



引言
随着大型语言模型(LLM)的快速发展,其应用范围不断扩大,但高昂的硬件需求一直是限制普通用户和开发者使用这些强大模型的主要障碍。谷歌最近推出的Gemma 3系列模型及其量化感知训练(QAT)版本,正是为解决这一问题而生。本文将详细介绍Gemma 3 QAT模型如何在大幅降低内存需求的同时保持卓越性能,使仅有8GB VRAM的消费级GPU(如RTX 4060)也能运行先进的AI模型,并探讨如何通过Ollama、LM Studio和AnythingLLM等工具构建完整的本地AI解决方案。
Gemma 3模型与量化感知训练
Gemma 3系列简介
Gemma 3是谷歌最新推出的开源模型系列,基于Gemini技术构建。这个系列具有以下特点:
- 多模态能力:能够处理文本和图像
- 128K上下文窗口:支持长文本理解和生成
- 多语言支持:支持超过140种语言
- 多种参数规模:提供1B、4B、12B和27B四种参数规模的模型
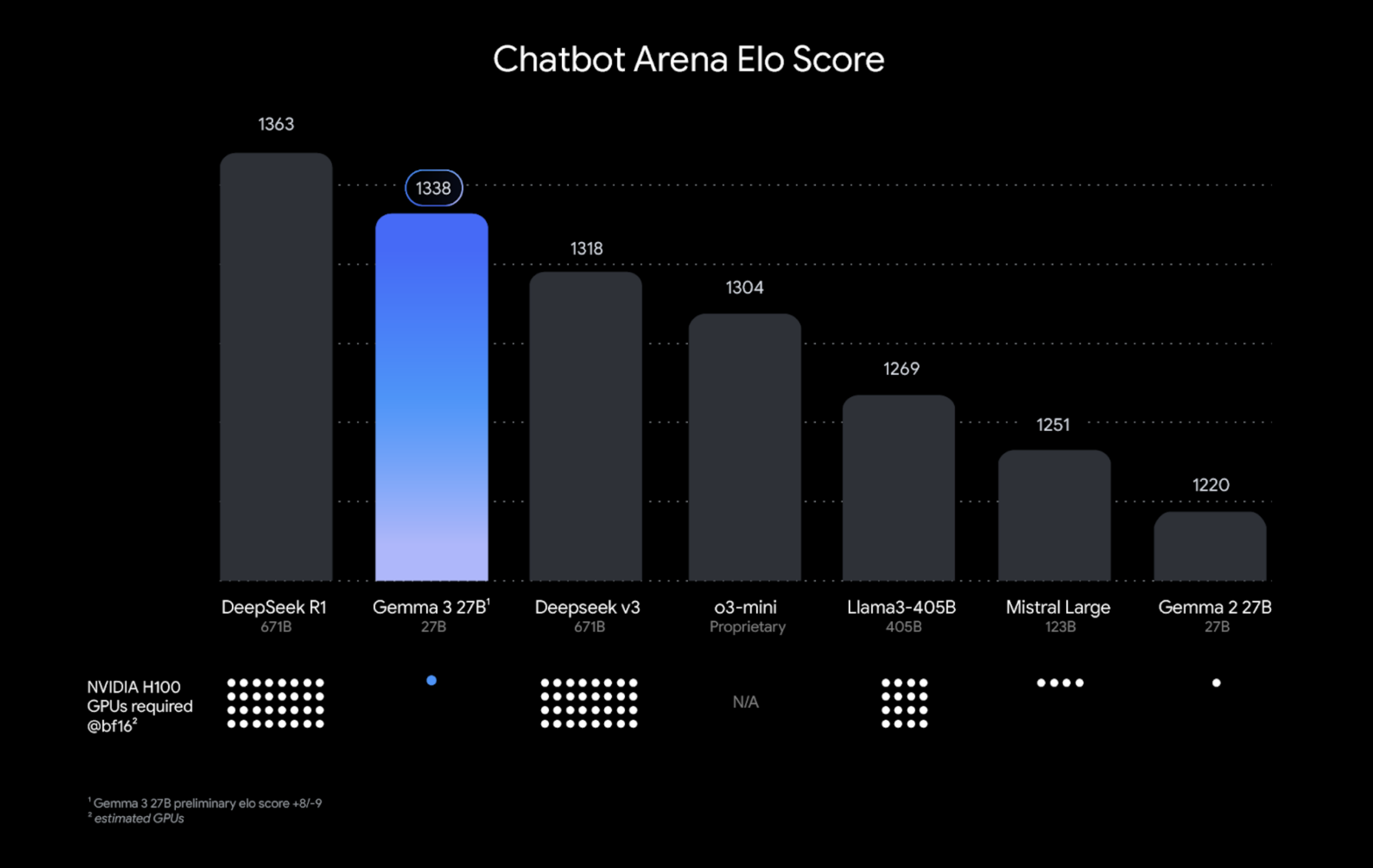
如下图所示,在性能方面,Gemma 3系列表现出色,在问答、摘要和推理等任务上能够与主流大模型,如o3-mini,DeepSeek R1/V3相媲美,同时其紧凑的设计使其能够在资源有限的设备上部署,如Gemma 3 27B 只需要单个NVIDIA H100即可运行。
