







CVPR 2021
论文链接:https://arxiv.org/abs/2103.05950
个人理解
论文思路:作者认为,低AP源于混淆分类带来的误分类,可以通过输入图像与支持样例的特征进行对比的方法,来提高类紧凑和类间差。
提出问题:少样本下的误分类问题
方法:当检测到少样本新数据时,在感兴趣区域头部增加一个对比分支,对比测量结果和提议目标之间的相似性。
实验:在旧类上分类不一定好,但在新类加入后性能好
结果:成本低,适用度高
简介
深度学习需要大量的标记数据,而现实生活中存在很多少样本的情况。在少样本训练中,存在误分类的问题。在深层网络中,少样本会有严重的过采样问题。

在以往的方法中,元学习从基类中选取元任务样本与新类匹配,以模拟少镜头检测任务。TFA 修改了分类和回归 box ,超过了元学习。MPSR减轻了少样本数据集的尺度偏差,但这会使模型变得复杂。 RPN 够识别新样本,最终的定位也较准确。
如图,将检测到的新样本误分类为其他基类是错误的主要来源(cow–bird)。

作者发现,有些类别的类间相似度达到了0.59,这会导致分类错误,然而基于类别级的正向分类器在这种数据匮乏的环境中不起作用。但对比学习在识别时是有效的。监督批处理对比方法扩展到少镜头目标检测时,对比学习的对象表征意识到类内紧凑和类差异,可以减少新对象分为相似基类的错误分类。
作者提出了基于 FSCE 的少样本目标检测方法,当检测到少样本新数据时,在感兴趣区域头部增加一个对比分支,对比测量结果和提议目标之间的相似性。这种有监督对比目标的优化将不同类别的样本区分开。提出的对比目标,对比提议编码(CPE) loss,在原分类和目标处以多任务的方式制定目标。
相关方法
- 少样本学习
- 少样本目标检测
- 对比学习
方法
FSCE 包含一个两阶段的训练,首先在基础数据集上训练 Faster RCNN ,然后在基础+新数据集上训练微调后的检测器,在微调时会冻结特征提取,同时这个特征会被一个对比器监督,对比提议编码(CPE) loss 会被分类和回归目标共同优化。

1.准备工作
- 思考微调方法:TFA 仅仅调节了网络的最后两层全连接层,冻结了其他的结构,这减少了对新数据的过拟合。FPN、RPN 则可以直接加入新类,不用多余的调整和训练。
在基线TFA中,解冻后的 RPN 和 RoI特征提取会降低新类的检测性能,但如果训练得当,可以加强新的检测结果。因此,作者提出了一个新的基线,微调特征提取器和检测头,能更好地适应新数据。 - 强大的基线:检测性能会因为网络被新样本微调而下降。然而,在数据丰富的基础训练阶段和新的微调阶段之间的 RPN 和 RoI 统计数据差距很大。新样本加入后的建议框仅仅是基线的四分之一,样本框也大量减少,这会导致检测时绕过了 NMS 。作者的观点是许多低分的锚定框被抑制,拯救他们可增加建议框,同时,平衡样本建议框分数一控制梯度下降幅度(?)。
作者使用了未冻结的 RPN 和 ROI,将建议框分数记为两倍,这样增加了建议框数量,又将建议框数量减半以抑制建议框过多,如表1,为基线结果。

