






1.常见数据类型
字符型char 占1字节 (8位二进制位,可以表示2^8个数)
整型 int 占4字节
短整型short 占2字节
长整型long 占 8字节
浮点型float 占 4字节(存储的是近似值,无法判断相等0.1+0.2!=0.3)
双精度double 占8字节
Unsigned char :0000 0000 ——1111 1111 0-255 unsigned指无符号数
最高位符号位 0正1负
sizeof()关键字 可以判断所占内存大小
#include<stdio.h>
int main()
{
int a;
short b;
long c;
char d;
float e;
double f;
unsigned int r;
printf("a : %d\n",sizeof(a));
printf("b : %d\n",sizeof(b));
printf("c : %d\n",sizeof(c));
printf("d : %d\n",sizeof(d));
printf("e : %d\n",sizeof(e));
printf("f : %d\n",sizeof(f));
printf("r : %d\n",sizeof(r));
return 0;
} // 输出 a : 4 b : 2 c : 8 d : 1 e : 4 f : 8 r : 42.码制
补码:用于二进制计算
反码:所有的数据位取反(也就是除去符号位)
补码:反码尾数加1
-1补码11111111111
1补码 0000000001
-1+1 10000000000 开头的1溢出(只可以表示32位)所以只剩000000(32个0)
Int的表示范围(-2^31—2^31-1)o
Char的数据范围(-128—127)-128是10000000(110000000中的符号位溢出
char a ='a';
int b=a;
printf("b= %d \n",b); //输出b= 97 ascll码中48表0 65表A 97表a
// 或者如下
char a='a';
printf("a= %d\n",a);数据是互通的,这就是类型转换(上述为宽转换)
转换类型:宽转换(小的数据类型转换成大的) 窄转换(大转小,丢失高位)
int a=129;
char b=a;
printf("b= %d\n",b); //输出 b=-127a=129是int型,后八位是1000 0001 由于是正数,所以其补码的后八位也是1000 0001
数据之间的运算是由补码完成的,因此转换的过程用的是补码。
char b得到的是一个补码1000 0001(前面的24位没办法收到,因为char只有一个字节)且b的输出是%d,因此输出的b是一个数字而不是字符,b的补码是1000 0001 那么符号位是1(符号位不参与取反,参与运算)所以是负数,那么b的反码就是1000 0000,原码就是1111 1111 因此b=-127
若a=128 b= -128
同理,a补码后八位1000 0000
b得到的补码是1000 0000所以b是一个负数,又补码等于反码加一所以b反码本应该是1 0111 1111,但是只显示八位,因此反码是0111 1111(符号位丢失),原码就是0000 0000(0被误当做符号位),但是正常的逻辑,反码1 0111 1111 原码应该是1(符号位不变)1000 0000 所以b实际上是-128
3.数据输出格式
定义变量要有初始化
int a = 0; // int a 指程序运行时开辟4字节的空间给a,并初始化a
printf("a= %d\n",a); // %d指输出十进制整数 /n换行
char b ='b'; //定义字符用''括起来
printf("b= %c\n",b); //%c指输出字符
char* c="hello"; //*指定义一个指针变量 定义字符串用""括起来
printf("c= %s\n",c); //%s指输出字符串
double e=3.141592648;
printf("e= %.8f\n",e);//.8f是指输出精度(小数点有效数字)为8的浮点数4. 变量的分类
1)局部变量
定义在函数之内,作用域在函数之内,函数结束时自动回收
2)全局变量
定义在全局(头文件下,main()之外),作用在全局,程序开始时创建,结束时回收,尽可能不用全局变量,因为在函数内可以修改全局变量的值,如果刚开始定义好,不小心在函数中改变就会改变 (如果局部变量与全局变量重名,函数中优先使用局部变量)
#include<stdio.h>
/* #include"ext.h"*/
int b=4; //全局变量b,a;
int a=1;
void text ()
{
int a=3; //重名;此处的a是局部变量
b=b+a; //优先使用局部变量,此时b=7
}
int main()
{
text();
b=b+5;
printf("b= %d\n ",b); //输出结果 :b= 12
return 0;
/* ext(); */ /*调用ext函数*/
} 3)extern 关键字
关键字 extern int b;声明一个变量在其他模块中(如ext函数)
#include<stdio.h>
extern int b; //extern函数调用规则
void ext()
{
b=30; //强行改变上段代码中全局变量的值
printf("b=%d \n",b); //输出结果 : b=30
} 4)静态变量
static 修饰全局变量,那只有本文件可见,无法被extern调用到别的文件
static 修饰局部变量,初始化只有一次,程序结束时释放,不影响作用域。
#include<stdio.h>
void teststatic()
{
int a=10; //初始化局部变量a
a++;
printf("a: %d \n",a);
}
int main()
{
teststatic(); //输出a: 11
teststatic(); //输出a: 11 重新对a初始化
return 0;
}
// static int a=10; 在int a前加上静态变量修饰符static
输出结果: a:11
a:12 不再重新初始化5)常量关键字const
修饰变量,修饰后不可修改(修改会报错),只读,但通过指针可以间接改变;const 修饰的变量必须初始化;
#include<stdio.h>
int main()
{
const int a=0;
char* b=&a; //定义一个字符型指针变量b &是一个取址符号
*b=20; //*不能省,*b指的是指针b,指针b才指向a的地址,b不行
printf("a= %d\n",a);
return 0;
} 和宏的区别:宏在定义后无法修改,而const可以通过指针间接修改
Const在程序运行时给变量赋值,宏则在编译期间预处理阶段就被替换