量化感知训练的突破
不过,传统的大型语言模型通常使用BFloat16(BF16)格式进行推理,这仍然需要大量的GPU内存。例如,Gemma 3 27B模型在BF16格式下需要54GB的VRAM,这远超RTX 3090,RTX 4060等主流消费级GPU的内存限制。
为了解决这个问题,谷歌为Gemma 3引入了量化感知训练(Quantization-Aware Training,QAT)技术。与传统的训练后量化(Post-Training Quantization,PTQ)不同,QAT在训练过程中就模拟低精度操作,使模型能够适应量化带来的精度损失。
具体来说,谷歌在约5,000步的训练中应用了QAT,使用非量化检查点的概率作为目标。这种方法使得量化到Q4_0格式时的困惑度下降减少了54%(使用llama.cpp困惑度评估)。
内存需求的显著降低
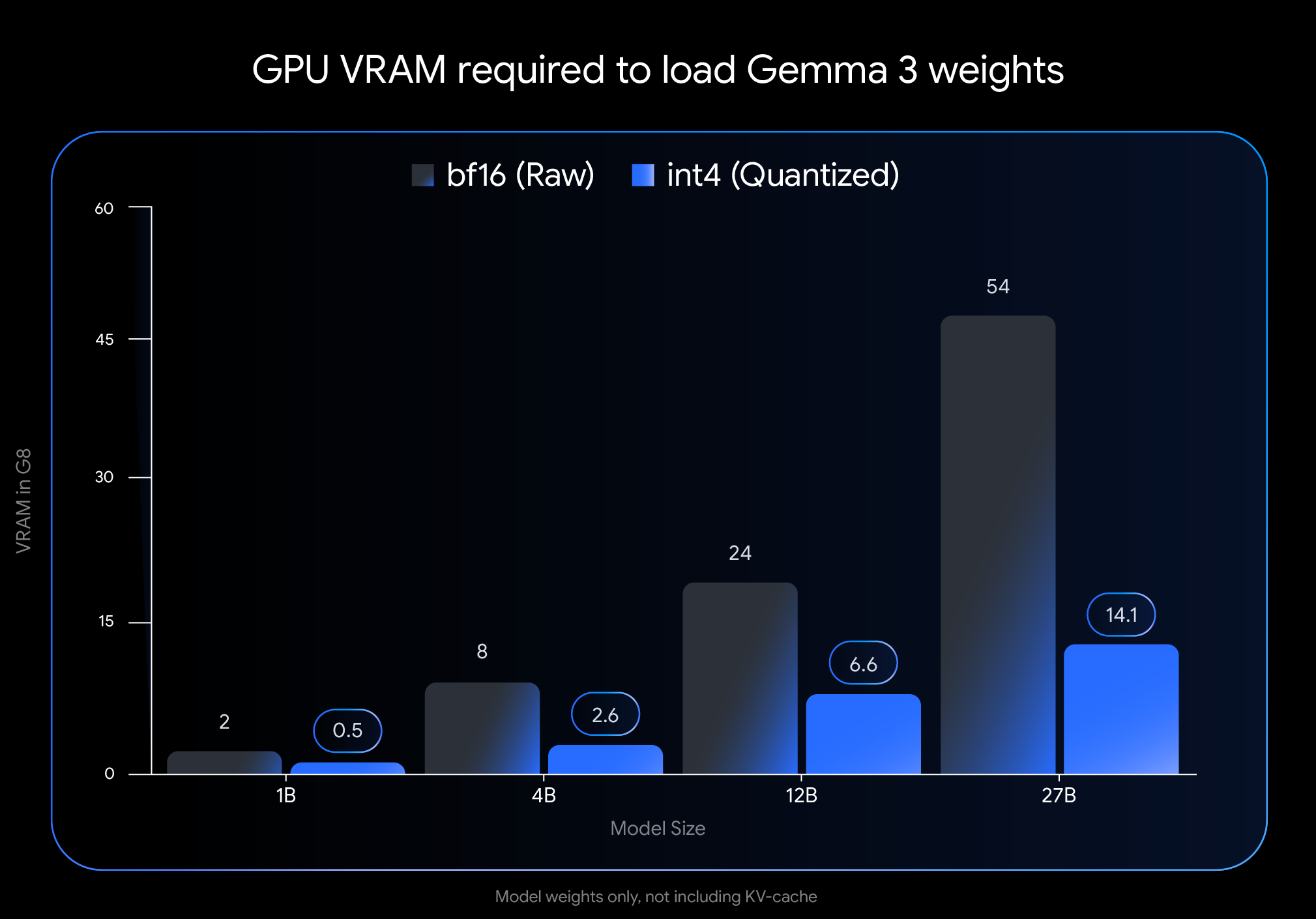
如上图所示,量化到int4精度后,Gemma 3模型的内存需求大幅降低:
- Gemma 3 27B:从54GB(BF16)降至仅14.1GB(int4)
- Gemma 3 12B:从24GB(BF16)降至仅6.6GB(int4)
