






构建数据集
这里使用的是torch.rand()函数构建数据集
创建一个
y
=
3
x
+
0.8
y=3x+0.8
y=3x+0.8的线性函数
因为这里的数据量太大,我们选择使用Dataloader将数据集逐步传入进行训练
x_raw = t.rand([20000, 1])
y_raw = x_raw * 3 + .8
batch_size = 10
重写Dataset
根据Pytorch的官方手册,需要重写__getitem__ 方法和 __len__方法
class mydataset(data.Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
self.len = len(x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def __len__(self):
return self.len
ds = mydataset(x_raw, y_raw)
# ds2=data.TensorDataset(x_raw,y_raw)
train_data = data.DataLoader(ds, batch_size=batch_size, shuffle=True)
这里的重写只是我想学学怎么重写,实际上可以使用TensorDataset方法
构建网络
写我们的神经网络类的时候需要继承nn.Module类,在这里我们使用nn.Linear()构建网络
class net(nn.Module):
def __init__(self, batch_size):
super(net, self).__init__()
self.l1 = nn.Linear(batch_size, 1)
def forward(self, x):
out = self.l1(x)
return out
损失函数
损失函数是网络得以运行的关键,我们使用nn.MSELoss()计算均方误差
MSEloss主要用于回归问题 CrossEntropyLoss 交叉熵损失主要用于分类问题
def get_loss(out, y):
loss = nn.MSELoss()
l = loss(out, y)
return l
优化器
我们在这里选择SGD优化器,将学习率lr设置为1e-2
optimizer = t.optim.SGD(n.parameters(), lr=1e-2)
开始训练
n = net(1)
n.to('cuda')
for i in range(10):
total_loss = 0
for x, y in train_data:
x = x.to('cuda')
y = y.to('cuda')
out = n(x)
loss = get_loss(out, y)
optimizer.zero_grad()
loss.backward()
total_loss += loss
optimizer.step()
if (i + 1) % 2 == 0:
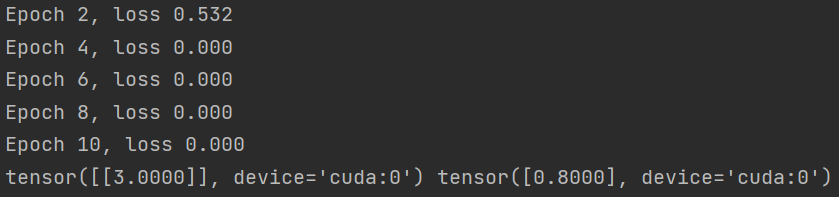
print('Epoch %d, loss %.3f' % (i + 1, total_loss))
print(n.l1.weight.data, n.l1.bias.data)
运行结果
我之前也写过关于sklearn的线性回归,想看的小伙伴可以点这里















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









