








论文地址:https://arxiv.org/abs/2005.12872
代码地址:https://github.com/facebookresearch/detr
在看完Transformer之后,将会开始看视觉类的Transformer应用。本篇论文出自ECCV20,是关于目标检测的论文。DETR,即Detection Transformer的缩写,还记得在Transformer中,作者曾提到过该模型可能还会再视觉、视频等领域可以应用,现在看来不得不佩服当时作者的直觉。这篇论文在2020年提出后就引起了很大的反响,很多人将本篇论文中的工作评为检测里面的里程碑,还有很多人说他应当是当年eccv的最佳论文。
一、摘要和简介
摘要第一句话,作者就阐明了我们使用的是一种新的思想,不同于以往的目标检测算法,作者将目标检测看做成集合预测的问题。由于思想的转变,该框架实际上真正做到了端到端的预测,在当前流行的目标检测算法里面,不管是one-stage的还是two-stage的算法,难免都要有其他的处理操作,比如nms的后处理,anchor base的网络等,他们都没有做到真正的端到端(在这里,我认为端到端其实可以理解为–给定一张输入的图片,模型能够直接输出完整的结果,而不再需要其他的后续操作)。省掉了那些操作后,DETR极大的简化了目标检测的流程。在DETR实现中,有两个主要的创新点:提出了一个新的目标函数,使得预测成为二分图匹配的问题;使用了Transformer的encoder-decoder的结构(并不是原始结构的Transformer)。
简单性是DETR的最大优势,由于省掉了anchor和nms操作,其框架十分的简单,虽然精度上不占优势,但是在DETR后面加上一个专用的分割头后,DETR就可以用于全景分割,并且表现出了比较好的性能。同时,DETR还有一个特点就是可以并行的去计算。
在Introduction的第一段中,作者先是介绍了当前比较流行的目标检测器,比如基于候选区域的rcnn系列,单阶段检测的yolo系列算法,这些算法的性能很大程度上受限于后处理的操作,并且很依赖人的先验知识。同时,他们没有直接将目标检测看作是集合预测,而是转而使用了分类或者回归的方法来解决这一问题。
DETR的整体流程图如下图所示:
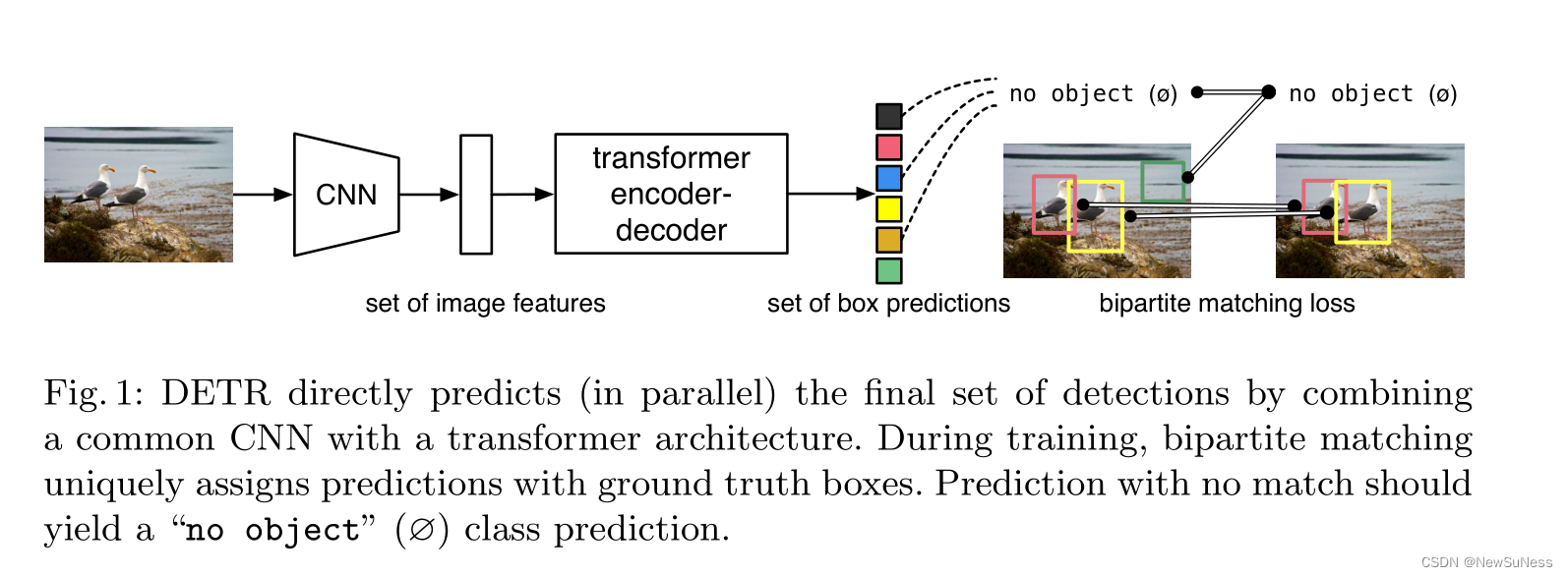
