






引言
DeepSeek R1作为新一代中文大语言模型(LLM)的佼佼者,凭借其卓越的性能、开源特性和强大的多场景应用能力,已经成为AI应用领域的首选解决方案。从企业级应用到个人AI助手开发,从自然语言处理到代码生成,DeepSeek R1都展现出了令人瞩目的实力。
由于众所周知的原因,很多用户在访问DeepSeek官方服务时可能遇到不稳定的情况。为此,本文将为大家详细介绍三种稳定可靠的DeepSeek R1接入方案,包括:
- 秘塔AI搜索引擎集成方案
- OpenRouter开放平台对接方案
- 硅基流动国内服务平台方案
通过这三种方案的详细解析,帮助用户实现DeepSeek R1的最佳使用体验。无论您是技术开发者还是普通用户,都能找到最适合自己的使用方式。
方案一:秘塔AI搜索引擎 - DeepSeek R1智能搜索集成方案
秘塔搜索作为领先的国产AI搜索引擎,全面接入了DeepSeek R1模型,为用户提供智能搜索和深度问答服务。通过秘塔搜索的用户界面,您可以轻松体验DeepSeek R1的强大功能。
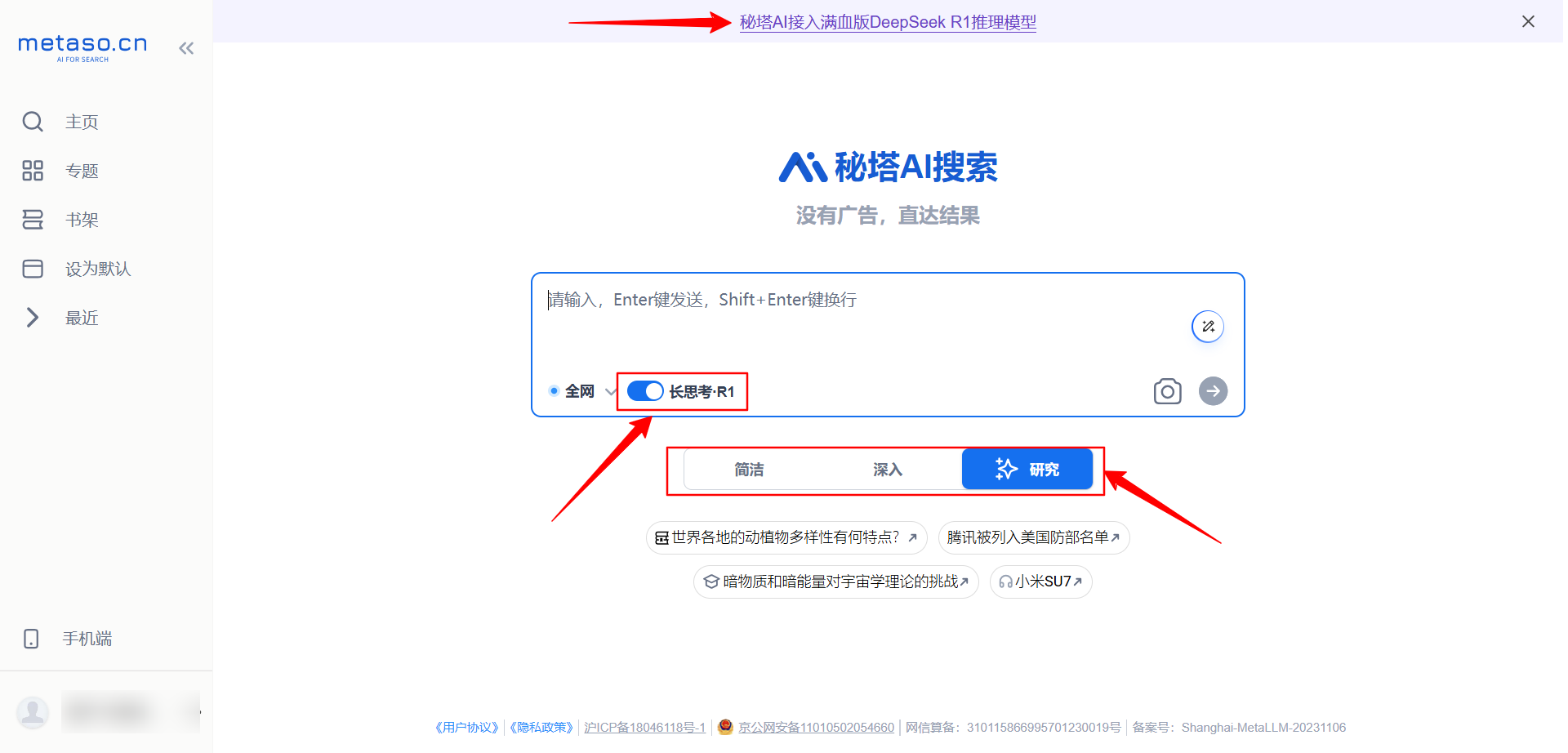
启用"长思考"模式
在秘塔搜索的界面中,提供了名为"长思考-R1"的高级功能选项。启用该模式后,DeepSeek R1将发挥其深度推理能力,提供更精准的搜索结果。特点包括:
- 深度上下文理解和分析
- 自动生成详细的解决方案
- 多维度的问题解答
此外,用户可以根据需求选择简洁、深入和研究三个层次,获取不同深度的搜索结果。研究级别的输出尤其适合专业用户和学术研究。
方案二:OpenRouter平台 - DeepSeek R1全球分布式接入方案
OpenRouter作为全球领先的AI模型路由平台,提供了完整的DeepSeek R1接入解决方案。通过其分布式架构,用户可以稳定访问DeepSeek R1的全部功能。
1. 注册并获取API密钥
用户需要在OpenRouter官网(https://openrouter.ai/) 完成注册并申请API密钥。这是调用模型服务的必要凭证。
