






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。当哲学课上老师问你什么是科学,什么是电的时候,不要觉得这些问题搞笑。哲学是科学之母,哲学就是追究终极问题,寻找那些不言自明只有小孩子会问的但是你却回答不出来的问题。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能让人胸中升起一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它居然给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
将深度确定性策略梯度(DDPG)强化学习模型控制温度的性能与比例-积分-微分(PID)控制器和恒温器控制器的性能进行比较研究文档
深度确定性策略梯度(DDPG)算法是一种无模型、在线、离策略的强化学习方法。DDPG智能体是一种行动者-评论家(actor-critic)强化学习智能体,它计算出一个最优策略,以最大化长期奖励。
在训练过程中,DDPG智能体:
- 在学习期间的每个时间步更新行动者(actor)和评论家(critic)的属性。
- 使用循环经验缓冲区存储过去的经验。智能体从缓冲区中随机采样一个小批量经验来更新行动者和评论家。
- 在每个训练步骤中,使用随机噪声模型对策略选择的动作进行扰动。
这种方法允许智能体在探索和利用之间找到平衡,通过随机扰动动作来增加探索的多样性,同时利用经验缓冲区中的过去经验来优化策略。DDPG算法特别适用于连续动作空间的问题,因为它能够直接输出一个确定性的动作,而不是动作的概率分布。
温度控制-强化学习
比较深度确定性策略梯度(DDPG)强化学习模型、PID控制器和恒温器控制器在温度控制方面的性能。
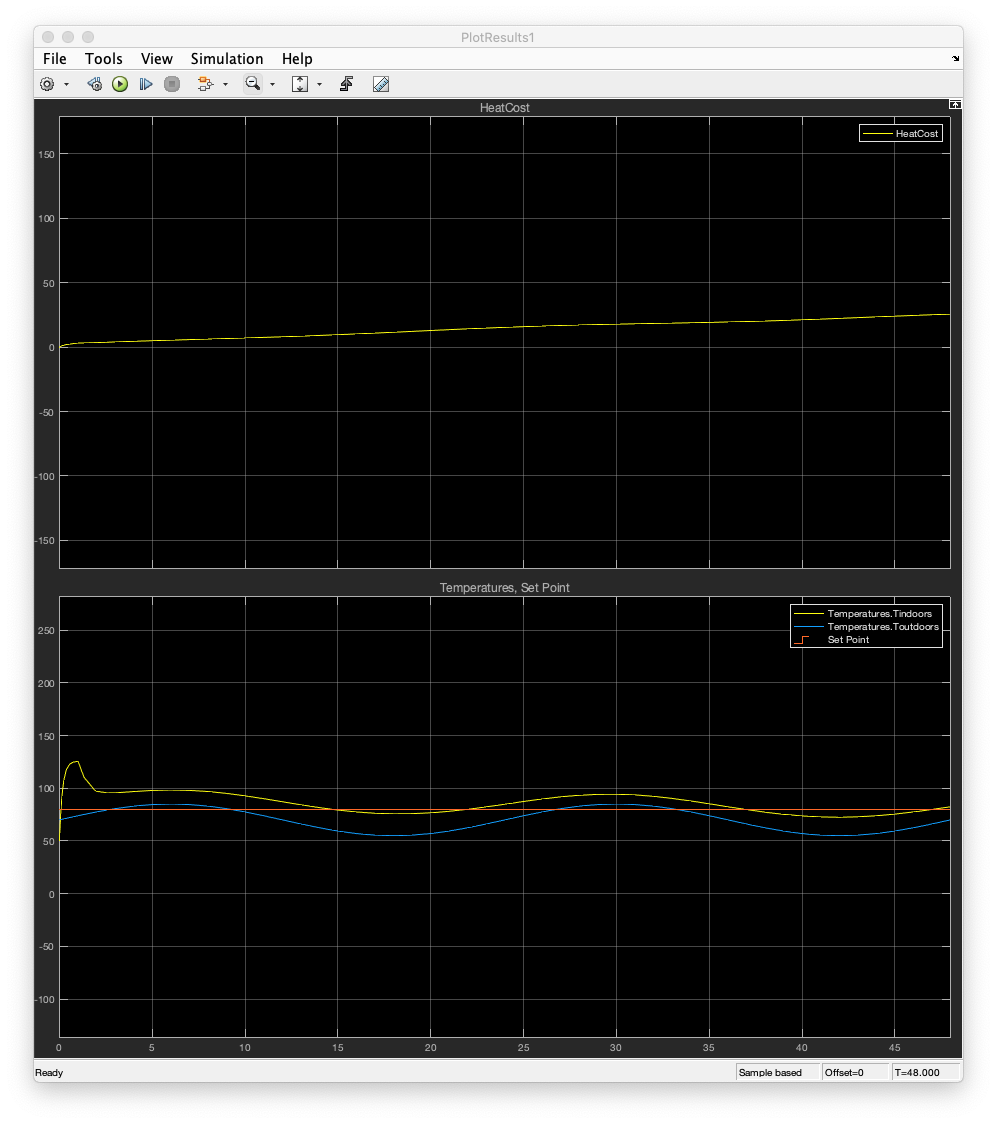
恒温器控制器控制温度:
均方误差 - 32.7782(恒温器控制器)
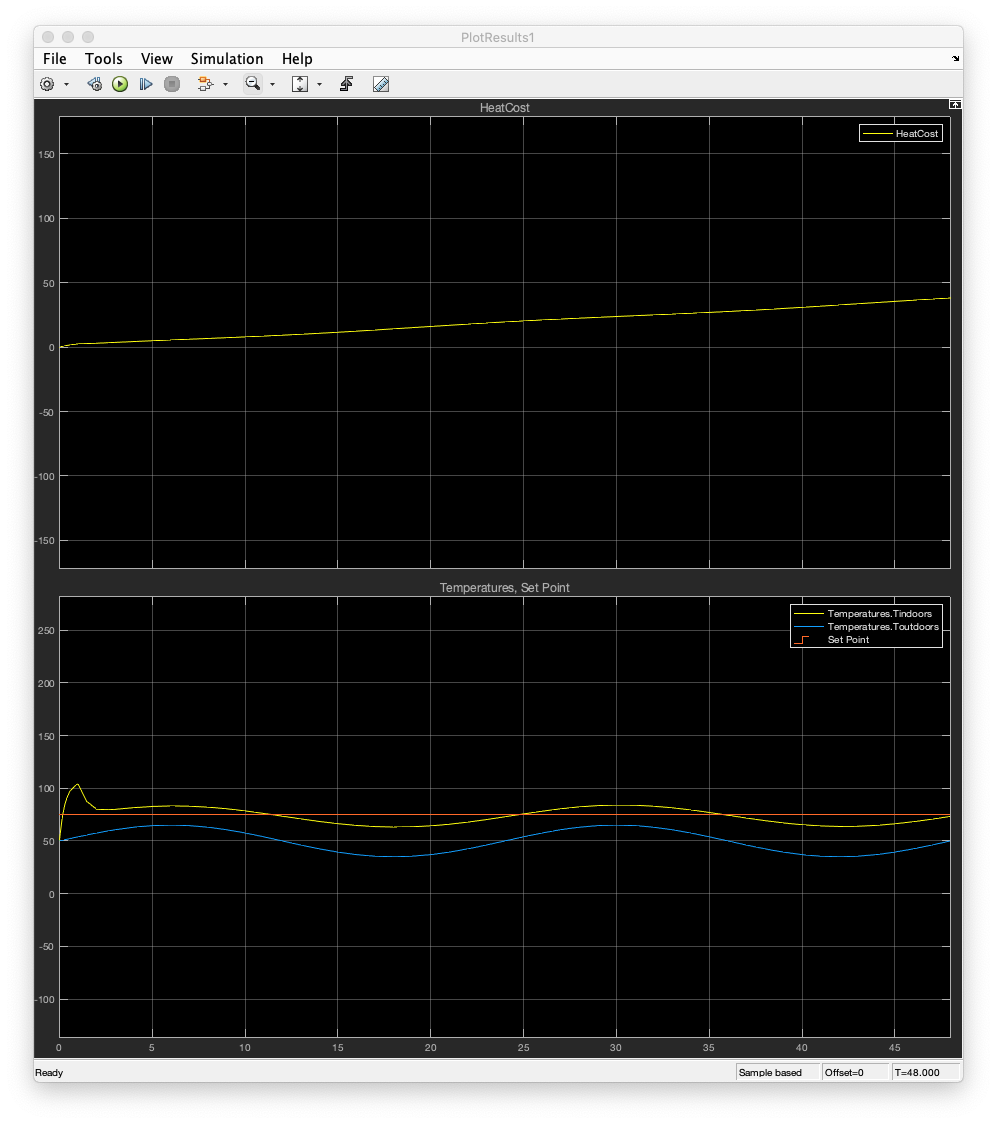
PID控制器控制温度:
均方误差 - 23.9247(PID控制器)
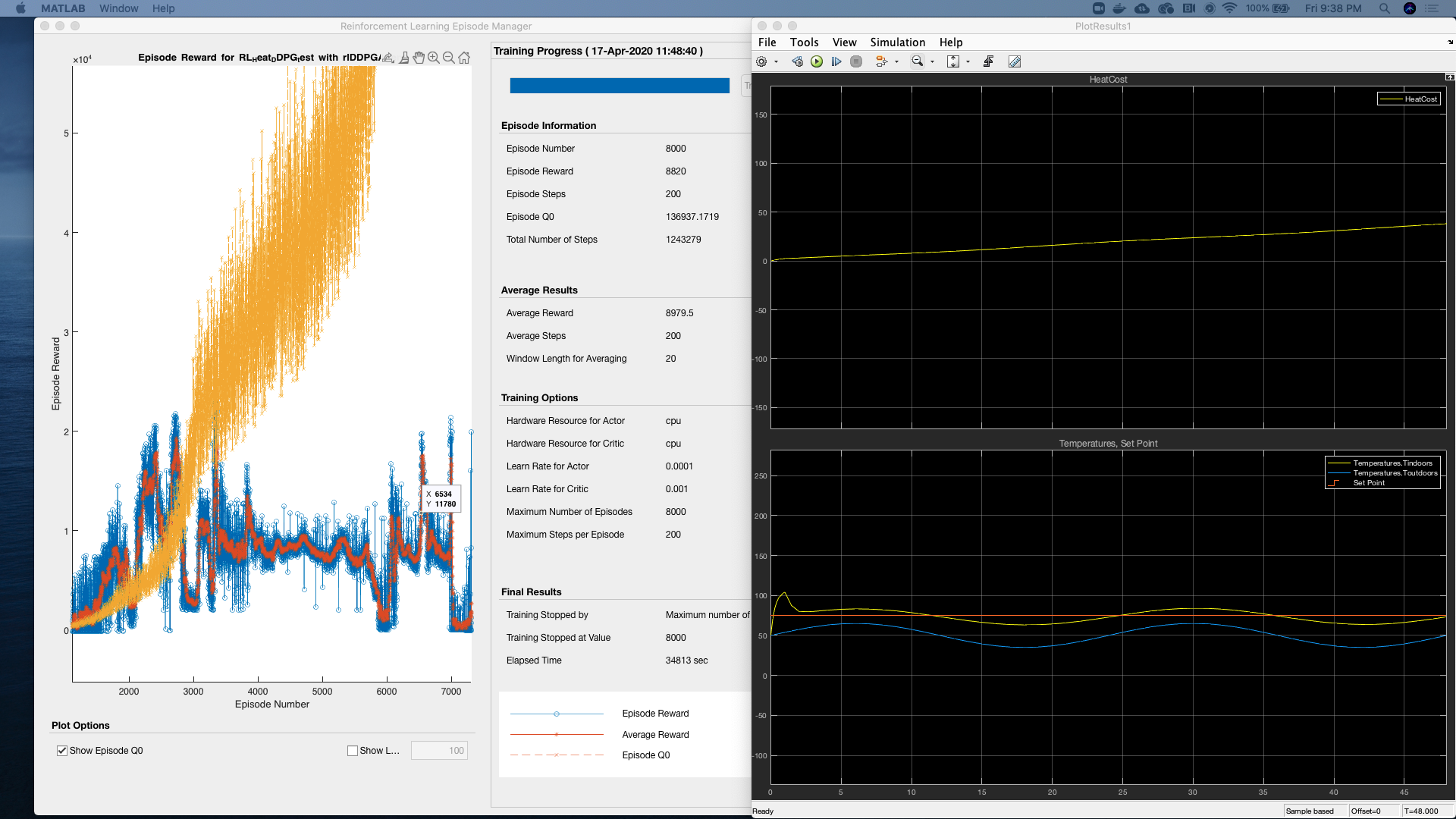
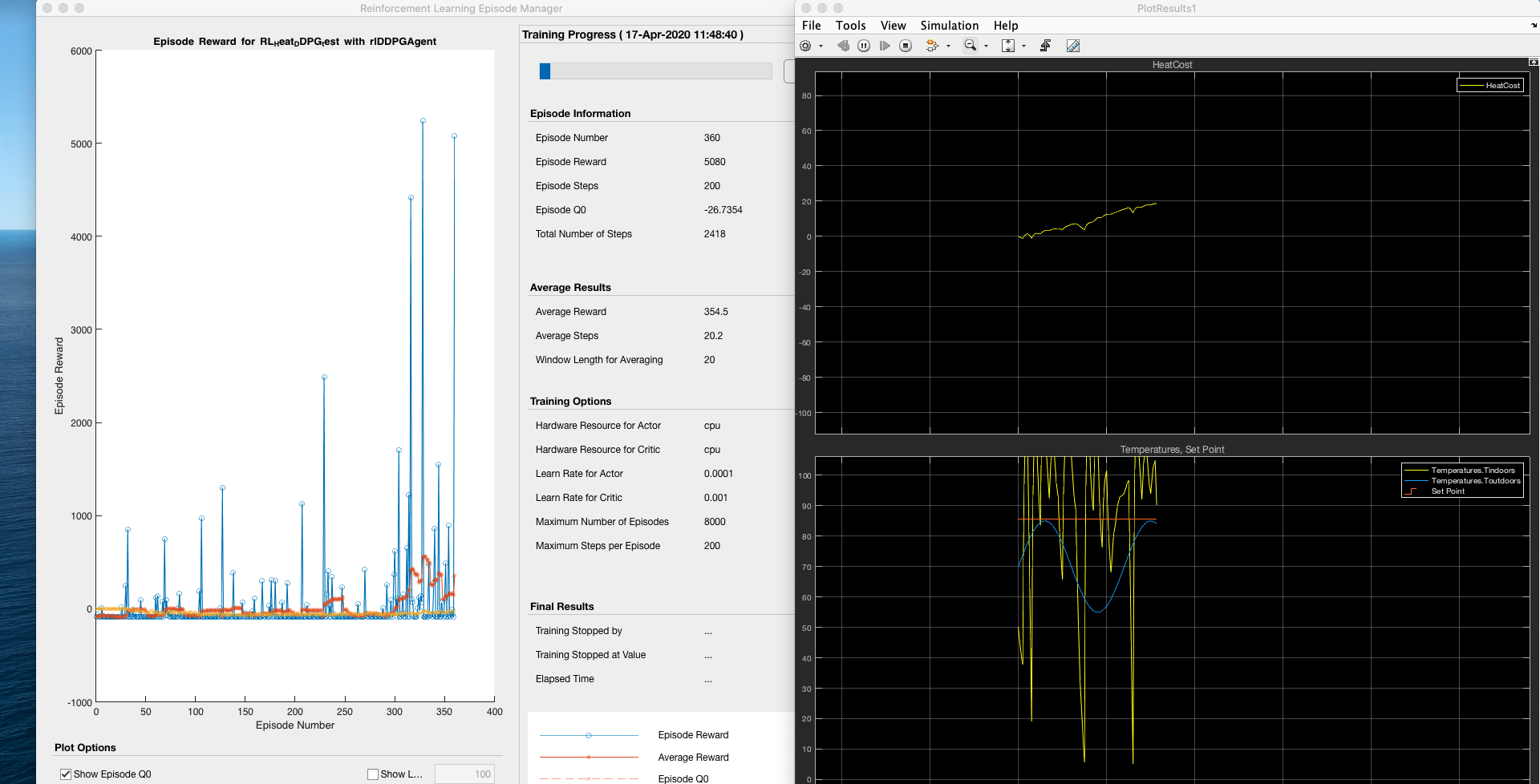
DDPG RL智能体控制器控制温度:
均方误差 - 26.8667(RL控制器)
重建模型的步骤:
- 运行sldemo_househeat_data.m,确保工作区中存在变量。
- 运行house_thermostat.slx以生成使用普通恒温器控制的图表。
- 运行house_PID.slx以生成使用离散PID控制器控制的图表。
- 打开ddpg_live(new).mlx实时笔记本。开始逐个运行每个单元格。(确保笔记本中的变量“training”设置为true。)
注意:
要成功重建这些模拟,请确保已安装以下工具箱:
- 强化学习工具箱
- 机器学习工具箱