- Gemma 3 4B:从8GB(BF16)降至仅2.6GB(int4)
- Gemma 3 1B:从2GB(BF16)降至仅0.5GB(int4)
这意味着Gemma 3 12B的int4版本有可能在仅有8GB VRAM的笔记本GPU RTX 4060上运行,而4B和1B版本则有更多余量,可以处理更长的上下文或并行任务。
特别值得注意的是,通过QAT技术,Gemma 3模型在量化后能够保持接近原始模型的性能。在多项基准测试中,Gemma 3均表现出与非量化版本相近的能力,同时内存需求却减少了近4倍。
在RTX 4060上实测Gemma 3 12B-IT-QAT模型
考虑到我手头的笔记本GPU RTX 4060只有8GB VRAM,我选择Gemma 3 12B的int4版本进行测试,希望能最大程度发挥出RTX 4060的性能。我尝试了Ollama和LM Studio这两种主流的本地大语言模型运行框架,下面是部署的详细步骤和测试结果。
通过Ollama部署本地模型
Ollama是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型而设计。它具有以下特点:
- 简化部署:简化了在Docker容器中部署大型语言模型的过程
- 模型管理:支持多种流行的大型语言模型,并提供丰富的命令行工具
- 轻量级与可扩展:保持较小的资源占用,同时具备良好的可扩展性
- API支持:提供简洁的API接口,兼容OpenAI的API标准
在RTX 4060(8GB VRAM)上部署Gemma 3 12B-IT-QAT模型的步骤如下:
- 从Ollama官网下载并安装Ollama
- 打开终端,运行以下命令下载并运行模型:
ollama run gemma3:12b-it-qat - 如下图所示,下载完成后,模型将在本地运行,可以直接在终端中与模型交互
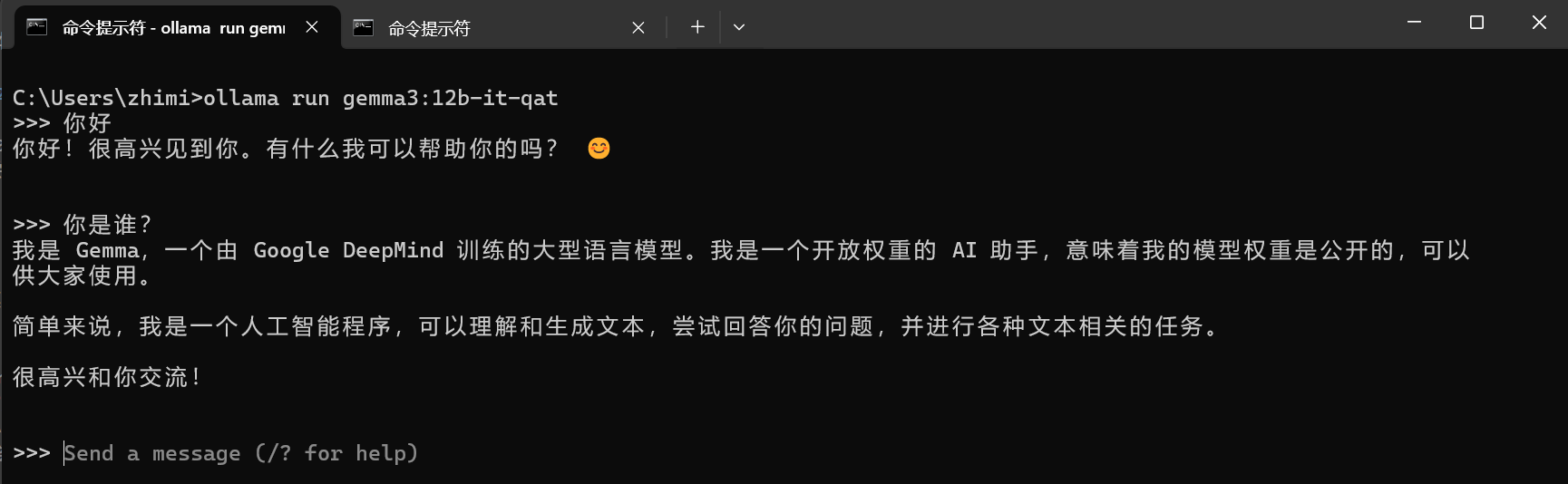
不过,模型整个下载下来,大小是8.9GB,超过了8GB的显卡内存限制,所以Ollama只能使用CPU和GPU混合运行。

我实际测试了一下,Gemma 3 12B-IT-QAT模型运行还算流畅,证明了即使在入门级的游戏显卡上,也能体验高质量的AI模型。
使用LM Studio提升用户体验
虽然Ollama提供了命令行界面,但对于非技术用户来说可能不够友好。LM Studio提供了一个图形用户界面,使得使用Gemma 3 QAT模型变得更加简单:
- 从LM Studio官网下载并安装LM Studio
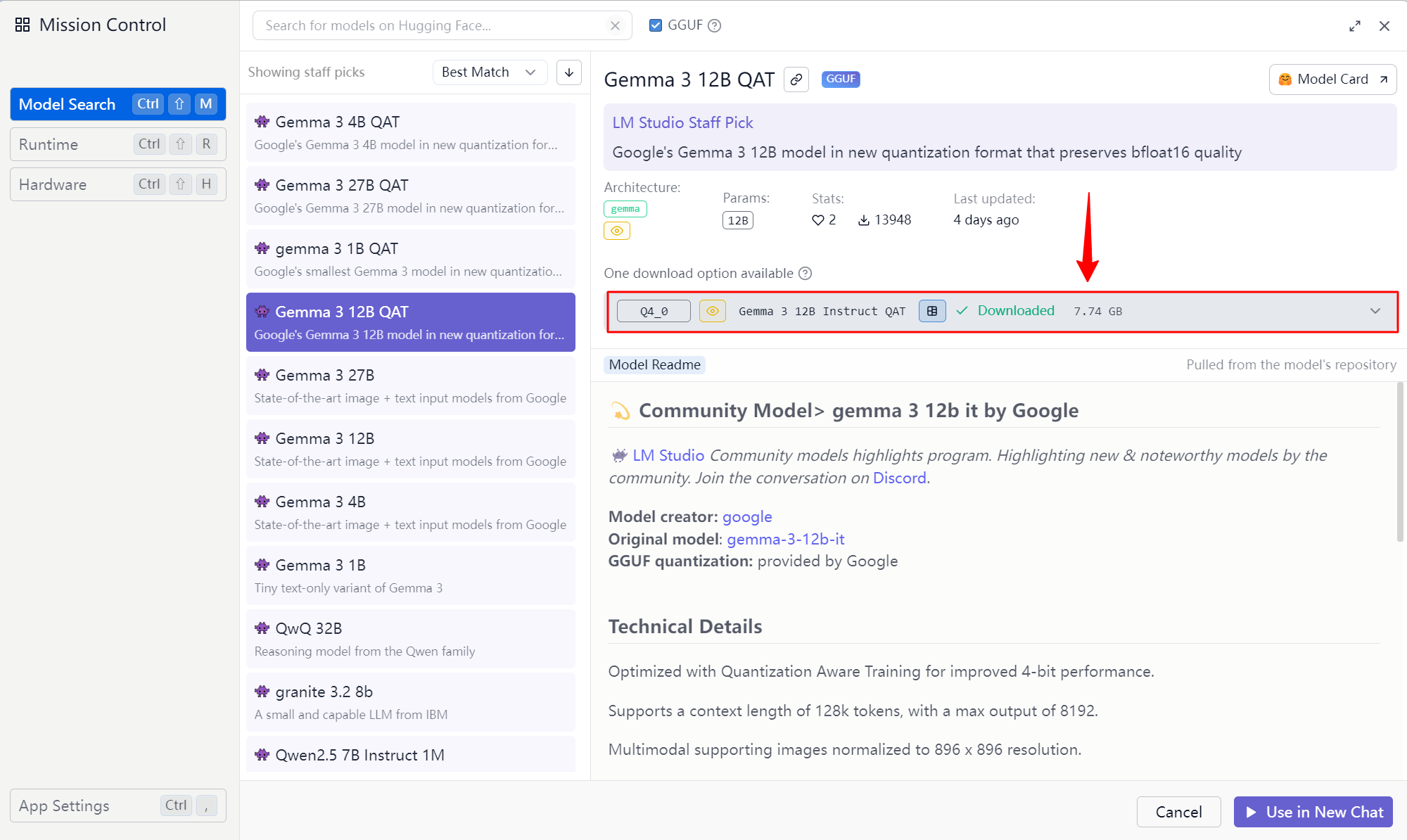
