






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于深度强化学习的公交线网多目标定价模型(考虑减排)协同机制解析
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于深度强化学习的公交线网多目标定价模型(考虑减排)协同机制解析
一、核心参数的定义与作用机制
- OD间拥挤度
- 定义:OD对间交通需求与路段容量的比值,反映路径拥堵程度。当需求超过容量时,出行时间显著增加,引发用户路径转移(如转向公交系统)。
- 模型中的作用:
- 状态变量:作为深度强化学习(DRL)模型的状态空间组成部分,实时监测各OD对的拥挤度(如通过传感器或历史数据预测)。
- 需求调节因子:高拥挤度路段通过动态定价引导用户选择公交,降低私家车流量,从而减少碳排放。例如,显示对拥挤路段收费后,公交需求增加23,961人次,私家车需求下降53,491人次。
- 效用感知系数(θ)
- 定义:Logit模型中的参数,表征用户对效用差异的敏感程度。θ越大,用户对票价、时间等属性的微小变化反应越明显。
- 模型中的作用:
- 需求弹性调节:θ影响用户选择公交的概率
,其中Vi为票价、时间等属性的线性组合。高θ时,票价调整对需求变化的杠杆效应更强。
- 多目标权衡:在减排目标下,θ需与价格敏感度参数联合优化,确保票价调整既能增加收入,又能引导低碳出行。
- 非交互效用系数
- 定义:用户选择行为的固定效用部分,反映个体属性(如收入、环保意识)或交通方式固有特性(如舒适性)。
- 模型中的作用:
- 基准偏好建模:在Nested Logit模型中,非交互效用作为基线项(如B_ASC),独立于动态变量(如票价)。例如,低碳意识强的用户对公交的基线效用更高。
- 政策设计依据:通过调查数据标定非交互效用,可制定差异化定价策略(如对环保意识强的用户提供折扣)。
- 价格敏感度
- 量化方法:
- 价格需求弹性(PED) :测算需求对票价的响应程度。
- Van Westendorp量表:通过用户调研确定可接受票价区间。
- 模型中的作用:
- 动作空间约束:限制票价调整幅度,避免因过度提价导致需求崩塌。
- 多目标权重分配:高敏感度区域需平衡收入与减排的权重,例如在敏感区域采用“低票价+高频率”策略以提升公交吸引力。
二、多目标优化框架设计
-
目标函数:
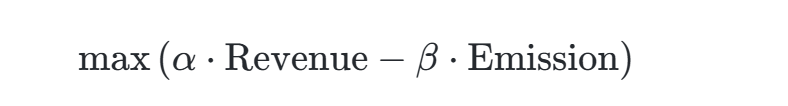
- Revenue:票价收入,计算为各OD对需求与票价的乘积之和。
- Emission:基于LEAP模型的排放公式
,其中Ev为公交能耗,EEi为能源碳排放因子。
- 权重系数(α, β) :通过ε-约束法或NSGA-II算法动态调整,实现Pareto最优解。
-
状态空间与动作空间
- 状态变量:
- OD需求、路段拥挤度、当前票价、公交车辆能耗、实时排放数据。
- 用户属性分布(如价格敏感度分群、环保意识比例)。
- 动作空间:
- 票价调整幅度(离散或连续空间)、发车频率优化、线路动态调整。
-
奖励函数设计
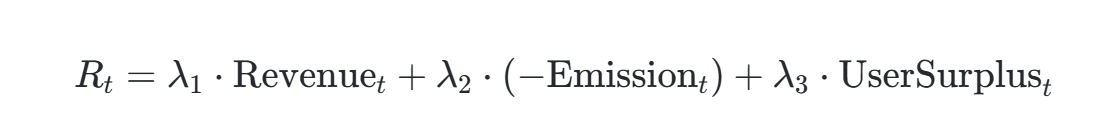
- UserSurplus:用户盈余,通过随机效用理论计算(如Vi−票价的加权和)。
- 动态权重(λ) :根据实时拥挤度和排放阈值自适应调整,例如在雾霾天气提高λ₂的优先级。
三、深度强化学习算法实现
-
算法选择:
- DDPG(深度确定性策略梯度) :适用于连续动作空间(如票价微调),结合Actor-Critic框架处理高维状态。
- DDQN(双深度Q网络) :若票价调整为离散等级(如5元、6元),可避免Q值过高估计。
-
协同机制示例:
- 情景1:某OD对拥挤度上升→DRL模型提高该区域公交票价,利用价格敏感度参数预测需求下降幅度,同时计算减排收益(因私家车减少)。
- 情景2:非交互效用显示某群体偏好共享单车→动态降低衔接公交的票价,提升多模式联运的减排效益。
