







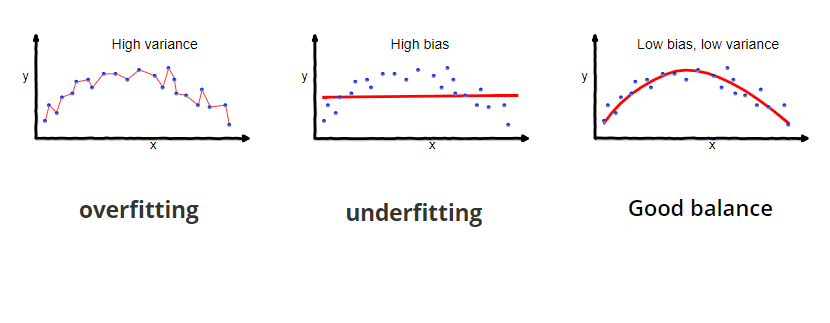
C2-3.2.1 诊断Bias(偏差) and variance(方差)——误差的两大来源
1、What is bias?
Bias is the difference between the average prediction of our model and the correct value which we are trying to predict. Model with high bias pays very little attention to the training data and oversimplifies the model. It always leads to high error on training and test data.
- 总结:就是 真实值y 与 预测值y^ 之间的差
- 高偏差——即:欠拟合。 ※※模型简单 / 输入特征较少(X1,X2,X3 房屋面积,房屋层数,房屋年龄),导致了欠拟合。
- 诊断:训练集损失函数高——即:高偏差
2、What is variance?
Variance is the variability of model prediction for a given data point or a value which tells us spread of our data. Model with high variance pays a lot of attention to training data and does not generalize on the data which it hasn’t seen before. As a result, such models perform very well on training data but has high error rates on test data.
-
总结:
-
理解一:方差度量了同等大小的训练集的变动导致学习性能的变化, 刻画了数据扰动所导致的影响。当模型越复杂时, 拟合的程度就越高, 模型的训练偏差就越小。 但此时如果换一组数据可能模型的变化就会很大, 即模型的方差很大。 所以模型过于复杂的时候会导致过拟合。
-
※理解二:是指模型预测的多样性:对于一组给定范围的数据,我们预测的很好。。但是换了一组数据后我们预测的结果没有那么理想。。。——这也是方差的定义:说一个小孩学习成绩方差大,该不该派他去参加比赛
-
-
高方差:即“过拟合”,泛化能力差,因此在训练集上变现的很好,但是在测试集上变现的不好。导致的是 过拟合
-
训练集的损失函数 和 交叉验证集损失函数 相差很高——有一个高variance
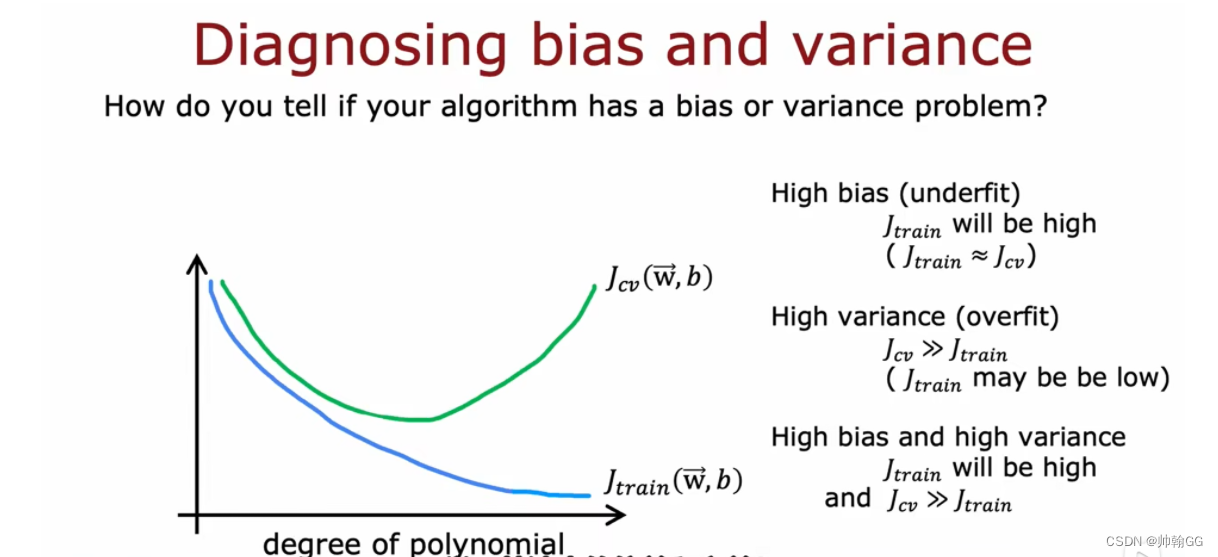
