







Learning Lightweight Lane Detection CNNs by Self Attention Distillation[2019/8 ICCV]----阅读笔记
Paper and Code
Abstract
由于车道注释中固有的非常细微和稀疏的监控信号,训练用于车道检测的深度模型具有挑战性。如果没有从更丰富的背景中学习,这些模型在具有挑战性的场景中通常会失败,例如,严重的遮挡、模糊的车道和较差的照明条件。在本文中,我们提出了一种新的知识提取方法,即自我注意提取(self attention distillation SAD),它允许模型从自身学习,并在没有任何额外的监督或标签的情况下获得实质性的改进。具体来说,我们观察到从训练到合理水平的模型中提取的注意力图将编码丰富的上下文信息。有价值的上下文信息可以作为一种“免费”监督的形式,通过在网络本身内执行自上而下和逐层的注意力提取,用于进一步的表征学习 。SAD可以很容易地结合到任何前馈卷积神经网络(CNN)中,并且不会增加推理时间。我们在三个流行的车道检测基准(TuSimple、CULane和BDD100K)上使用轻量级模型(如ENet、ResNet18和ResNet-34)验证SAD。最轻的模型,ENet-SAD,表现比较好,甚至超过现有的算法。值得注意的是,与最先进的SCNN相比,ENet-SAD的参数少了20倍,运行速度快了10倍[16],同时在所有基准测试中仍能实现令人信服的性能。
这篇文章对于自动驾驶的车道检测应该有帮助。
Introduction
问题的提出?
车道检测,常将车道检测视为语义分割任务,其中图像中的每个像素被分配有二进制标签,以指示其是否属于车道。这些方法严重依赖车道分割图作为监控信号。
由于车道又长又细,注释车道像素的数量远远少于背景像素。从这种微妙和稀疏的注释中学习成为为任务训练深度模型的主要挑战。一个合理的方法是增加车道注释的宽度。但是,它可能会降低检测性能。
解决方案?
MTL可以提供额外的监控信号,但它需要额外的工作来准备注释,例如,场景分割地图、消失点或可驾驶区域。(VPP)
MP可以帮助在神经元之间传播信息,抵消稀疏监督的效果,更好地捕捉场景上下文。但是,由于MP的开销,极大地增加了推理时间。(SCNN)
SAD的解决方案的提出
在这项工作中,我们提出了一个简单而新颖的方法,允许车道检测网络加强其自身的表示学习,而不需要额外的标签和外部监督。另外,不增加基础模型的推理时间。我们的方法被命名为自我注意蒸馏(Self Attention Distillation SAD)。顾名思义,SAD允许网络利用从其自身层获得的注意力图作为其下层的蒸馏目标。这种注意力提取机制用于补充通常的基于分割的监督学习。
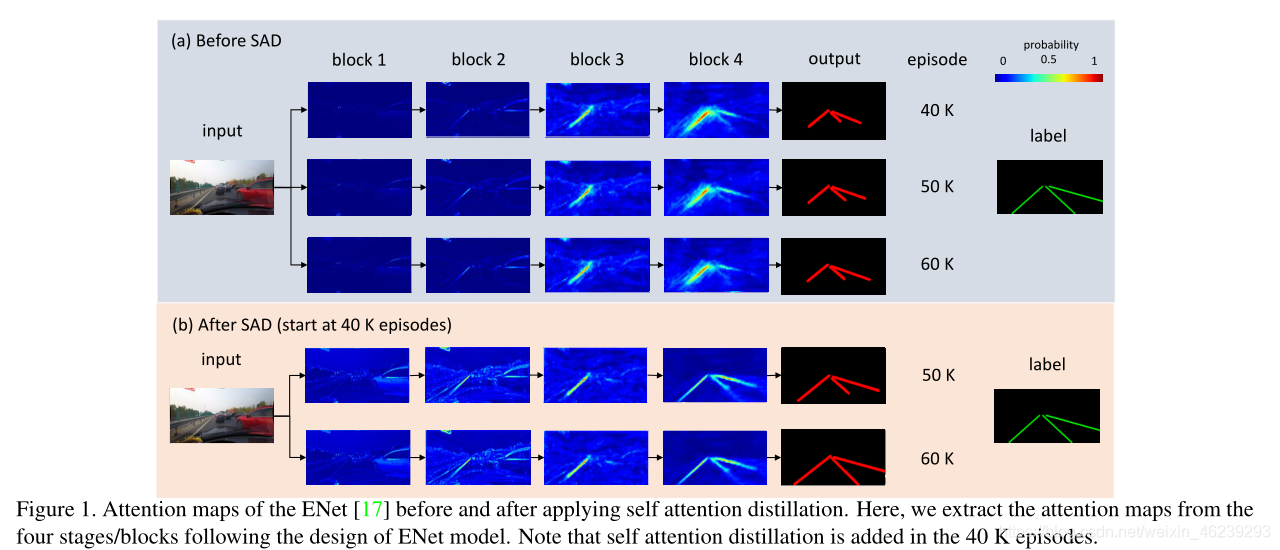
应用自我注意力蒸馏前后的注意图(Figure 1) 主要讲述了两个重要点:
(1) the attention maps of lower layers are refined, with richer scene contexts captured by the visual attention.
(2) the better representation learned at lower layers in turn benefits the deeper layers.