- 如下图所示,在模型库中搜索并下载"gemma 3 12B QAT"
- 下载完成后,可以通过用户友好的界面与模型交互
可以看到LM Studio的12B版本只有7.74GB,具备了完全放进RTX 4060的条件,这个非常不错。
如下图所示,LM Studio还提供图形界面的聊天界面,可以与模型进行交互。
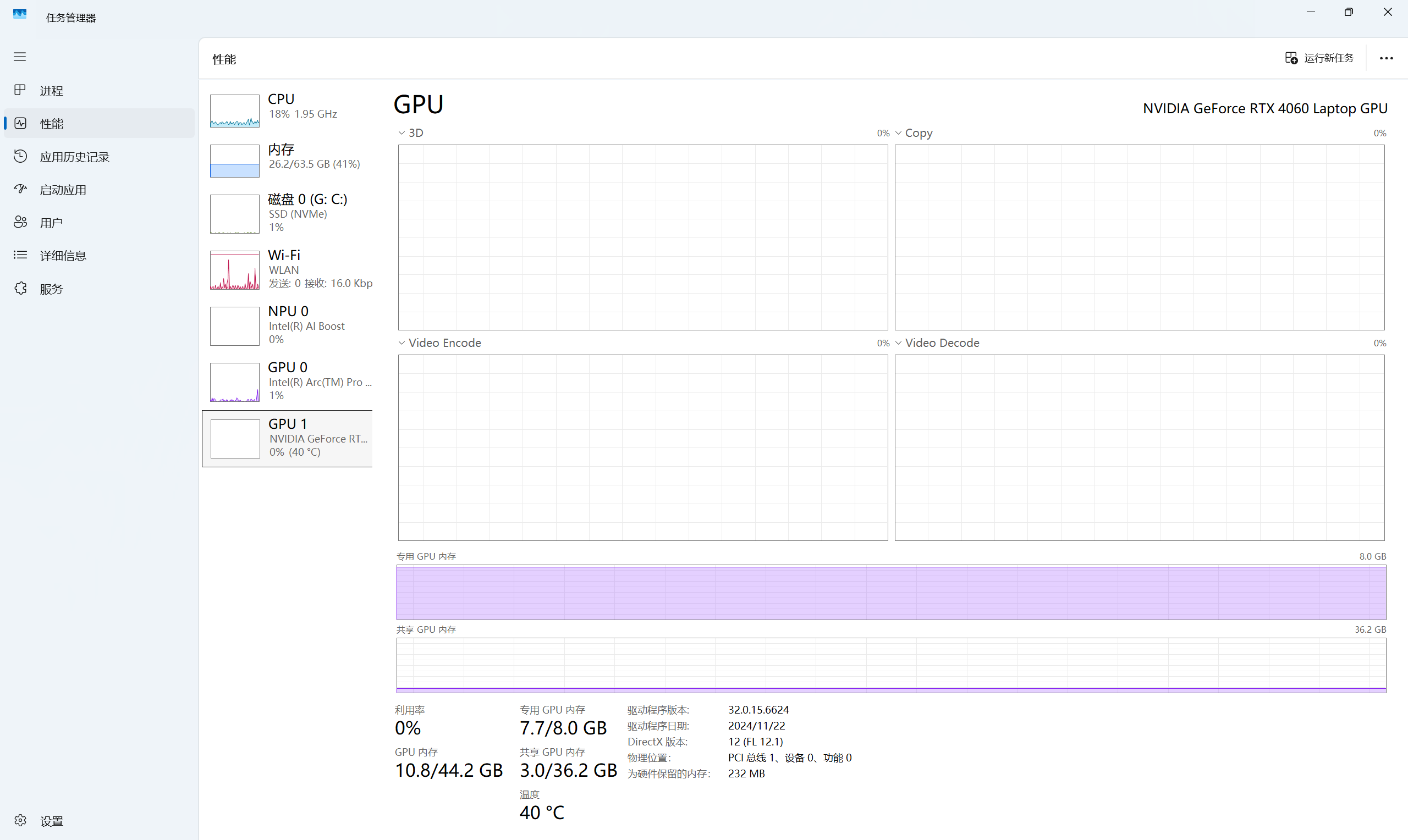
我实际查看了一下系统GPU的使用情况,整个模型都载入到显卡的VRAM中,没有使用CPU,符合我的需求。
由于是完全在RTX 4060上运行Gemma 3 12B-IT-QAT时,聊天体验相比使用Ollama的版本更加流畅一些。
构建知识库增强型AI系统
AnythingLLM与RAG架构
我们现在有了强大的本地运行的大语言模型,就可以将模型与知识库结合,构建完全本地部署的知识库增强型AI系统。这就是检索增强生成(Retrieval-Augmented Generation,RAG)架构的作用。
RAG架构由三个主要组件组成:
- 大语言模型(LLM):如Gemma 3 12B-IT-QAT
- 嵌入模型(Embedding):将文本转换为向量表示
- 向量数据库(Vector Database):存储和检索嵌入向量