2. ChatRoom智能对话环境
OpenRouter提供了专业的ChatRoom环境,支持直接与DeepSeek R1模型进行对话。
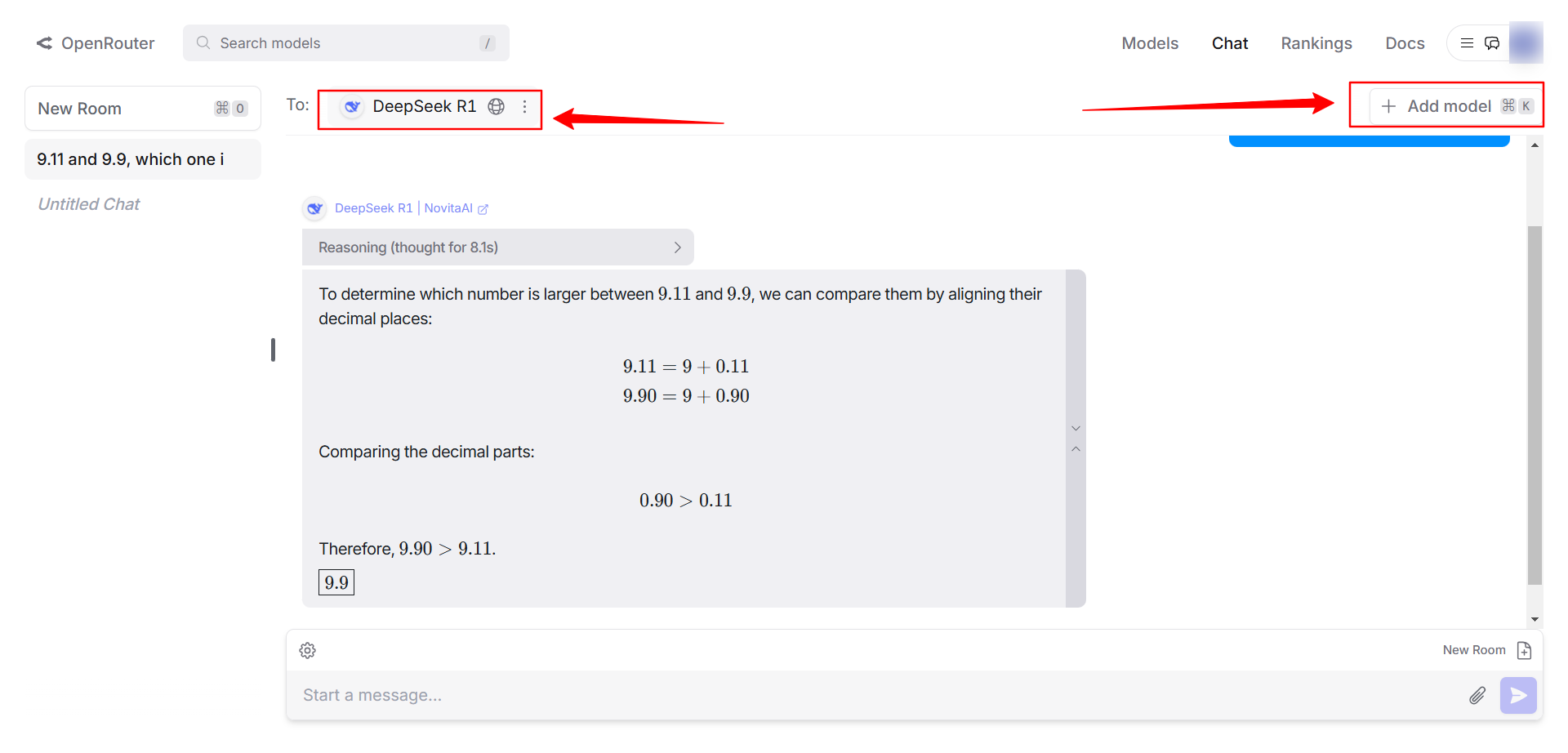
用户可以通过简单的界面操作,体验DeepSeek R1的自然语言处理能力。平台支持参数调整和网络搜索功能,堪称社区版DeepSeek R1的完整替代方案。
3. 专业API配置指南
对于开发者用户,OpenRouter提供了标准化的API配置方案:
{
"model": "deepseek/deepseek-r1",
"base_url": "https://openrouter.ai/api/v1",
"parameters": {
"max_tokens": 1000,
"temperature": 0.7
}
}
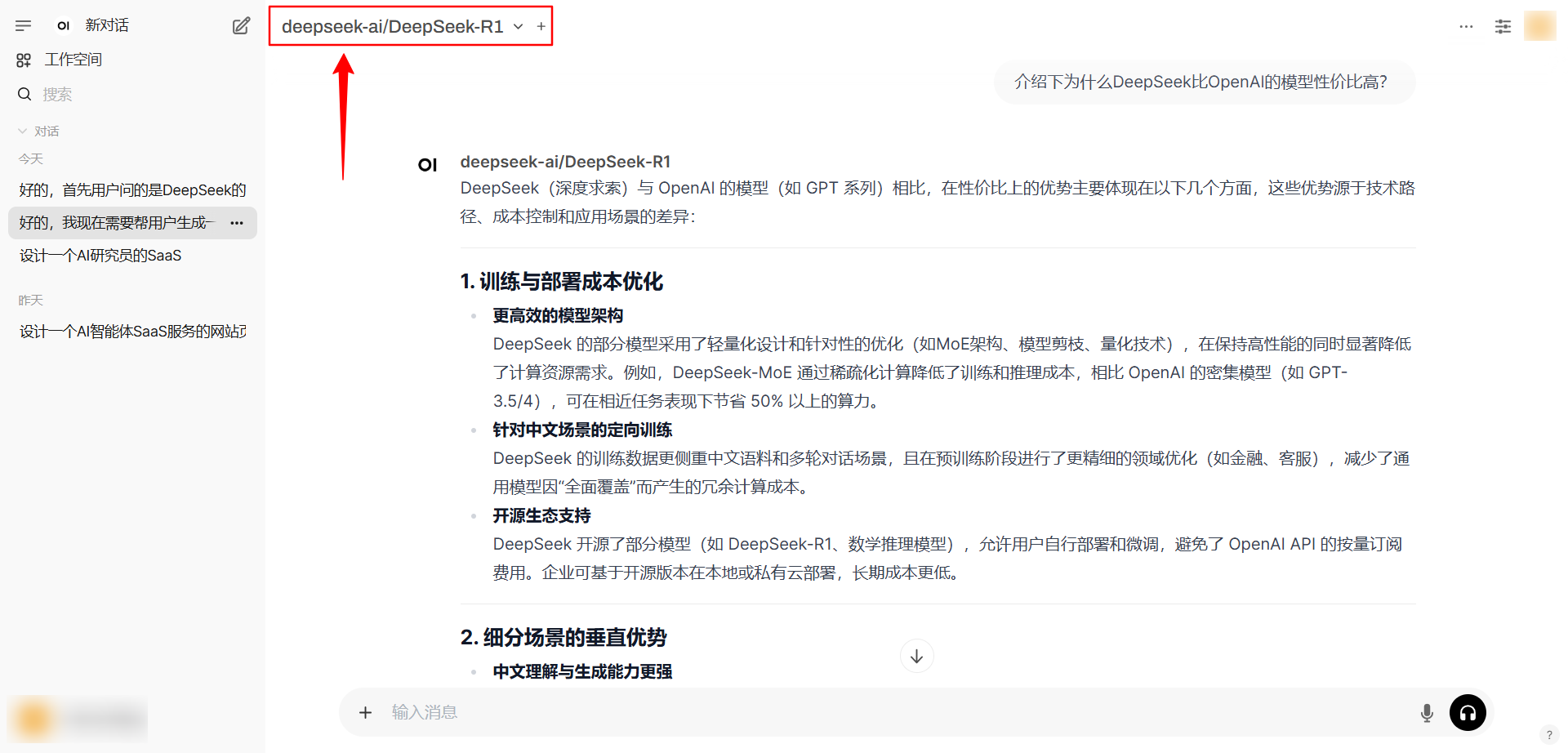