- PID Tuner
使用MATLAB 2020a运行文件。
温度控制-强化学习比较研究
一、研究目的
本研究旨在比较深度确定性策略梯度(DDPG)强化学习模型、比例-积分-微分(PID)控制器和恒温器控制器在温度控制方面的性能,以评估DDPG强化学习模型在温度控制任务中的有效性和优势。
二、性能指标
本研究采用均方误差(Mean Squared Error, MSE)作为性能评估指标,以量化不同控制器在温度控制过程中的误差大小。MSE值越小,表示控制器的性能越好。
三、实验结果
-
恒温器控制器控制温度:
- 均方误差:32.7782
恒温器控制器虽然简单易懂,但在温度控制过程中存在较大的误差,难以满足高精度温度控制的需求。
-
PID控制器控制温度:
- 均方误差:23.9247
PID控制器通过调整比例、积分和微分三个参数,实现了对温度的较为精确的控制,相比恒温器控制器,其性能有了显著提升。
-
DDPG RL智能体控制器控制温度:
- 均方误差:26.8667
DDPG强化学习模型通过不断学习和优化策略,实现了对温度的有效控制。虽然其性能略逊于PID控制器,但作为一种自适应控制方法,DDPG模型在复杂环境中具有更强的适应性和鲁棒性。
四、重建模型步骤
为确保本研究结果的可重复性和准确性,以下是重建模型的详细步骤:
- 运行
sldemo_househeat_data.m,确保工作区中存在所需的变量。 - 打开并运行
house_thermostat.slx,生成使用普通恒温器控制的图表。 - 打开并运行