通过原文,我得理解就是:
1.浅层网络块(block)模仿mimic深层网络块,使浅层网络块的注意力图更加细致。
2.浅层网络块细致的注意力图更加有利于深层网络块的学习。
贡献点
(1)我们提出了一种新的注意力蒸馏方法,即SAD,以增强基于CNN的车道检测模型的表示学习。SAD只在训练阶段使用,在部署过程中不会带来计算成本,我们的工作是首次尝试使用网络的注意力图作为蒸馏目标。
(2)我们仔细而系统地研究了SAD的内在机制,考虑在不同层次的模拟路径中进行选择,以及将SAD引入培训过程以提高收益的时间点。
(3)我们验证了SAD对提高小车道检测网络性能的有用性。
Related Work(略过)
Lane detection(略过)
Knowledge and attention distillation(略过)
知识蒸馏最初是由[11]提出的,目的是将知识从大网络转移到小网络。通常在知识提炼中,一个小的学生网络模仿大的教师网络的中间输出以及标签。在[7,21]中,学生和教师网络共享相同的容量,模拟是在具有相同维度的层对之间进行的。侯等人[12]还研究了异构网络之间进行知识蒸馏。最近的研究[24,19]将知识蒸馏扩展到注意力蒸馏。例如,谢尔盖等人[24]介绍了两种类型的注意力蒸馏,即基于激活的注意力蒸馏和基于梯度的注意力蒸馏。在这两种提炼中,学生网络是通过学习从教师网络中得到的注意力图来训练的。提出的SAD与[24]的不同之处在于我们的方法不需要教师网络。蒸馏是以分层和自上而下的方式进行的,其中注意力知识是逐层传播的。这在文学上是新的。值得注意的是,我们的重点是研究提取分层注意力用于自学的可能性。这不同于现有的利用视觉注意力来加权特征的研究[4,13,24]。
Methodology
3.0 Lane detection is commonly formulated as a semantic segmentation task:
车道检测通常被表述为语义分割任务:
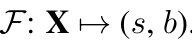
input image X

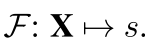
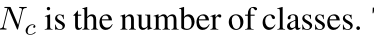
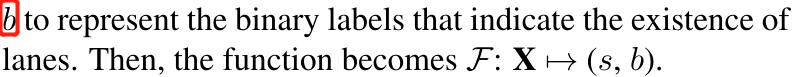
s 由输入X(image)每个像素(pixel)的label组成
**Nc**是类的数目
b来表示表示车道存在的二进制标签
3.1 Self Attention Distillation
除了使用上述用语义分割训练车道检测网络的车道存在预测损失来之外,我们还旨在执行分层和自上而下的注意力提取来增强表示学习过程。由于注意力地图来自网络本身,因此建议的SAD不需要任何外部监督或附加标签。一般来说,注意力地图可以分为两类,即基于激活的注意力地图[24]和基于梯度的注意力地图[24]。基于激活的注意力图是通过处理特定层的激活输出获得的,而基于梯度的注意力图是通过使用层的梯度输出获得的。在实验中,我们根据经验发现,基于激活的注意力提取产生了相当大的性能增益,而基于梯度的注意力提取仍然有效。因此,在下面的章节中,我们只讨论基于激活的注意力提取。
[24 ]Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In International Conference on Learning Representations, 2017
Activation-based attention distillation(基于激活的注意力提取)
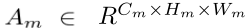
Am denote the activation output of the m-th layer of the network (表示网络第m层的激活输出)
Cm, Hmand Wm denote the channel, height and width, respectively (表示通道、高度和宽度)
m denote the number of layers in the network (表示网络中的层数)
The generation of the attention map is equivalent to finding a mapping function :
注意力图的生成相当于找到一个映射函数G:
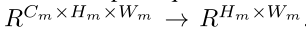
该图中每个元素的绝对值代表该元素在最终输出中的重要性。
因此,这个映射函数可以通过计算这些值在通道维度上的统计来构建。下面给出了三种计算方法:
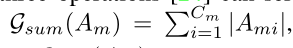

