






关于VMD的介绍,这里就不赘述了,前面已经有详细说明了,如果有疑问,大家可以去CSDN其他博主上面去寻求答案,因为每个人的疑问点不同,多看几篇,会有整体的认识。
这篇文章是讲如何通过样本熵确定VMD的分解层数。那么下面简要介绍下样本熵。
熵原本是一个热力学概念,是用来描述热力学系统混乱(无序)程度的度量。
九十年代初,Pincus提出的近似熵(APEN, Aproximate Entropy)主要是从衡量时间序列复杂性的角度来度量信号中产生新模式的概率大小,产生新模式的概率越大,序列的复杂性越大,相应的近似熵也越大。近似熵已成功应用于生理性时间序列的分析,如心率信号,血压信号,男性性激素分泌曲线等时间序列的复杂性研究中。样本熵(Sample Entropy)是由Richman和Moornan[12]提出的一种新的时间序列复杂性的度量方法。样本熵在算法上相对于近似熵算法的改进:相对于近似熵而言,样本熵计算的则是和的对数。样本熵旨在降低近似熵的误差,与已知的随机部分有更加紧密的一致性,样本熵是一种与现在的近似熵类似但精度更好的方法。与近似熵相比,样本熵具有两大优势:第一,样本熵不包含自身数据段的比较,它是条件概率的负平均自然对数的精确值,因此样本熵的计算不依赖数据长度;第二,样本熵具有更好的一致性。即如一时间序列比另一时间序列有较高的值的话,那对于其他和值,也具有较高的值。

以上是关于样本熵的介绍,大家看看就好。
下面描述,SE是如何确定VMD的分解层数的。
时间序列越复杂,SE的计算值越大,反之亦然。因此,应用VMD对信号进行分解后,计算每个子序列的SE值,SE最小的序列为所分解序列的趋势项。
当分解数K较小时,可能导致信号分解不足,趋势项中混入其他干扰项,导致SE值变大。当取适当的K值时,趋势项的SE变小。之后,随着分解次数K的增大,SE逐渐趋于稳定。因此,将SE趋于稳定的转折点作为VMD的分解次数,以避免过度分解。

用我自己的数据,得出如下结果:
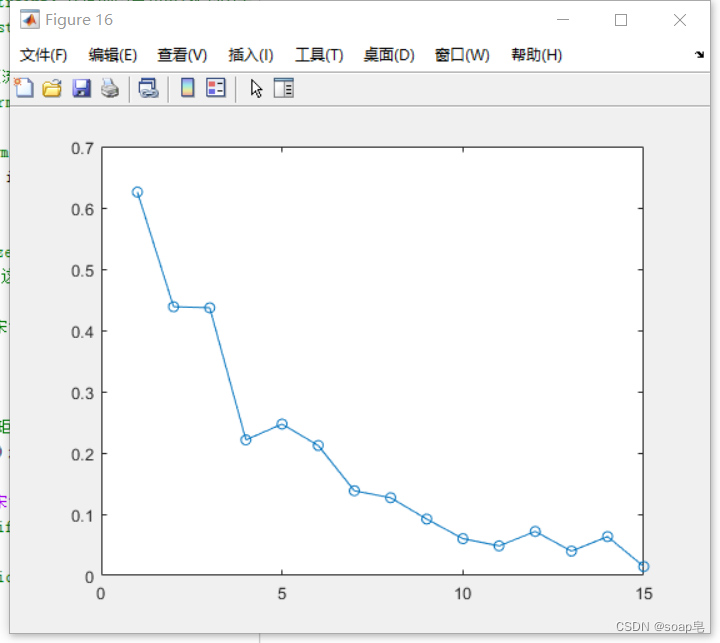
其实结果并不尽如人意。因为并没有一个很稳定的点供我们参考。我们看一下原文的计算结果。
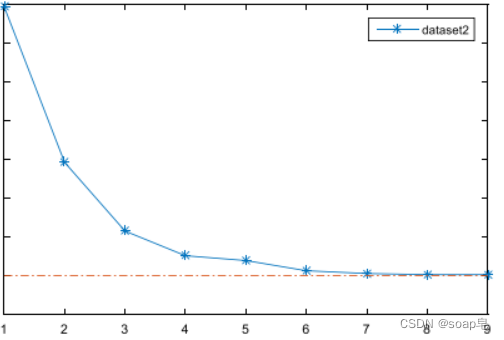
该方法提出的作者,利用自己的数据,得出的结果。由图可看出,比较有稳定的趋势,也很好选取分解的具体层数。
我们这里究其原因,其实作者的原理没有问题,我们的代码编制也没有问题。关键在于每个人的数据不同,从我自己做出的图可以看出,有很明显的下降趋势,最后几个点也趋于平缓,和原文的中的图大致类似。我的最大分解层数是15层,在其他SCI文献中,有的作者在进行VMD分解中,会分成20多层,当然分解的方法不同。
所以,综上,我想表达的观点是,因为数据的不同,该方法可能会产生差异,但是原理和代码没有问题,大家可以参考学习,毕竟这是在SCI期刊上发表出来的一种方法。
另外,有的同学可能会有疑惑,分解出来的子序列,究竟是第一个IMF的SE最小,还是最后一个IMF最小。这是不确定的,可能是第一或者最后一个IMF,也有可能是中间的IMF。不要有这种固定思维。
这是文件包含的代码文件















 2232
2232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