AnythingLLM是一款基于RAG架构的本地知识库工具,能够将文档、网页等数据源与本地运行的大语言模型相结合,构建个性化的知识库问答系统。
在本地部署AnythingLLM与Gemma 3的集成
AnythingLLM提供一站式安装和配置本地知识库,简单的步骤如下:
- 从AnythingLLM官网:https://anythingllm.com/desktop, 下载并安装AnythingLLM桌面版
- 在设置中选择Ollama/LM Studio作为LLM提供商,并选择gemma3:12b-it-qat作为模型
- 选择嵌入模型和向量数据库(可以使用AnythingLLM提供的默认选项)
- 创建工作区并上传文档(支持PDF、Word、Markdown等多种格式)
- 开始与基于知识库的AI系统交互
如下图所示,因为LM Studio的12B版本只有7.74GB,完全可以放进RTX 4060的8GB VRAM中,所以在AnythingLLM中我设置使用LM Studio作为LLM提供商。
在RTX 4060上实测AnythingLLM与Gemma 3 12B-IT-QAT的集成表现良好。系统能够在不到8GB VRAM的限制下,同时运行大语言模型和嵌入模型,准确理解并回答基于上传文档的问题,同时保持对话的连贯性和上下文理解能力,如下图所示,输出速度大概在5 tok/s左右,基本可以接受。