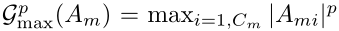
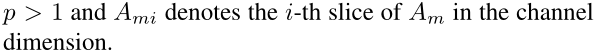
Ami 表示在通道这一维度的第 i-th 切片 ( 也就是通道这一维度的第几个通道 )
三种映射函数之间的差异:

与Gsum(Am)相比,Gpsum(Am)对激活较高的区域赋予了更多的权重。p越大,对这些高度激活区域的关注就越多。与Gpmax(Am)相比,Gpsum(Am)偏差更小,因为它计算多个神经元的权重,而不是选择这些神经元激活的最大值作为权重。
Adding SAD to training (在训练中加入SAD)
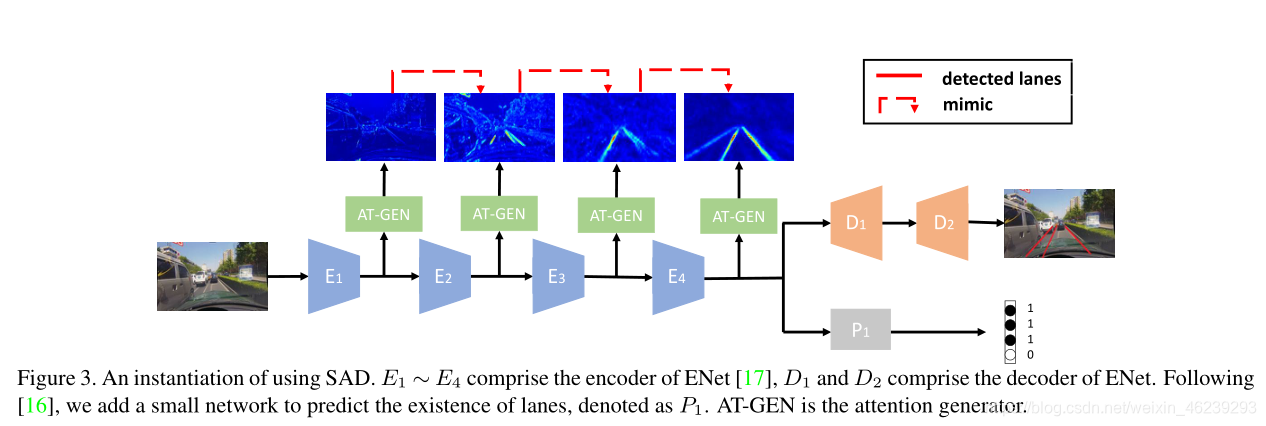

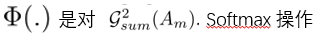


AT-GEN attention generator
successive layer-wise distillation loss(连续分层蒸馏损失公式)
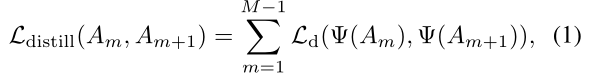
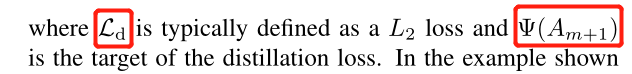
Total Loss
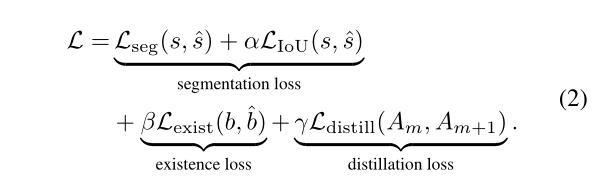
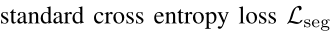
交叉熵损失

