







本实验完整代码在
kaggle: LeNet with pytorch
所使用数据集:
MNIST Original | Kaggle
一. 加载并封装数据集
解析mat格式数据
import numpy as np
from scipy.io import loadmat #加载mat格式数据
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
mnist = loadmat("/kaggle/input/mnist-original/mnist-original.mat")
mnist
得到的mnist数据集结构如下:

取出data和label
label很好取:
mnistLabel = mnist["label"][0]
mnistLabel
data需要稍微注意一下:
查看data的形状
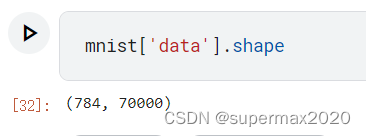
70000张图片,每张图片是28×28.
为方便使用下标访问,需要取一下转置.(个人猜测是因为matlab中数组的排列是先按列后按行,和python中不同,所以mat格式的数据存储在python中转换一下. )
所以data的取法应当是:
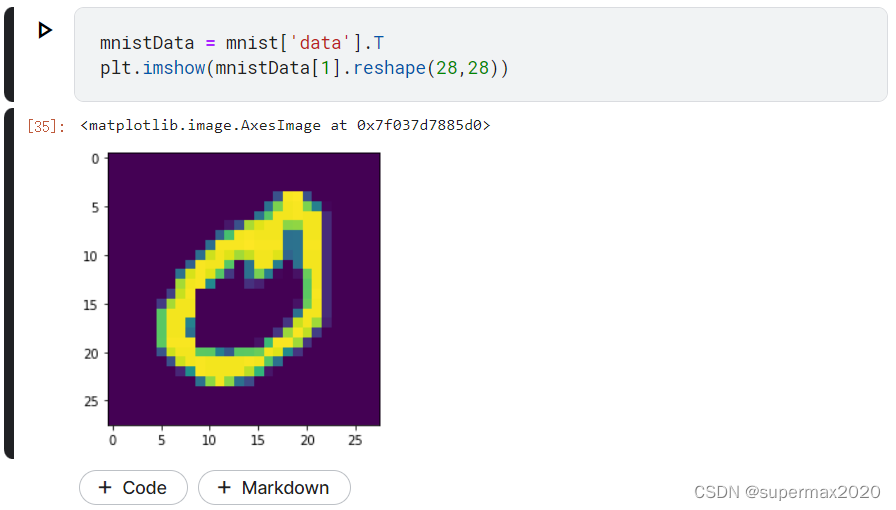
mnistData = mnist['data'].T
plt.imshow(mnistData[1].reshape(28,28))
效果如图:
封装成自定义DataSet,并划分训练集与测试集
class MinistDataSet(Dataset):
def __init__(self,data,label,dtype):
if dtype=='float':
self.data = data.astype(np.float32)
self.label = label.astype(np.float32)
else:
self.data = data
self.label = label
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.label)
mnistDataSet = MinistDataSet(mnistData,mnistLabel)
trainDataSet,testDataSet = t.utils.data.random_split(mnistDataSet,[65000,5000])
trainDataLoader = DataLoader(trainDataSet,batch_size=100)
testDataLoader = DataLoader(testDataSet,batch_size=5000)
# 这里的testData,testLabel作为测试集
itrTest = iter(testDataLoader)
testData,testLabel = itrTest.next()
定义网络模型
使用LeNet5实现
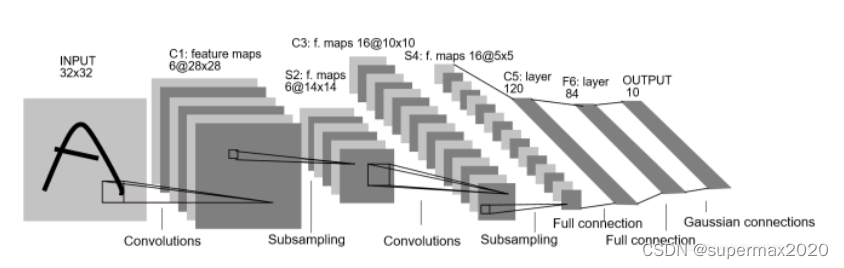
不过LeNet5所使用的的数据集图片是32×32, 本数据集的大小是28×28, 所以第一层需要使用padding
输出是10个数字,哪个最大哪个就是预测结果.
比如[1,1,1,1,9,1,1,1,1,1], 下标为4的数字最大,则预测结果为4
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5,self).__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,\
kernel_size=5,padding=2)# 6x28x28
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)#6x14x14
self.conv2 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5)#16x10x10
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)#16x5x5
self.fc1 = nn.Linear(in_features=400,out_features=120)
self.fc2 = nn.Linear(in_features=120,out_features=84)
self.fc3 = nn.Linear(in_features=84,out_features=10)
def forward(self,x):
x = x.view(-1,1,28,28) #100x1x28x28
x = F.relu(self.conv1(x))#100x6x28x28
x = self.pool1(x)#100x6x14x14
x = F.relu(self.conv2(x))#100x16x5x5
x = self.pool2(x)#100x8x5x5
x = x.view(-1,400)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
需要注意的是维度问题,forward函数使用了两个view
nn.Conv2d的输入必须是四维Tensor,它的维度是(B,C,H,W)
B: 批大小
C:通道数
H:图像高度
W:图像宽度
数据集输入的是(B,784)的二维向量
x.view(-1,1,28,28)将其转换为(B,1,28,28)的四维向量
nn.Linear的输入必须是2维Tensor,它的维度是(B,L)
B是批大小,L是单个样本的激活值数量
所以第二个view(-1,400)把Tensor的形状变为(B,400)
进行训练
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
print(device)
# 创建模型
model = LeNet5()
model.to(device)
# 损失函数采用交叉熵误差,优化器使用Adam
criterion = nn.CrossEntropyLoss()
optimizer = t.optim.Adam(model.parameters(),lr = 0.001)
save_path = './/Lenet.pth'
for epoch in range(100):
model.train()
for step, (data,label) in enumerate(trainDataLoader, start=0):
optimizer.zero_grad()# 优化器每次使用之后必须清零梯度,否则梯度会累加
y = model(data.to(device))
loss = criterion(y,label.to(device).long())# 交叉熵误差的第二个参数必须是long类型
loss.backward()
optimizer.step()
if(step%100==99):
with t.no_grad():
outputs = model(testData.to(device))
predictY = t.max(outputs, dim=1)[1]
accuracy = (predictY == testLabel.to(device)).sum().item() / testLabel.size(0)
testLoss = criterion(outputs,testLabel.to(device).long())
print("train loss:"+str(loss.item()))
print("test loss:"+str(testLoss.item()))
print("accuracy:"+str(accuracy))
t.save(model.state_dict(), save_path)















 6700
6700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