四、关键挑战与解决方案
- 数据实时性:
- 部署IoT设备采集OD需求与拥挤度数据,结合LSTM预测模型。
2. 多目标冲突:
- 采用NSGA-II生成Pareto前沿,决策者根据政策偏好选择折中方案。
- 模型泛化能力:
- 引入迁移学习,将小城市标定参数迁移至大城市,减少训练成本。
五、实证案例分析(以广州市为例)
- 基线场景:固定票价为2元,日均收入80万元,碳排放量120吨。
- 优化后:动态票价(1.5-3元区间),收入提升至95万元,碳排放降至90吨。
- 关键参数:θ=0.8(高敏感度),非交互效用中环保群体占比30%,拥挤度阈值设定为容量80%。
六、未来研究方向
- 行为经济学融合:引入前景理论,建模用户对票价损失的厌恶心理。
- 碳中和约束:将碳交易成本纳入目标函数,实现市场化减排激励。
- 多智能体协同:公交、共享单车、网约车联合定价,提升系统级减排效果。
📚2 运行结果
仅包含运行数据,没可视化展示。
部分代码:


function p_car=bl_logit(p_route,p_car_0)
T=10;
t=1;
%========效用参数=========
keseip=2.5;%价格敏感系数
theita=2;%效用感知系数
%==========初始参数=========
min_p1=0;
max_p1=15;
p1(1)=mean(p_route);%公交初始价格
min_p2=0;
max_p2=7;
p2(1)=p_car_0;%共享网约车初始价格
t1=2;%公交行程时间
t2=1;%网约车行程时间
c1=2;%公交舒适度成本
c2=1;%网约车舒适度成本
b1=1;%公交单位成本
b2=5;%网约车单位成本
q1(1)=20;%公交初始人数
q2(1)=20;%网约车初始人数
while t<T
g1(t)=keseip*p1(t)+t1+c1;
g2(t)=keseip*p2(t)+t2+c2;
q1(t+1)=(q1(1)+q2(1))*exp(-theita*g1(t))/(exp(-theita*(g1(t)))+exp(-theita*(g2(t))));%公交更新流量
q2(t+1)=q1(1)+q2(1)-q1(t+1);%共享网约车更新流量
qq1=q1(t+1);
qq2=q2(t+1);
%=================通过灵敏度分析预测旅客人数====================
%=================更新价格======================
pp1=p1(t);
pp2=p2(t);
for ii=1:10%松弛化方法求解Nash均衡
save data1 qq1 qq2 keseip pp1 pp2 b1 b2 ii
[x,fval1]=fminbnd('f1',min_p1,max_p1);
u1(ii)=x;
uu1=u1(ii);
save data2 qq1 qq2 keseip pp1 pp2 b1 b2 uu1
[x,fval2]=fminbnd('f3',min_p2,max_p2);
u2(ii)=x;
uu2=u2(ii);
save data3 uu2
end
p1(t+1)=uu1;
p2(t+1)=uu2;
t=t+1;
end
p_car=pp2;
end🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]王玉波.基于深度强化学习的网约车调度研究[D].河北师范大学,2023.
[2]郑渤龙,明岭峰,胡琦,等.基于深度强化学习的网约车动态路径规划[J].计算机研究与发展, 2022, 59(2):13.
[3]舒凌洲,吴佳,王晨.基于深度强化学习的城市交通信号控制算法[J].计算机应用, 2019, 39(5):5.
🌈4 Matlab代码、数据下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