- 【补充】: 随着 梯度下降 ,次数的不断增加,J train(W,b)不断下降
3、诊断 偏差与方差 / 欠拟合与过拟合
通过 训练集损失函数值 与 交叉验证集损失函数值 来判断是否发生过拟合与欠拟合
- 高偏差(也叫:欠拟合):
- J train 训练集损失函数高 && Jcv 交叉验证集损失函数也高
- 高方差 (也叫:过拟合):
- J train >> Jcv
- J train训练集损失函数有可能也不高
- 高偏差 和 高方差
- J train 高
- J cv >> Jtrain
4、例子
例子1:线性回归(房价预测)
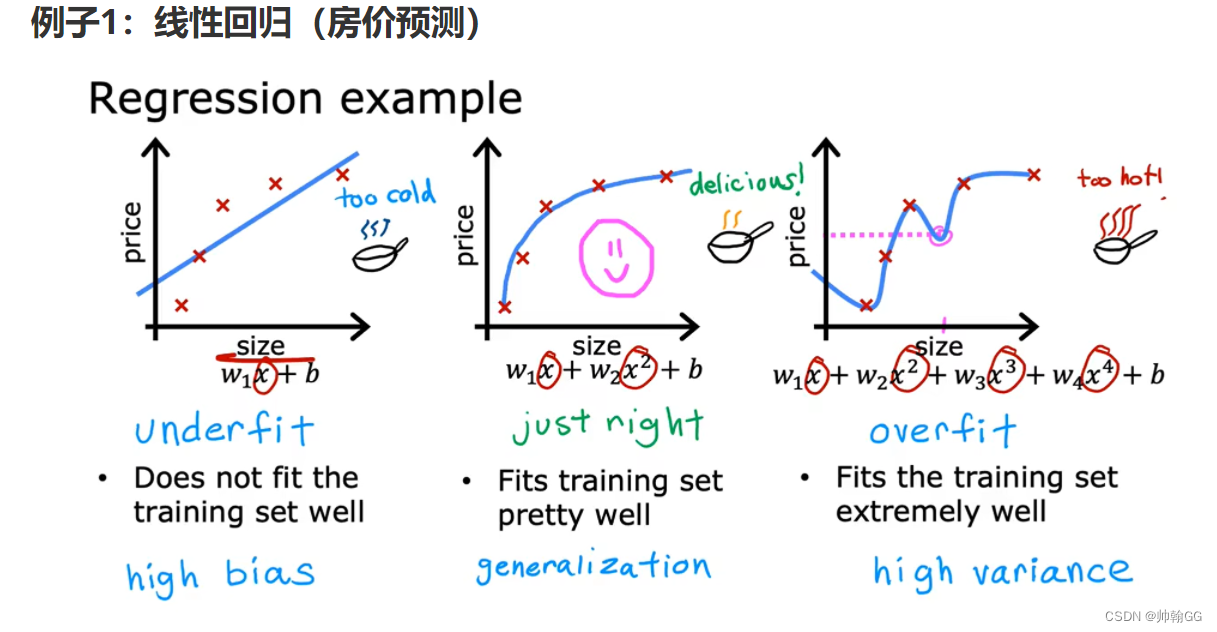
Fig.1 Linear regression(截屏自吴恩达机器学习)
- 第一个图:是**“欠拟合”** (训练的特征输入较少(X1,X2,X3…房屋面积,房屋层数,房屋年龄)或缺乏复杂性而导致欠拟合),预测出来的数据有很大的误差,训练集数据少,拟合不足(underfit)(尤其是在最后几个数据中,实际数据趋于平缓,而我们的预测线还是升高的)—— 展示出来的结果就是:数据具有 “高偏差”
- 第二个图:是我们合理假设的一个模型。可以看到,选取了合理的模型后,图像大致穿过了样本点。像极了做物理实验时,最后用一条曲线大致地穿过既定的样本点;和第一张图比起来,至少损失值大大下降了。 具有很好的 ——“泛化能力”
- 第三个图:是 “过拟合”,过拟合是指训练误差和测试误差之间的差距太大。换句话说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集"死记硬背"(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
例子2:Logistic回归
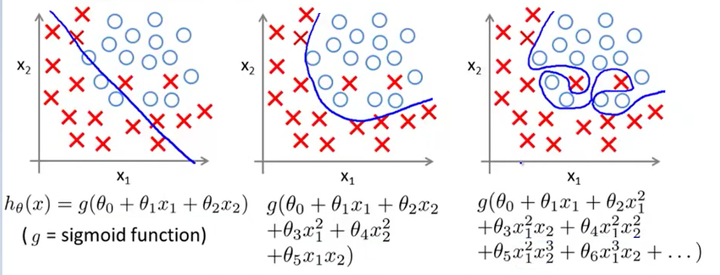
Fig2.Logistic regression(截屏自吴恩达机器学习)
三幅图哪个更好呢?不多说,第二张图应该是合理的划分方式,而不是像第三张图那样一板一眼。
为什么会出现过拟合现象?
造成原因主要有以下几种:
1、训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2、训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,影响了真实输入和输出之间的关系。
3、**模型过于复杂。**模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。














 2803
2803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