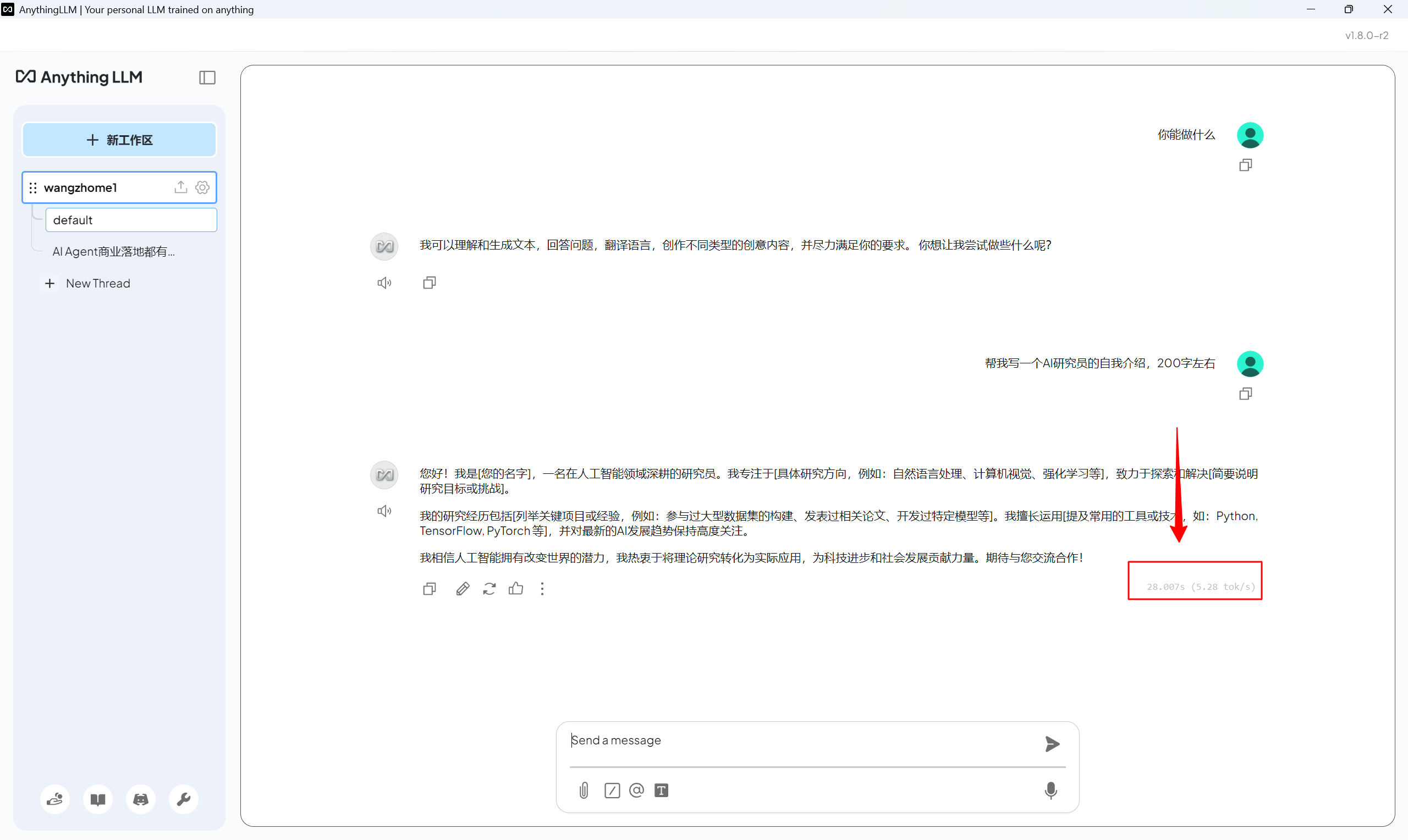
特别值得一提的是,由于所有处理都在本地完成,用户不必担心数据隐私问题,这对于处理敏感信息的场景尤为重要。此外,RTX 4060作为一款主流的消费级GPU,价格相对亲民,使得构建本地AI系统的门槛大大降低。
实际应用场景与优势
本地部署的优势
将Gemma 3 QAT模型部署在RTX 4060等消费级GPU上具有以下优势:
- 硬件门槛低:无需高端专业GPU,主流游戏显卡即可运行
- 免费使用:一次性投入硬件后,可以无限制使用模型,无需支付API费用
- 数据隐私:所有数据处理都在本地完成,不会上传到云端
- 无内容限制:本地模型不受内容审查的限制,输出更加自由
- 离线工作:不依赖网络连接,可以在任何环境下使用
- 定制灵活:可以根据特定需求对模型进行微调或与其他工具集成
适用场景
在RTX 4060上运行的Gemma 3 12B-IT-QAT模型特别适合以下场景:
- 个人知识管理:结合AnythingLLM构建个人知识库,辅助学习和研究
- 开发测试:开发者可以在本地快速测试AI功能,无需依赖云服务
- 敏感数据分析:处理不适合上传到云端的敏感信息
- 创意写作与内容创作:辅助写作、创意构思和内容生成
- 教育与研究:学术机构可以使用这些模型进行研究和教学,无需高昂的计算资源
结论
Gemma 3 QAT模型代表了AI民主化的重要一步,通过量化感知训练技术,谷歌成功地将高性能AI模型带到了普通消费级硬件上。实测证明,即使是仅有8GB VRAM的RTX 4060,也能流畅运行Gemma 3这样的大型模型,这不仅降低了进入门槛,也为开发者和研究人员提供了更多可能性。
特别是Gemma 3 12B-IT-QAT模型,在保持高质量输出的同时,显著降低了内存需求,使其能够在主流游戏GPU上流畅运行。结合Ollama、LM Studio和AnythingLLM等工具,用户可以构建功能强大的本地AI系统,实现从简单聊天到复杂知识库查询的各种应用。
随着量化技术的进一步发展,我们可以期待未来会有更多高性能模型能够在普通硬件上运行,使AI技术真正走入每个人的日常生活和工作中。RTX 4060这样的消费级GPU已经能够支持相当强大的AI能力,这意味着AI技术的门槛正在迅速降低,未来将有更多人能够参与到AI应用的开发和使用中来。


















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