Np,Ng,No都是数像素的数量

二元交叉熵
s 分割图
b 是二进制表示的label
3.2 Lane Prediction
对于CULane,在推理阶段,我们将图像输入到ENet模型中。然后得到多通道概率图和车道存在向量。根据[16],最终的输出结果如下:首先,我们使用9 × 9核来平滑概率图。那么,对于每一个概率大于0.5车道,我们每20行搜索对应的概率图,寻找概率值最高的位置。最后,我们使用三棱曲线来连接这些位置,以获得最终输出。

3.3. Architecture Design
最初的ENet模型是由ENet、D1和D2组成的编码器-解码器结构。在[16]之后,我们添加了一个小网络P1来预测车道的存在。编码器模块是共享的,以节省内存空间。除了这种修改,我们还观察到一些有用的技术来修改ENet,以在车道检测任务中获得更好的性能。增加了扩张卷积[22]来代替车道存在预测分支中的原始卷积层,以在不增加参数数量的情况下增加网络的感受野。在最初的设计中,E4E的特征地图的分辨率仅为36 × 100。这导致严重的信息丢失。因此,我们使用特征连接来将E4的输出与E3的输出融合,以便编码器的输出可以受益于在先前层中编码的信息。
4. Experiments
图5显示了我们在实验中使用的三个数据集的几个视频帧:


评价指标:accuracy、F1-measure、IoU

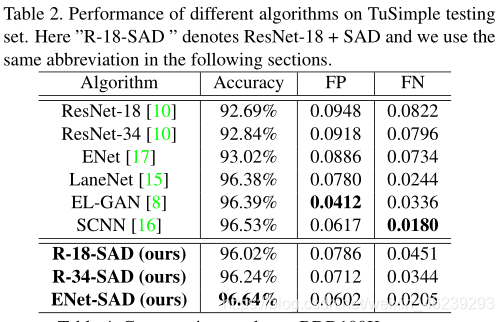
TuSimple 数据集测试
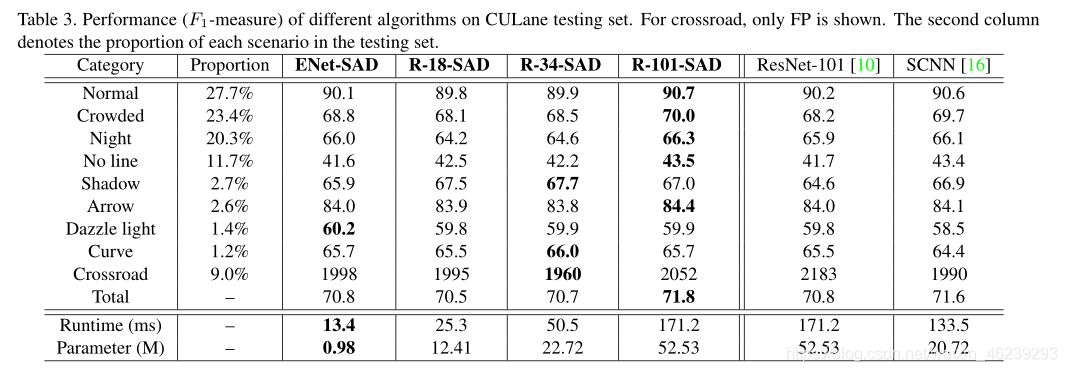
CULane(F1-measure)数据集测试
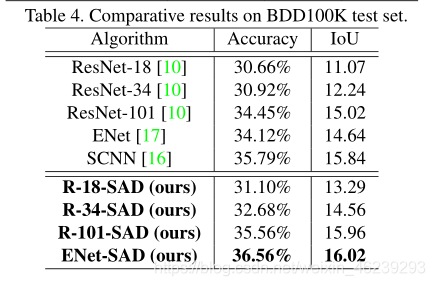
BDD100K 数据集测试
Ablation Study(消融研究)
AS.1 Distillation paths of SAD
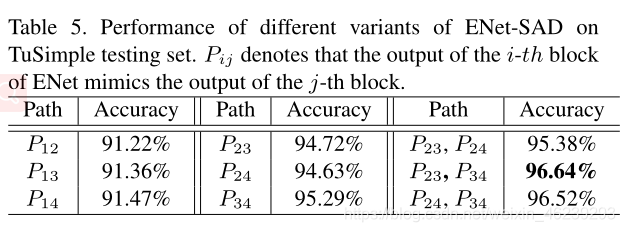
(1) SAD在中高层工作良好。
(2) 相邻层的蒸馏效果最好。
AS.2 Backward distillation
Backward distillation不好,不可取。
AS.3 SAD v.s. Deep Supervision
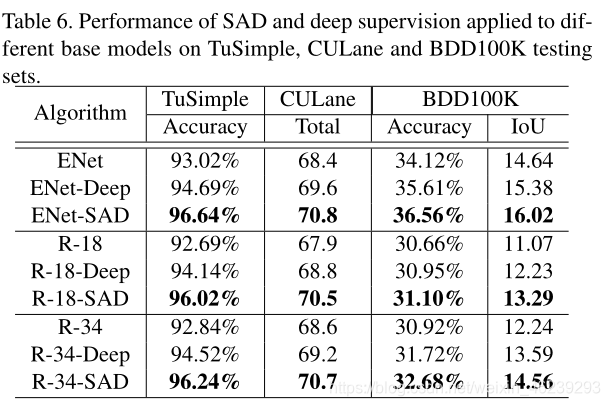
深监督有明显效果提升,但是SAD效果更好
AS.4 When to add SAD
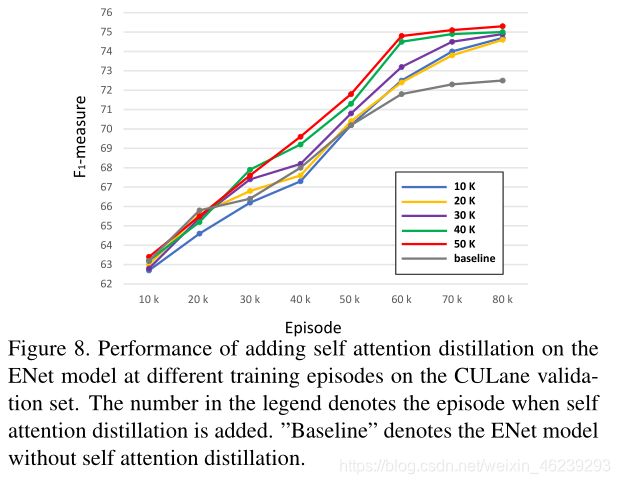
SAD加入太早,网络学习效率低。但是不管何时加入,最终效果都差不多。
可视化结果对比
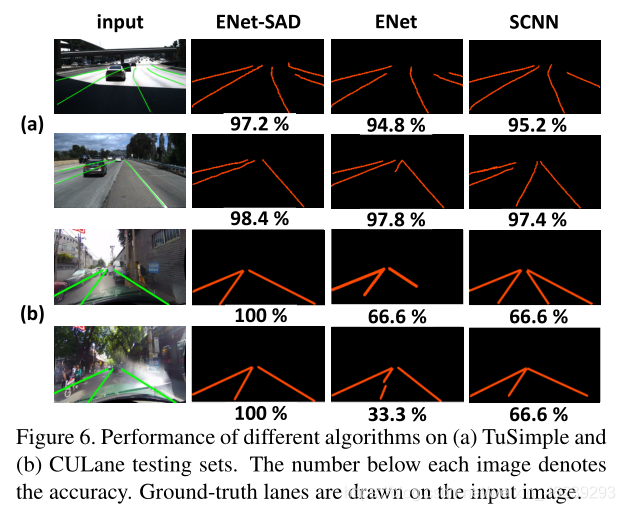
在TuSimple(a)和CULane(b)上效果,其中底下数字为accuracy:
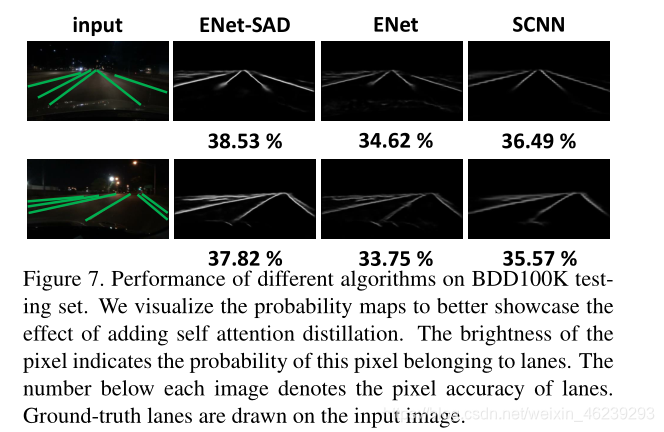
在BDD100K上效果,其中底下数字为accuracy,线条亮度值与概率值大小相关:














 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