house_PID.slx,生成使用离散PID控制器控制的图表。 - 打开
ddpg_live(new).mlx实时笔记本,并逐个运行每个单元格。在运行前,请确保笔记本中的变量training设置为true,以便进行训练。
五、注意事项
- 为成功重建这些模拟,请确保已安装以下工具箱:
- 强化学习工具箱
- 机器学习工具箱
- PID Tuner
- 在运行笔记本时,请确保计算机具有足够的计算资源和内存,以避免训练过程中出现内存不足或计算缓慢的问题。
六、结论
本研究通过比较DDPG强化学习模型、PID控制器和恒温器控制器在温度控制方面的性能,发现PID控制器在均方误差方面表现最优,而DDPG强化学习模型虽然性能略逊于PID控制器,但作为一种自适应控制方法,其在复杂环境中具有更强的适应性和鲁棒性。未来研究可以进一步探索DDPG强化学习模型在温度控制任务中的优化方法,以提高其性能。
📚2 运行结果
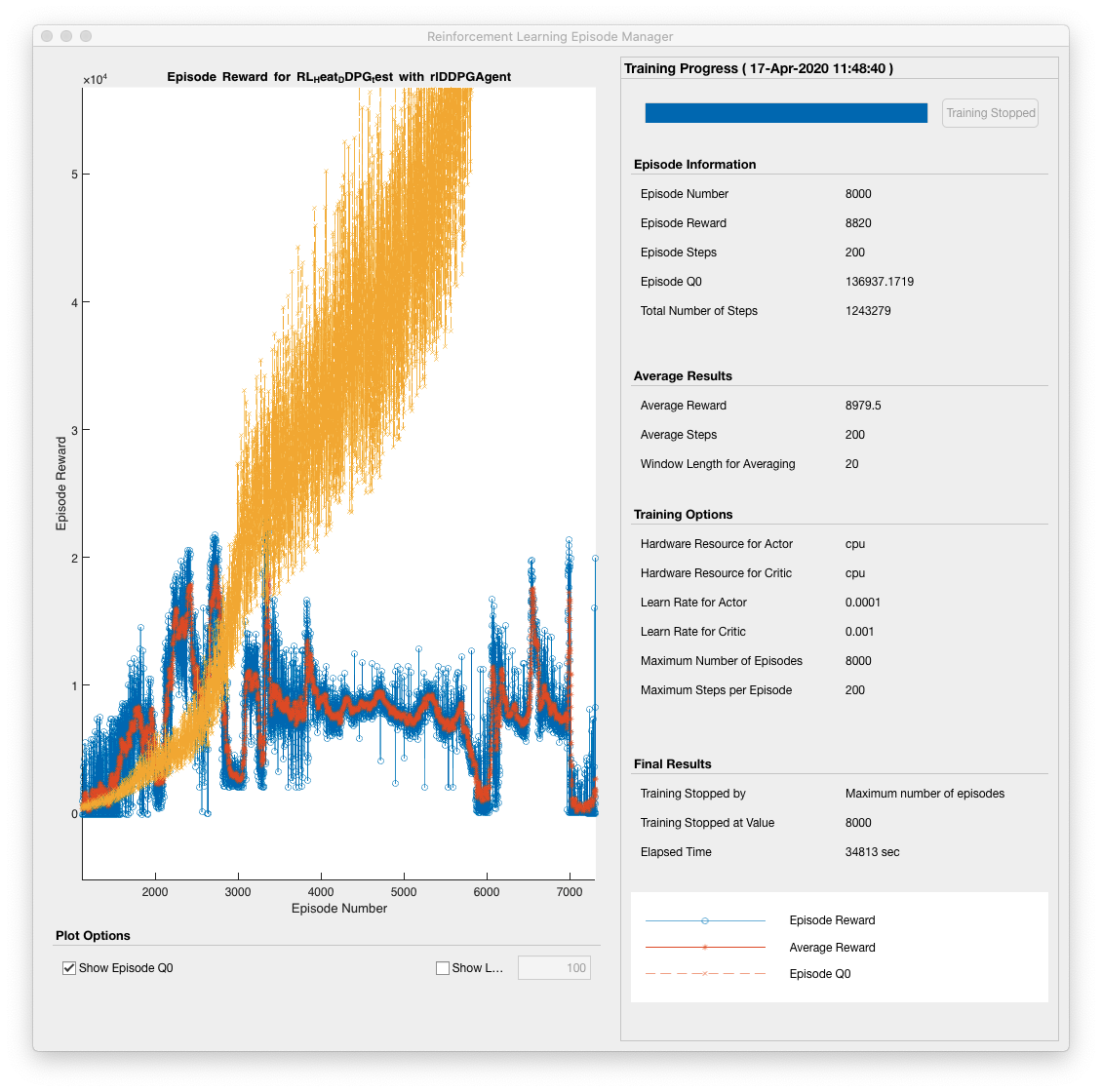
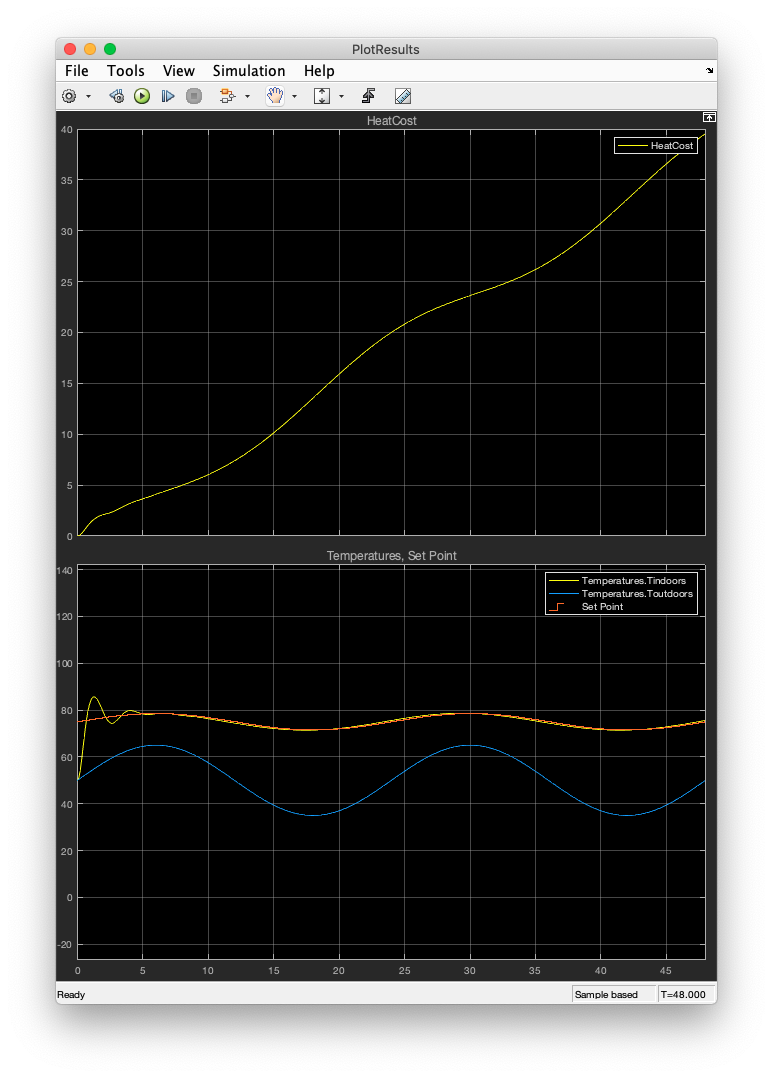
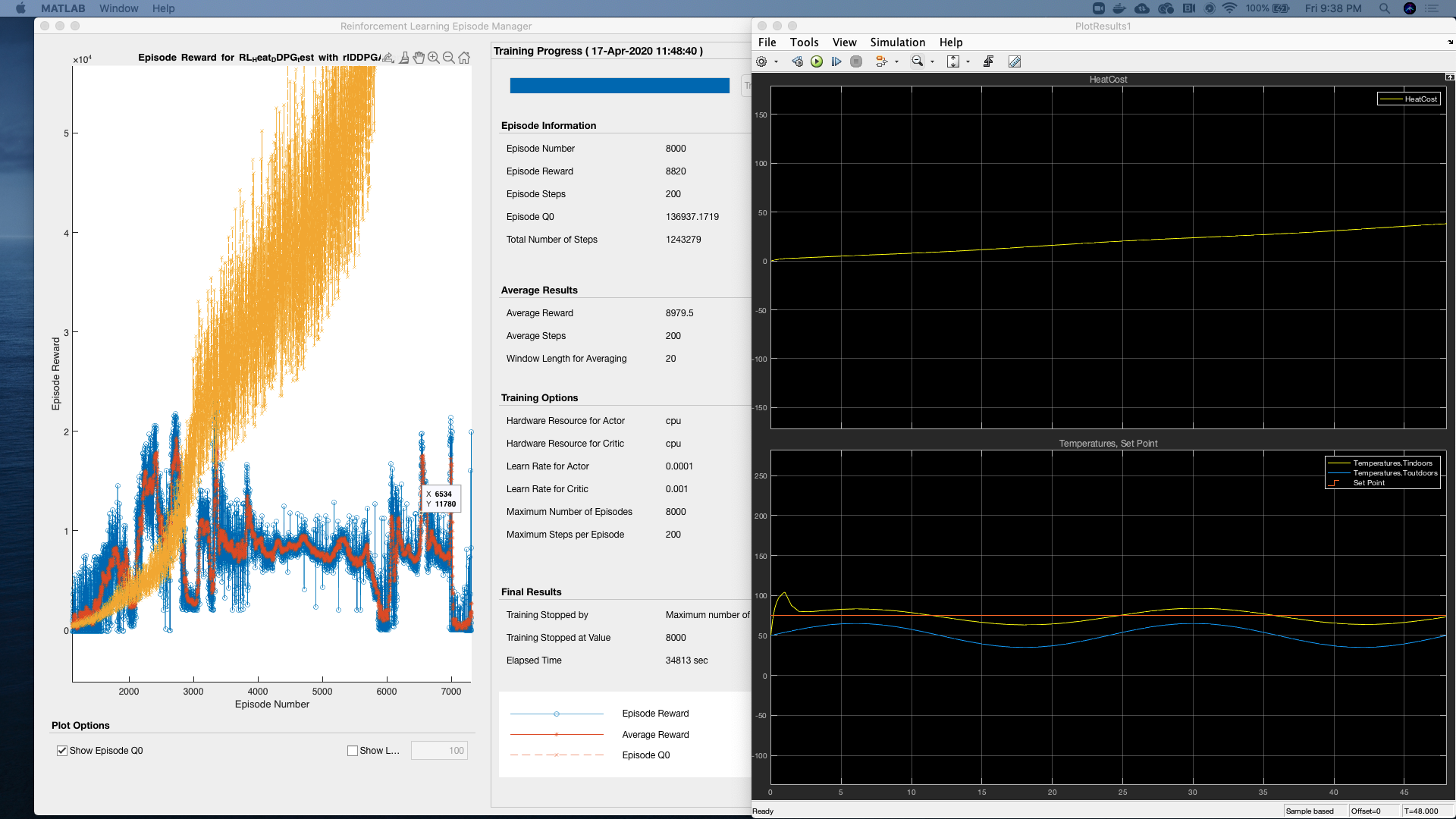
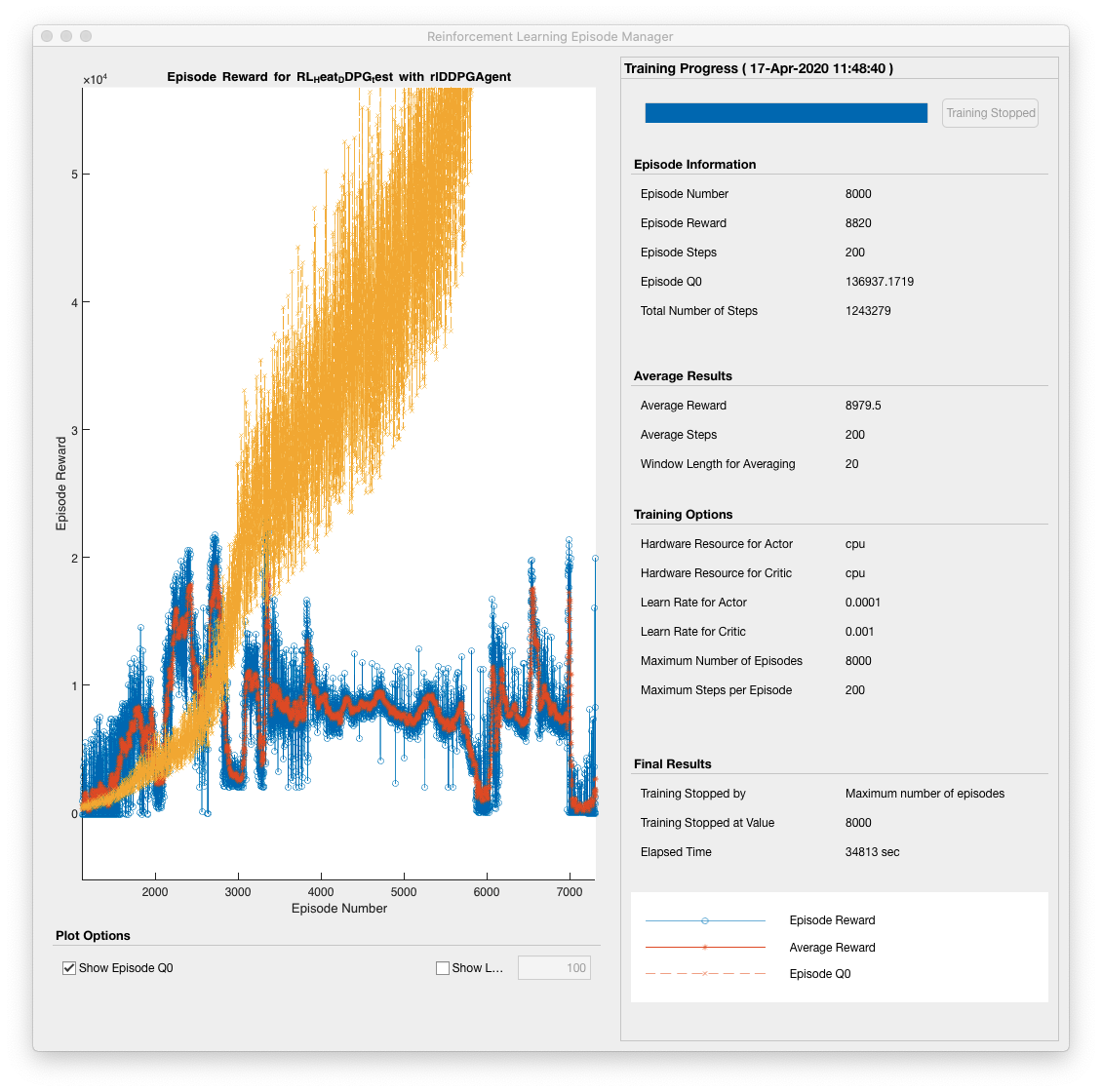
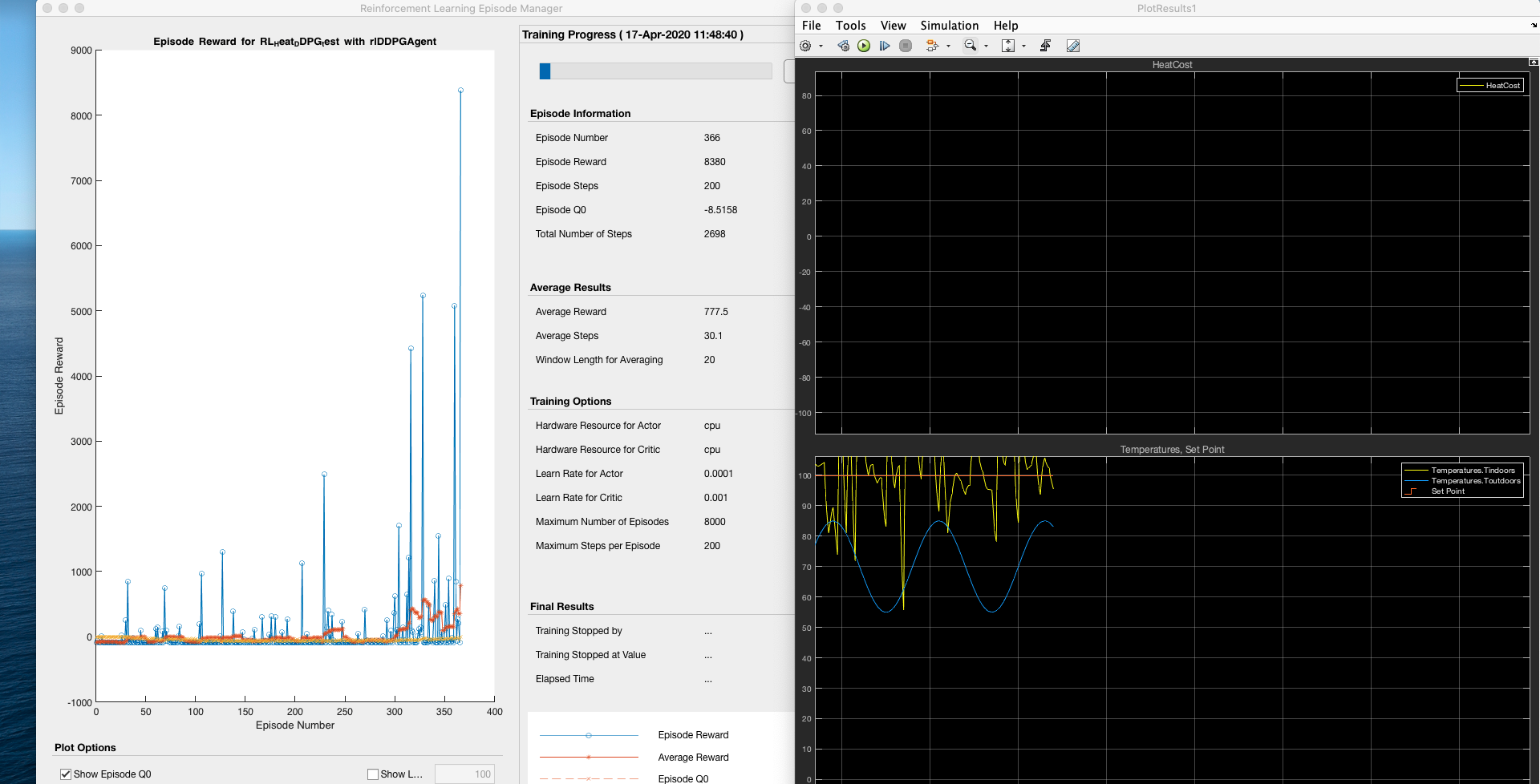
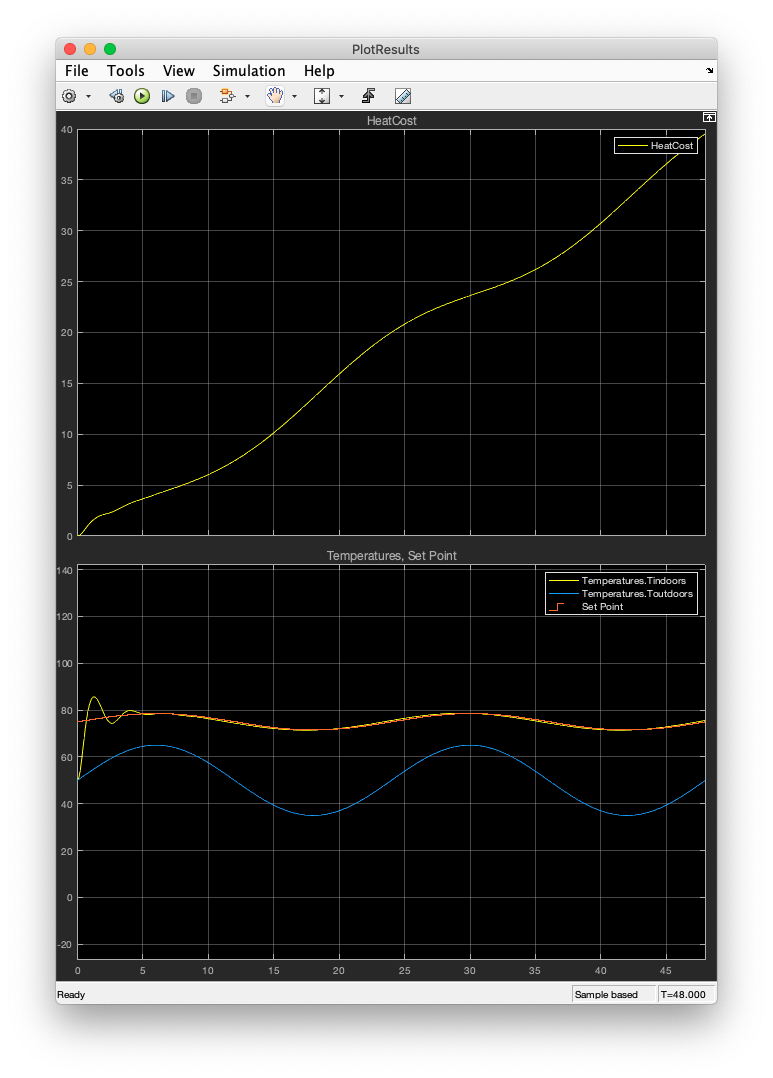