此配置完全兼容OpenAI API标准,可无缝对接各类开发平台。下图展示了在OpenWebUI中的具体应用:
4. 多供应商生态系统
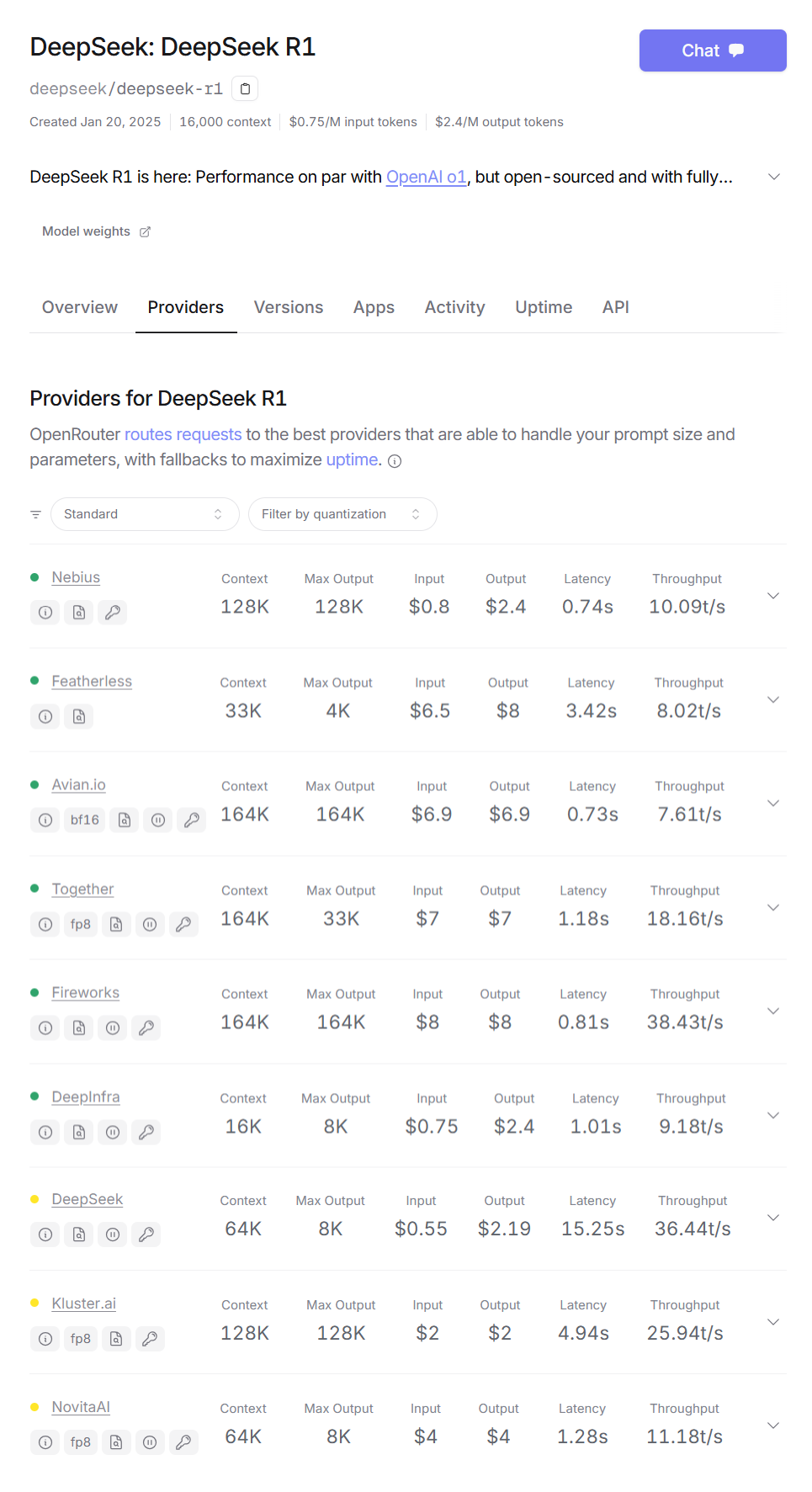
OpenRouter平台最大的优势在于聚合了全球多家DeepSeek R1服务提供商。目前平台已收录8家官方认证的供应商,为用户提供了丰富的选择。
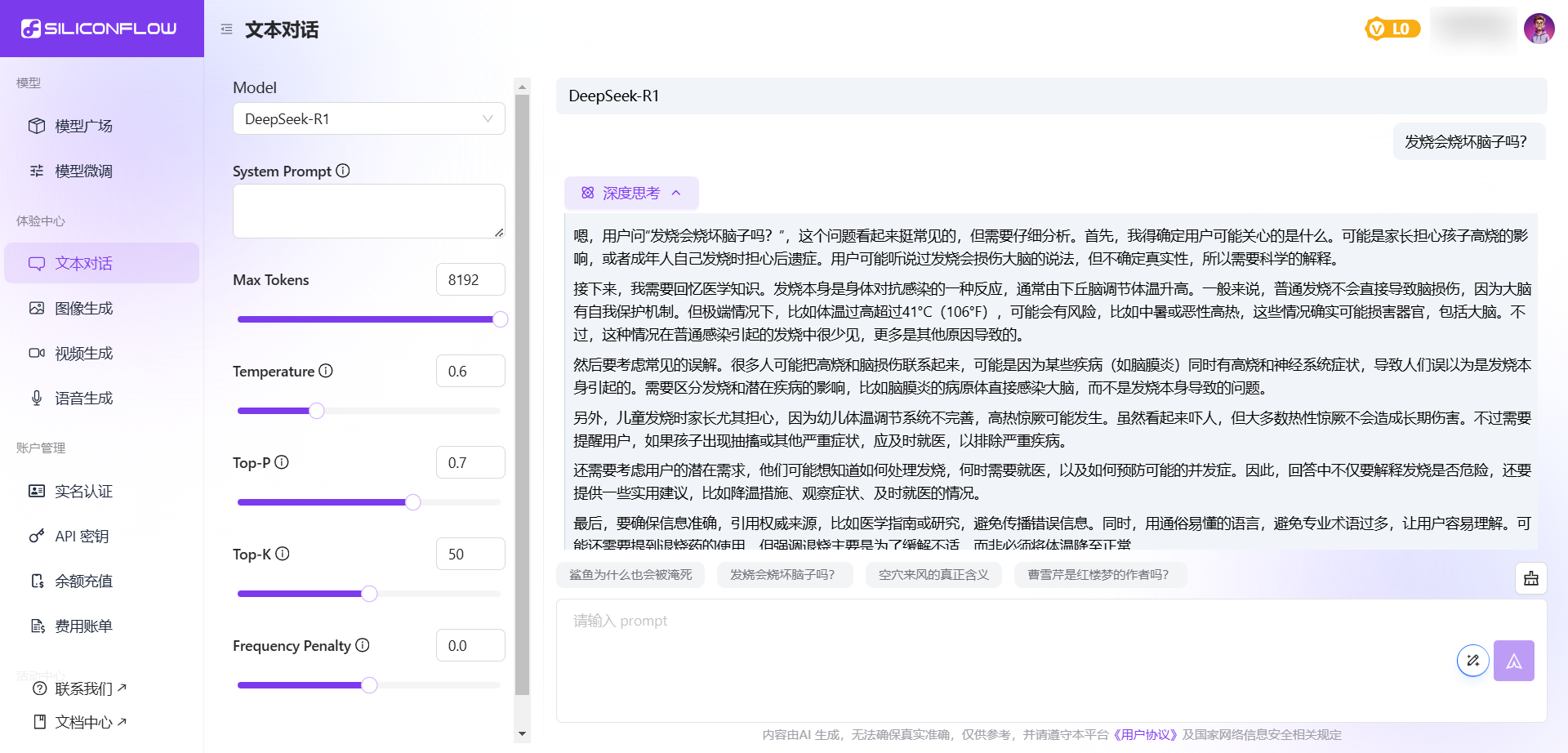
方案三:硅基流动平台 - DeepSeek R1国内稳定服务方案
作为国内领先的AI服务平台,硅基流动携手华为云推出了本土化的DeepSeek R1服务方案,为国内用户提供稳定可靠的使用环境。
1. 零门槛快速接入
硅基流动平台提供了完全零部署的使用环境,用户仅需注册即可立即开始使用DeepSeek R1的服务。
2. 专业API开发接口
平台提供了标准化的API调用接口,支持多种开发语言。以下是Python示例代码:
import requests
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "deepseek-ai/DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "中国大模型行业2025年将会迎来哪些机遇和挑战?"
}
],
"stream": False,
"max_tokens": 512,
"stop": ["null"],
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {"type": "text"},
"tools": [
{
"type": "function",
"function": {
"description": "<string>",
"name": "<string>",
"parameters": {},
"strict": False
}
}
]
}
headers = {
"Authorization": "Bearer <token>",
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)
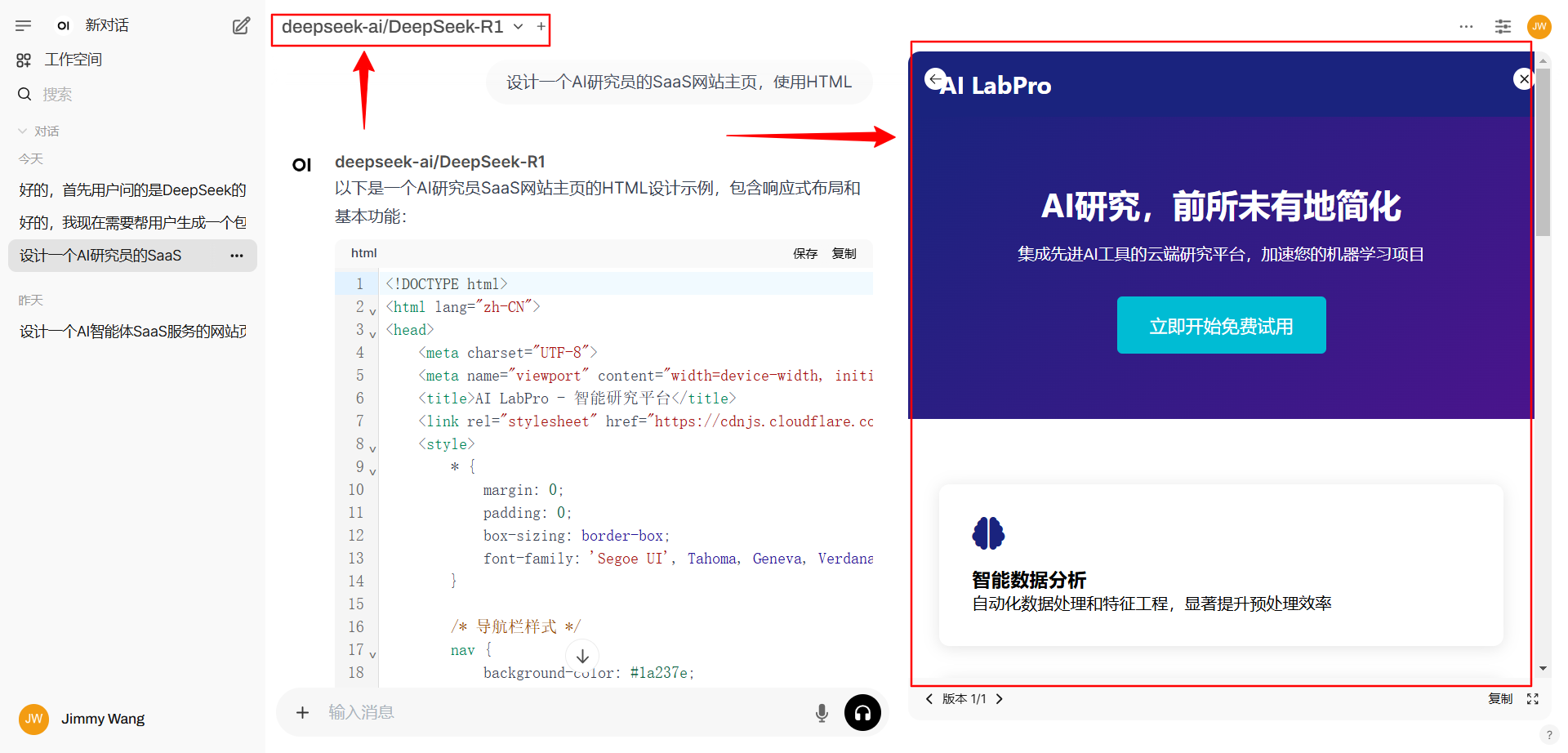
3. 丰富的第三方生态
硅基流动平台支持与主流开发框架的无缝对接,下图展示了在OpenWebUI中的高级应用案例:
DeepSeek R1方案选择指南
方案对比分析
| 特性 | 秘塔搜索 | OpenRouter | 硅基流动 |
|---|---|---|---|
| 使用门槛 | 极低 | 中等 | 低 |
| 功能完整度 | 基础功能 | 完整功能 | 高级功能 |
| 适用场景 | 搜索问答 | 全球开发 | 国内应用 |
| API支持 | 有限 | 完整 | 完整 |
| 部署难度 | 无需部署 | 简单配置 | 即开即用 |
| 价格模式 | 免费使用 | 按量计费 | 按量计费 |
最佳实践建议
-
个人用户选择建议
- 日常使用:推荐秘塔搜索
- 开发学习:建议OpenRouter
- 稳定性需求:首选硅基流动
-
企业用户选择建议
- 国内业务:优先硅基流动
- 全球业务:考虑OpenRouter
- 特定场景:可多平台结合
未来发展展望
-
技术演进趋势
- 模型性能持续提升
- 应用场景不断扩展
- 生态系统日益完善
-
平台发展方向
- 功能整合更加深入
- 服务体验不断优化
- 产品形态更加丰富
DeepSeek R1作为新一代中文大语言模型的代表作,正在推动AI应用进入一个新的发展阶段。通过本文介绍的三种接入方案,相信每位用户都能找到最适合自己的使用方式,充分发挥DeepSeek R1的强大潜力。
欢迎在评论区分享您的使用经验,共同探讨DeepSeek R1的创新应用。


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