从上图可以看出,把一张图片输入进模型,首先会经过一个卷积网络来生成一个特征图(这一点和fastrrcnn相同),也就是初步提取这张图片的特征,然后生成的特征图会送入encoder中进行编码,在经过decoder输出预测框(这里注意,DETR由于没有anchor也没有nms,其能生成的检测框数量是固定的,原文中称为object query,能够与ground truth的框会被保留,剩余的会作为背景框处理掉)。这就是整个算法的大致流程,具体的细节会在后面进行补充。
在coco数据集上,DETR达到了与Faster-Rcnn基线网络得到了同样的精度,但是DETR在大物体的检测效果上会更好,在小物体的检测效果上比较差,这是他的缺点之一,但是作者提到了任何的模型都要经过数次的迭代和改进,才能达到比较好的性能,由于DETR是初代的算法框架,因此可以改进的地方还是非常多的。
二、相关工作
作者在这里阐述了与自己论文相关的技术,分为三个部分:基于二分图匹配的集合预测、Transformer架构的编码-解码架构、并行解码以及目标检测的方法。
关于这部分的内容大多都是知识性的背景介绍,这里就不再做相关的叙述。
三、DETR模型算法
首先放上整个模型的架构图:
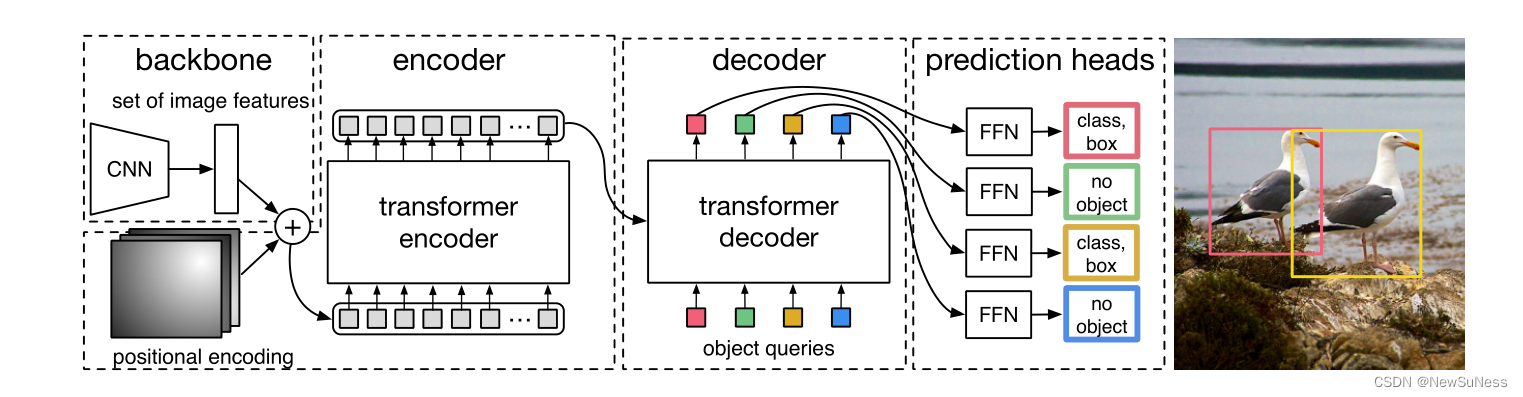
作者在这里说了本节当中,主要介绍两个部分:关于预测值和真实标签的集合预测损失;第二个就是本文DETR的整体结构了。
3.1 目标检测集合预测损失
对于DETR的模型来说,最后网络总是会输出一个固定的输出N(object query所限定),就经验来说,一百个输出框已经可以覆盖一张图片中的所有物体了(大多数图片都不会有特别多的物体)。如何将预测框与ground truth进行匹配,并计算最终的loss,作者在这里将其转换成为了二分图匹配的问题,该损失函数的公式如下:
σ ~ = a r g m i n σ ∈ N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) \widetilde{\sigma} = argmin_{\sigma\in N}\sum_{i}^{N}L_{match}(y_i, \widehat{y}_{\sigma(i)}) σ
=argminσ∈Ni∑NL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









