = BertModel(config)
self.post_init()
# 在forward中对2个句子分别通过bert做特征提取,然后计算相似度和余弦相似度损失
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# 分别获取sentenceA 和 sentenceB的输入
senA_input_ids, senB_input_ids = input_ids[:, 0], input_ids[:, 1]
senA_attention_mask, senB_attention_mask = attention_mask[:, 0], attention_mask[:, 1]
senA_token_type_ids, senB_token_type_ids = token_type_ids[:, 0], token_type_ids[:, 1]
# 分别获取sentenceA 和 sentenceB的向量表示
senA_outputs = self.bert(
senA_input_ids,
attention_mask=senA_attention_mask,
token_type_ids=senA_token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# 获得pooler_output
senA_pooled_output = senA_outputs[1]
senB_outputs = self.bert(
senB_input_ids,
attention_mask=senB_attention_mask,
token_type_ids=senB_token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
senB_pooled_output = senB_outputs[1] # [batch, hidden]
# 计算相似度
cos = CosineSimilarity()(senA_pooled_output, senB_pooled_output)
# 计算loss
loss = None
if labels is not None:
loss_fct = CosineEmbeddingLoss(0.3)
loss = loss_fct(senA_pooled_output, senB_pooled_output, labels)
output = (cos,)
return ((loss,) + output) if loss is not None else output
model = SimilarityModel.from_pretrained(model_path)
3.3 评估函数
这里采用evaluate库加载accuracy准确度计算方式来做评估,本次实验将accuracy和f1的计算py文件下载下来,因此也是本地加载
# 评估函数:此处的评估函数可以从https://github.com/huggingface/evaluate下载到本地
acc_metric = evaluate.load("./evaluate/metric_accuracy.py")
f1_metric = evaluate.load("./evaluate/metric_f1.py")
def evaluate_function(eval_predict):
predictions, labels = eval_predict
predictions = [int(p > 0.7) for p in predictions]
labels = [int(l > 0) for l in labels]
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metric.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc
4 整体代码
"""
基于BERT做文本相似度
1)数据集来自:Chinese_Text_Similarity
2)模型权重使用:bert-base-chinese
"""
# step 1 引入数据库
import torch
from torch.nn import CosineSimilarity, CosineEmbeddingLoss
import evaluate
import pandas as pd
from typing import Optional
from datasets import Dataset
from transformers import TrainingArguments, Trainer, BertTokenizerFast, BertPreTrainedModel, PretrainedConfig, BertModel
model_path = "./model/tiansz/bert-base-chinese"
data_path = "./data/Chinese_Text_Similarity.txt"
# step 2 数据集处理
df = pd.read_csv(data_path, sep='\s+')
df = df.sample(n=5000) # 取其中5000条
datasets = Dataset.from_pandas(df)
# 划分训练集和测试集
datasets = datasets.train_test_split(test_size=0.1, shuffle=True, seed=42)
# 划分训练集和验证集
train_datasets = datasets["train"].train_test_split(test_size=0.05, shuffle=True, seed=42)
datasets["train"] = train_datasets["train"]
datasets["validation"] = train_datasets["test"]
tokenizer = BertTokenizerFast.from_pretrained(model_path)
def process_function(datas):
sentences = []
labels = []
for sentence1, sentence2, label in zip(datas["句子1"], datas["句子2"], datas["相似度"]):
sentences.append(sentence1)
sentences.append(sentence2)
labels.append(1 if int(label) == 1 else -1)
tokenized_datas = tokenizer(sentences, max_length=256, truncation=True, padding="max_length")
# 这里将2条数据合并为一组,也就是reshape,从(2倍datas数量 * max_length),变成(datas数量 * 2 * max_length)
tokenized_datas = {k: [v[i: i + 2] for i in range(0, len(v), 2)] for k, v in tokenized_datas.items()}
tokenized_datas["labels"] = labels
return tokenized_datas
new_datasets = datasets.map(process_function, batched=True)
# step 3 加载模型
class SimilarityModel(BertPreTrainedModel):