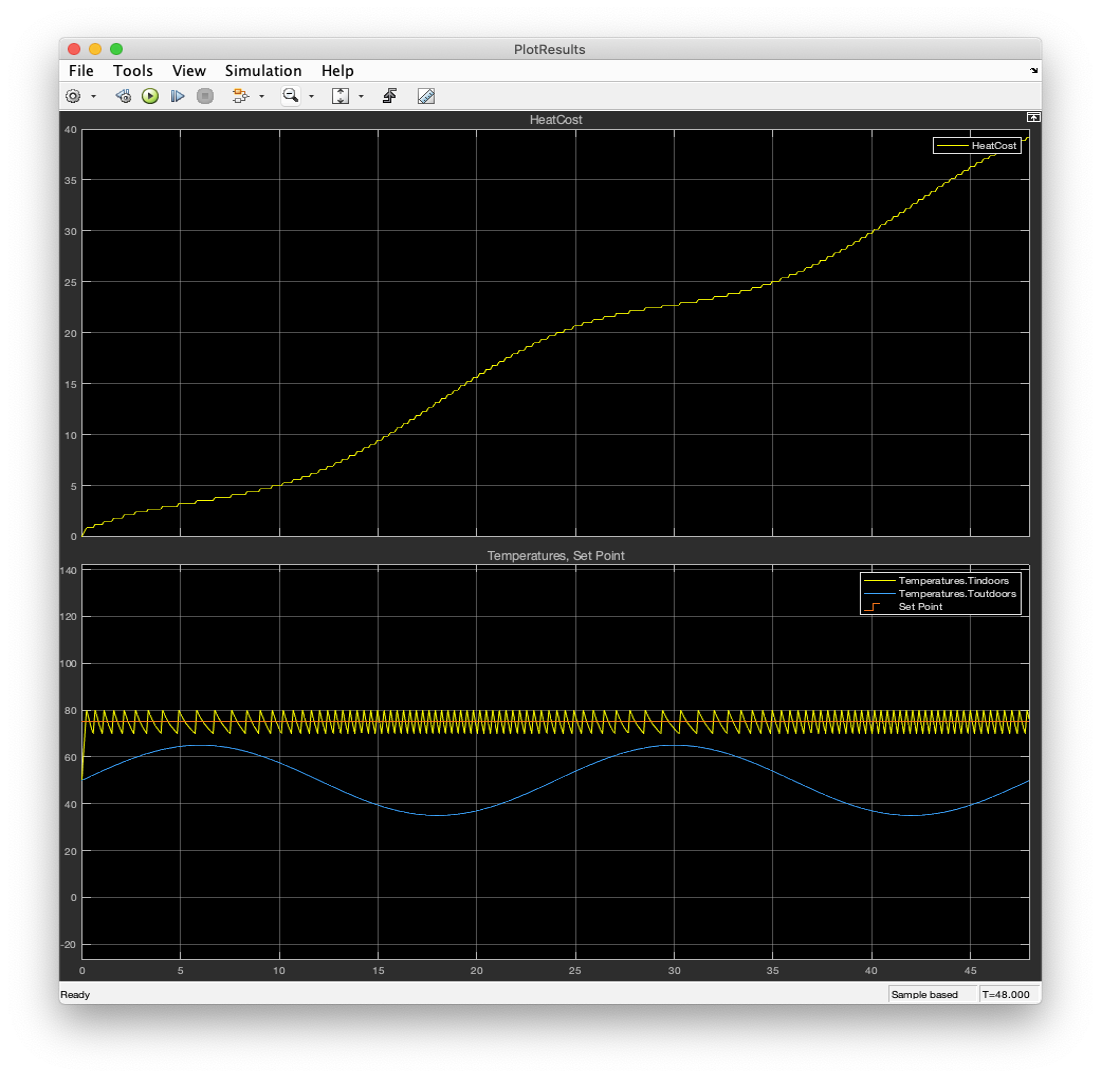
部分代码:
% -------------------------------
% converst radians to degrees
r2d = 180/pi;
% -------------------------------
% Define the house geometry
% -------------------------------
% House length = 30 m
lenHouse = 30;
% House width = 10 m
widHouse = 10;
% House height = 4 m
htHouse = 4;
% Roof pitch = 40 deg
pitRoof = 40/r2d;
% Number of windows = 6
numWindows = 6;
% Height of windows = 1 m
htWindows = 1;
% Width of windows = 1 m
widWindows = 1;
windowArea = numWindows*htWindows*widWindows;
wallArea = 2*lenHouse*htHouse + 2*widHouse*htHouse + ...
2*(1/cos(pitRoof/2))*widHouse*lenHouse + ...