#include<stdio.h>
#define M 100 //定义宏,无法修改
int main()
{
int a=0;
a=a+M;
printf("a= %d\n",a); //输出结果:a= 100
return 0;
} 5.计算机程序执行的五大分区
1)栈: 存放局部变量
Main函数的叫系统栈,其余函数叫函数栈
2)堆: 用户手动申请的变量(存放动态数据)不会自动销毁,需手动释放
3)静态全局区: 存放静态变量(包括静态局部变量)和全局变量,程序结束,系统自动回收
.data段: 已初始化的全局变量
.bss段: 未初始化的全局变量
4)文字常量区(放在此区域不可更改): 放字符串常量
5)代码段 二进制代码
6.自加以及与或运算
注意:c语言中非0就是真
#include<stdio.h>
main()
{
int a=-1,b=-1,c=0;
if(a++ && ++b || c++)
{
printf("true\n");
}
else
{
printf("false\n");
}
printf("a: %d,b: %d,c: %d\n",a,b,c); //输出:false
a:0
b:0
c:1
}
// if(++a && ++b || c++) 输出:false
a:0
b:-1
c:1
&&左边是假的,就不再执行右边 ||左边是真的也一样7. 结构体(复合数据类型)
1)定义、初始化、类型替换
typedef 与define的区别:typedef是编译时数据类型替换,define是在预处理阶段进行文本替换。
#include<stdio.h>
struct person //定义一个结构体类型(类似于int m中的int)
{
char* name ;
int age;
int id;
};
typedef struct person per; //类型替换(per替换struct person)
#define PER struct person //类型替换(PER替换struct person)
void print(struct person p) //用于输出的函数 使代码看着简洁
{ //p类似int m中的m
printf("name: %s, age: %d, id: %d\n",p.name,p.age,p.id);
}
main()
{
per zhang; //用per替换struct person(PER也可以)
zhang.name="zhangsan"; //zhang类似于int m中的m 张三类似m的具体值
zhang.age=20;
zhang.id=10;
print(zhang); //输出:name: zhangsan, age: 20, id: 10
struct person li = {"lisi",21,1}; //结构体的初始化
print(li); //输出:name: lisi, age: 21, id: 1
return 0;
}2) 结构体嵌套、嵌套初始化
struct man
{
struct person p;
int sex;
};
void printm(struct man m)
{
print(m.p);
printf("sex= %d\n",m.sex);
}
main()
{
struct man li;
li.p.name="lisi";
li.p.age=16;
li.p.id=12;
li.sex=1;
printm(li);
struct man liu={{"liudong",20,13},0}; //嵌套结构体初始化
printm(liu); //两个结构体所以用{{}}并且不能漏=
return 0;
}3)结构体内存占用规则
结构体的字节对齐:计算机调用每条字节要相同,按照基本数据类型最大的那个类型对齐,所以小的数据类型尽量放一起
Int和char 按四个字节对齐 所以两个四字节, 8个字节
Int,char,double先八个 然后八个 16字节
Int,double,char 8+8+8 24字节
Int,char b[9],double 8(4int 4char)+8(5char 3空白)+8 24字节
注意:俩不同结构体不可以占用一条对齐
#include<stdio.h>
struct small
{
int a;
char b;
};
struct size
{
int c;
struct small s;
double d;
}
main()
{
printf("size: %ld \n",sizeof(struct size));
} //输出:size: 24 (int c:8 struct small:8 double 8)8.共用体
int与char共用内存
#include<stdio.h>
union gong
{
int a;
char b; //char b[5]; 输出8,因为char,int是按4字节读,4不够一次只能加4
};
int main()
{
union gong d;
d.a=67;
printf("= %c\n",d.b);
printf("size: %d\n",sizeof(d));
return 0; //输出:d= C
size: 4
}9.大小端模式
大端模式:低字节存在高地址
小端模式:低字节存在低地址(小低低)
0x12345678 0x是十六进制标志,12345678是一个16进制数
低地址 高地址
大端 0x12 0x34 0x56 0x78 C51 8*16^0 1*16^7所以78是 低字节
为什么是12 是因为一个16进制数是4个二进制位 两个(12)就是8个二进制位,刚好一个字节
小端 0x78 0x56 0x34 0x12 ARM
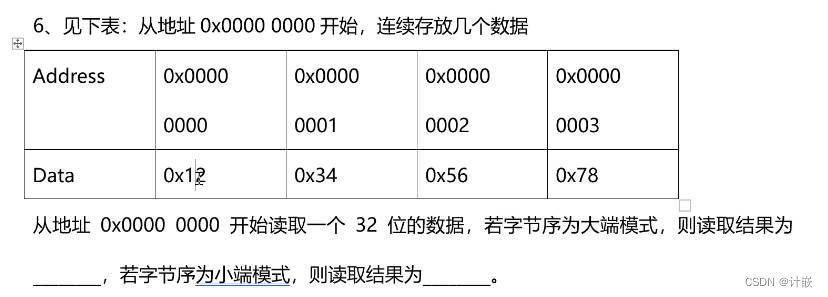
12 34 56 78
78 56 34 12
10.枚举体
#include<stdio.h>
enum data
{
one,two,three,four,five
};
int main()
{
enum data d=three;
printf("d= %d\n",d); //d=one 输出d=0 d=two 输出d=1 依次累加
switch(d)
{
case one:
printf("1!\n");break;
case two:
printf("2!\n");break;
case three:
printf("3!\n");break;
case four:
printf("4!\n");break;
case five:
printf("5!\n");break;
}
return 0; //输出d= 2 3!
}
















 4471
4471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