2.Contrastive object proposal encoding
在二阶段检测器中,RPN 输入主干网络提取的特征,输出建议框,ROI 头分类回归每个建议框。Faster RCNN 固定建议框的大小,但是在少样本的情况下,有错误识别和分类的情况。因此对比特征以获得更加健壮的表达可以解决此问题。
为了让对比特征融合到 Faster RCNN 中,作者在 ROI 头中加入了一个平行的对比分支。由于 ROI 特征向量 x 包含 relu 后激活,在0处会被截断,因此不能直接测量两个建议框之间的相似性。在此基础上,作者利用具有负代价的多层感知器( MLP )的对比分支,在 MLP-head 编码的 ROI 特征上测量目标提议表示之间的相似度得分,并实现优化,以最大限度地提高来自同一类别的目标之间的一致性,提高来自不同类别建议框的独特性。
在分类时,作者采用了余弦相似度,预测第
i
i
i 个实例为第
j
j
j类时,
l
o
g
i
t
logit
logit 是通过 ROI 特征
x
i
x_i
xi 和类权值
w
j
w_j
wj 之间的比例余弦相似度来计算的,如下:
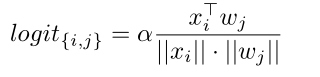
其中,
α
\alpha
α 是一个放缩因子。
这个对比分支让簇间更加紧促,从而增强了网络的泛用性。
3.CPE Loss
在 N N N 个 ROI 特征 { z i , u i , y i } i = 1 N \{z_i,u_i,y_i\}_{i=1}^N {zi,ui,yi}i=1N 中, z i z_i zi 是第 i i i 个建议框的对比头编码 ROI 特征, u i u_i ui 表示其与真实框匹配的 IOU 得分, y i y_i yi 表示 ground-truth 的标签。

其中,
N
y
i
N_{y_i}
Nyi 是
y
i
y_i
yi 对应的建议框,
τ
τ
τ 为超参数,
z
i
~
\widetilde{z_i}
zi
表示标准化特征表示,
z
i
~
.
z
i
~
\widetilde{z_i}.\widetilde{z_i}
zi
.zi
表示两特征之间的相似度。
这个损失函数提高了具有相同标签的目标在不同投影下的相似度,使得同类别样本更加紧密,集群周围的边缘被扩大。

- 建议一致性控制:IOU ,不同于图像分类中语义信息来自于整个图像,分类检测信号来自于区域提议。低 IOU 会使偏离回归对象的中心太多,可能包含不相关的语义。作者使用了下式控制 IOU 值,
g
(
⋅
)
g(·)
g(⋅) 表示对不同 IOU 得分水平的建议赋不同的权重系数。
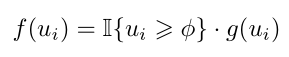
- 训练目标:第一阶段,用标准的 Faster R-CNN loss、二元交叉熵 loss L r p n L_{rpn} Lrpn 对锚点提出建议框、交叉熵loss L c l s L_{cls} Lcls 用于分类损失、smooth - l1 loss L r e g L_{reg} Lreg 用于回归对基检测器进行训练。当在微调阶段转移到新的数据时,对比损失可以在不破坏训练的情况下,加入到网络中去。
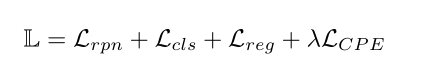
其中,
λ
\lambda
λ 用于平衡损失。
实验
数据集:PASCAL VOC、COCO
网络:Faster-RCNN(ResNet-101)+ FPN + SGD
1. 测试基准
PASCAL VOC:5类保留作为新类(5/20)
COCO:20类保留作为新类(20/80)
2. 结果
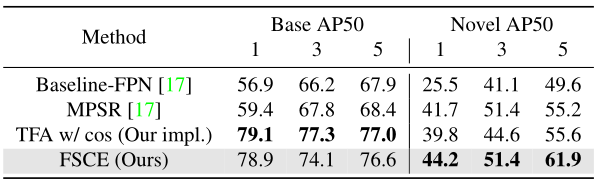
PASCAL VOC:
COCO:

3. 消融实验
组件的消融实验:

超参数对比:感兴趣区域和
τ
τ
τ

建议区域一致性:不同阈值一致性

分析:

图5为方法的可视化,可得到,在数据丰富的通用检测中,FC 分类器和余弦分类器的饱和性能基本相同。FC 层可以从足量数据中学习到复杂的决策边界,余弦分类器在少数对象检测方面有优势。实例级的类内相似度和类间相似度通过CPE损耗,并引导RoI头学习对比感知的对象提议表示。图5 ©显示了在 TFA 中较差,但在 FSCE 中较好的例子,包括新实例的漏检、新实例的低置信度分数和错误分类。
总结
作者提出了 FSOD,通过对比建议编码,准确定位错误分类的对象,这种方法成本低,适用度高。所提出的基线有广泛影响。















 2202
2202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