tan(pitRoof)*widHouse - windowArea;
% -------------------------------
% Define the type of insulation used
% -------------------------------
% Glass wool in the walls, 0.2 m thick
% k is in units of J/sec/m/C - convert to J/hr/m/C multiplying by 3600
kWall = 0.038*3600; % hour is the time unit
LWall = .2;
RWall = LWall/(kWall*wallArea);
% Glass windows, 0.01 m thick
kWindow = 0.78*3600; % hour is the time unit
LWindow = .01;
RWindow = LWindow/(kWindow*windowArea);
% -------------------------------
% Determine the equivalent thermal resistance for the whole building
% -------------------------------
Req = RWall*RWindow/(RWall + RWindow);
% c = cp of air (273 K) = 1005.4 J/kg-K
c = 1005.4;
% -------------------------------
% Enter the temperature of the heated air
% -------------------------------
% The air exiting the heater has a constant temperature which is a heater
% property. THeater = 50 deg C
THeater = 60;
% Air flow rate Mdot = 1 kg/sec = 3600 kg/hr
Mdot = 3600; % hour is the time unit
% -------------------------------
% Determine total internal air mass = M
% -------------------------------
% Density of air at sea level = 1.2250 kg/m^3
densAir = 1.2250;
M = (lenHouse*widHouse*htHouse+tan(pitRoof)*widHouse*lenHouse)*densAir;
% -------------------------------
% Enter the cost of electricity and initial internal temperature
% -------------------------------
% Assume the cost of electricity is $0.09 per kilowatt/hour
% Assume all electric energy is transformed to heat energy
% 1 kW-hr = 3.6e6 J
% cost = $0.09 per 3.6e6 J
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]王琪.基于联邦强化学习的综合能源系统经济调度策略研究[D].华北电力大学(北京),2023.
[2]杜牵.基于风险评估和深度强化学习的自动驾驶决策方法研究[D].齐鲁工业大学,2024.
[3]陆鹏,付华,卢万杰.基于深度确定性策略梯度与模糊PID的直流微电网VRB储能系统就地层功率控制[J].电力系统保护与控制, 2023, 51(18):94-105.
🌈4 Matlab代码、Simulink仿真、PPT
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取




















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