def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.bert = BertModel(config)
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# Step1 分别获取sentenceA 和 sentenceB的输入
senA_input_ids, senB_input_ids = input_ids[:, 0], input_ids[:, 1]
senA_attention_mask, senB_attention_mask = attention_mask[:, 0], attention_mask[:, 1]
senA_token_type_ids, senB_token_type_ids = token_type_ids[:, 0], token_type_ids[:, 1]
# Step2 分别获取sentenceA 和 sentenceB的向量表示
senA_outputs = self.bert(
senA_input_ids,
attention_mask=senA_attention_mask,
token_type_ids=senA_token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
senA_pooled_output = senA_outputs[1] # [batch, hidden]
senB_outputs = self.bert(
senB_input_ids,
attention_mask=senB_attention_mask,
token_type_ids=senB_token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
senB_pooled_output = senB_outputs[1] # [batch, hidden]
# step3 计算相似度
cos = CosineSimilarity()(senA_pooled_output, senB_pooled_output) # [batch, ]
# step4 计算loss
loss = None
if labels is not None:
loss_fct = CosineEmbeddingLoss(0.3)
loss = loss_fct(senA_pooled_output, senB_pooled_output, labels)
output = (cos,)
return ((loss,) + output) if loss is not None else output
model = SimilarityModel.from_pretrained(model_path)
# step 4 评估函数:此处的评估函数可以从https://github.com/huggingface/evaluate下载到本地
acc_metric = evaluate.load("./evaluate/metric_accuracy.py")
f1_metric = evaluate.load("./evaluate/metric_f1.py")
def evaluate_function(eval_predict):
predictions, labels = eval_predict
predictions = [int(p > 0.7) for p in predictions]
labels = [int(l > 0) for l in labels]
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metric.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc
# step 5 创建TrainingArguments
# train是4275条数据,batch_size=32,因此每个epoch的step=134,总step=402
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
per_device_eval_batch_size=32, # 验证时的batch_size
num_train_epochs=3, # 训练轮数
logging_steps=50, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
load_best_model_at_end=True # 训练完成后加载最优模型
)
# step 6 创建Trainer
trainer = Trainer(model=model,
args=train_args,
train_dataset=new_datasets["train"],
eval_dataset=new_datasets["validation"],
compute_metrics=evaluate_function,
)
# step 7 训练
trainer.train()
# step 8 模型评估
evaluate_result = trainer.evaluate(new_datasets["test"])
print(evaluate_result)
# step 9 模型预测
class SentenceSimilarityPipeline:
def __init__(self, model, tokenizer) -> None:
self.model = model.bert
self.tokenizer = tokenizer
self.device = model.device
def preprocess(self, senA, senB):
return self.tokenizer([senA, senB], max_length=128, truncation=True, return_tensors="pt", padding=True)
def predict(self, inputs):
inputs = {k: v.to(self.device) for k, v in inputs.items()}
return self.model(**inputs)[1] # [2, 768]
def postprocess(self, logits):
cos = CosineSimilarity()(logits[None, 0, :], logits[None,1, :]).squeeze().cpu().item()
return cos
def __call__(self, senA, senB):
inputs = self.preprocess(senA, senB)
logits = self.predict(inputs)
result = self.postprocess(logits)
if result >= 0.7:
return "相似"
return "不相似"
pipe = SentenceSimilarityPipeline(model, tokenizer)
print(pipe("广东哪里最好玩啊?", "广东最好玩的地方在哪?"))
5 运行效果
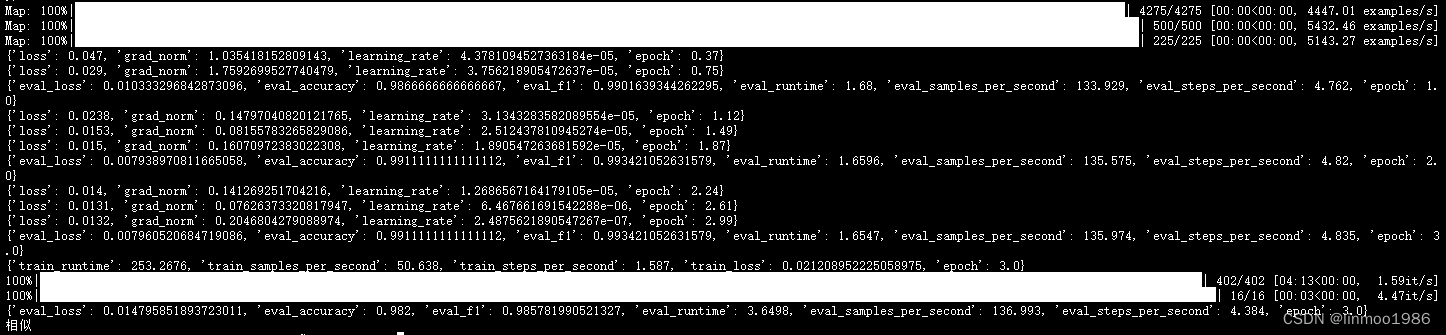
注:本文参考来自大神:https://github.com/zyds/transformers-code



















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











