




b站的up主刘二大人的《PyTorch深度学习实践》P6 笔记+代码,视频链接。
目录
1、二分类的交叉熵损失(Binary Cross-Entropy,简称 BCE):
一、Sigmoid函数
介绍:Sigmoid函数是一类S形的非线性激活函数,饱和型函数。下面介绍几种函数:Logistic函数、Tanh函数、Softsign 函数、Arctan 函数。在无特殊说明的时候,Sigmoid函数默认为Logistic函数。
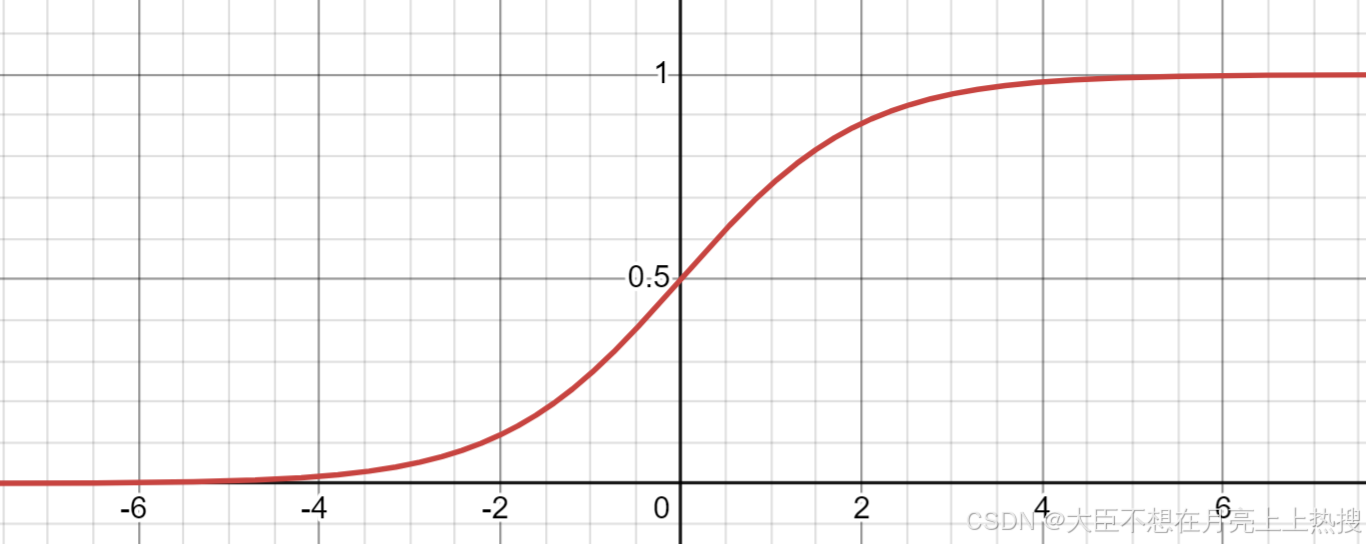
1、Logistic函数(最常用Sigmoid函数)
公式:
特性:输出范围为,适合处理二分类问题,表示概率值。
函数图像:
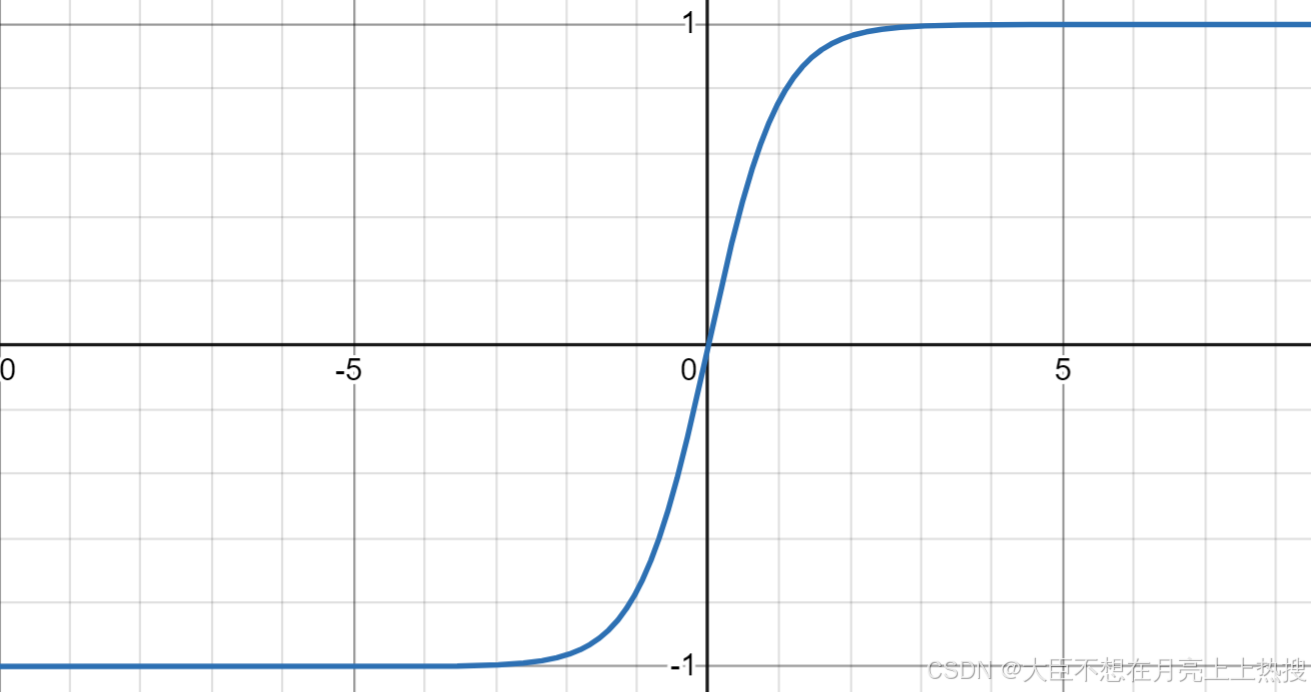
2、 Tanh函数
公式:
特性:输出范围为,适用于处理输入值可以是正、负的情形。
函数图像:
3、Softsign 函数
公式:
特性:输出范围为。Softsign在趋近于极值时变化较慢,比Tanh更平滑。
函数图像:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8257
8257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









