







IMPROVE OBJECT DETECTION WITH FEATURE-BASED KNOWLEDGE DISTILLATION: TOWARDS ACCURATE AND EFFICIENT DETECTORS
ABSTRACT
In this paper, we suggest that the failure of knowledge distillation on object detection is mainly caused by two reasons: (1) the imbalance between pixels of foreground and background and (2) lack of distillation on the relation between different pixels.
知识提取在目标检测中的失败主要是由两个原因造成的:
(1)前景和背景像素之间的不平衡;
(2)不同像素之间的关系缺乏提取。
Observing the above reasons, we propose attention-guided distillation and non-local distillation to address the two problems, respectively. Attention-guided distillation is proposed to find the crucial pixels of foreground objects with attention mechanism and then make the students take more effort to learn their features. Non-local distillation is proposed to enable students to learn not only the feature of an individual pixel but also the relation between different pixels captured by non-local modules. Experiments show that our methods achieve excellent AP improvements on both one-stage and two-stage, both anchor-based and anchor-free detectors.
注意引导蒸馏和非局部蒸馏来分别解决这两个问题。
注意力引导提取是通过注意力机制来发现前景物体的关键像素,从而使学生更加努力地学习其特征。
非局部提取的目的是使学生不仅能够学习单个像素的特征,而且能够学习由非局部模块捕获的不同像素之间的关系。
实验表明,我们的方法在基于锚和无锚的单级和两级检测器上都取得了很好的应用改进。
RELATED WORK
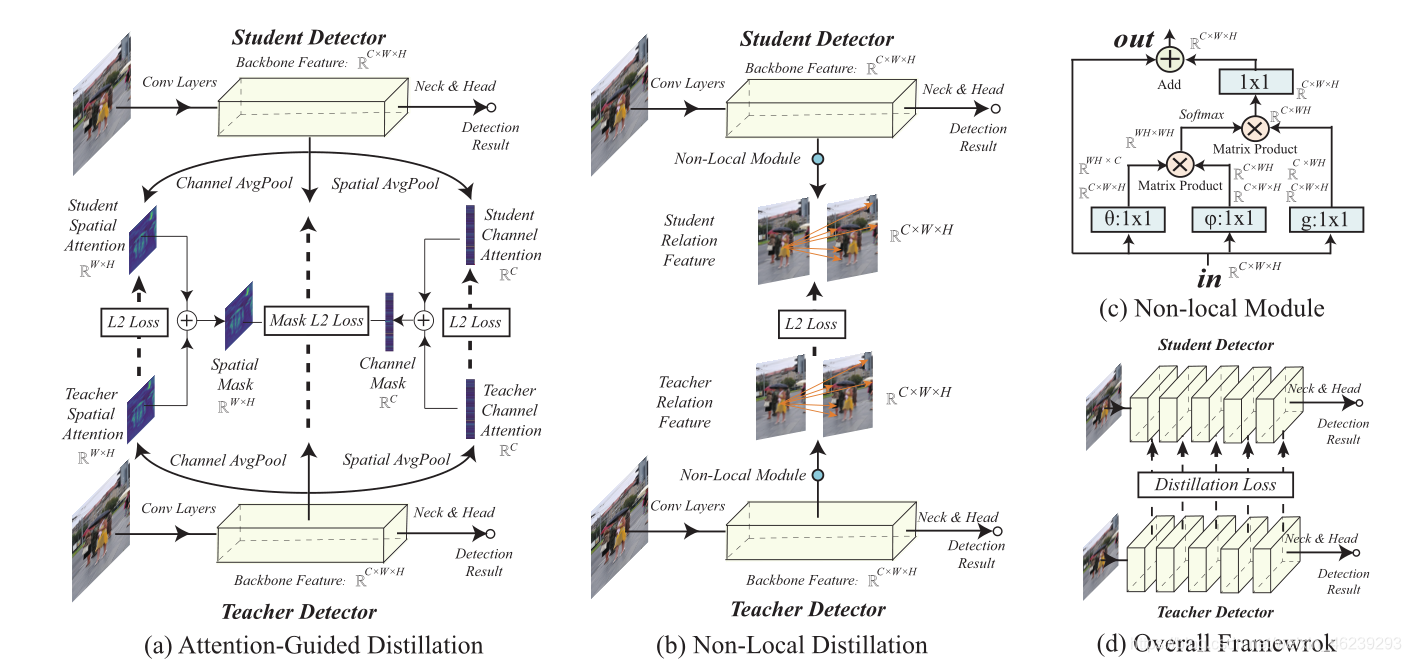
Figure 2: Details of our methods: (a) Attention-guided distillation generates the spatial and channel
attention with average pooling in the channel and spatial dimension, respectively. Then, students
are encouraged to mimic the attention of teachers. Besides, students are also trained to mimic
the feature of teachers, which is masked by the attention of both students and teachers. (b) Non-
local distillation captures the relation of pixels in an image with non-local modules. The relation
information of teachers is learned by students with L2norm loss. © The architecture of non-local
modules. ‘1x1’ is convolution layer with 1x1 kernel. (d) Distillation loss is applied to backbone
features with different resolutions. The detection head and neck are not involved in our methods.
图2:我们的方法的细节:
(1)注意力引导的蒸馏分别在通道和空间维度上平均池化产生空间和通道注意力。然后,鼓励学生模仿老师的注意力。此外,学生还被训练模仿老师的特征,这种特征被学生和老师的注意力掩码。
(2)非局部蒸馏用非局部模块捕获图像中像素的关系。教师的关系信息是由L2norm loss的学生学习的。
(3)非本地模块的体系结构。'1x1 '是具有1x1内核的卷积层。
(d)蒸馏损失适用于不同分辨率的主干特征。我们的方法不涉及检测头和颈部。
Comparison between the proposed attention-guided distillation and other methods.

如图3所示,之前基于掩模的检测蒸馏方法(王等人,2019)和我们的注意力引导蒸馏之间的差异可以总结为
(i) Our methods generate the mask with attention mechanism while they generate the mask with ground truth bounding boxes and anchor priors.
(一)我们的方法生成具有注意机制的遮罩,同时它们生成具有基础事实边界框和锚先验的遮罩。
(ii) The mask in our methods is a pixel-wise and fine-grained mask while the mask in their method is an object-wise and binary mask.
(二)我们的方法中的掩码是像素级和细粒度掩码,而他们的方法中的掩码是对象级和二进制掩码。
(iii) The masks in our methods are composed of a spatial mask and a channel mask while they only have a spatial mask. More detailed comparison with related work can be found in Appendix.
(三)我们的方法中的掩模由空间掩模和通道掩模组成,而它们只有一个空间掩模。
METHODOLOGY
ATTENTION-GUIDED DISTILLATION
A表示目标检测模型中主干的特征,其中C,H,W分别表示其通道数,高度和宽度
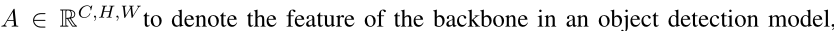
空间注意图和通道注意图的生成相当于分别求出映射函数:
s---->spatial c---->channel
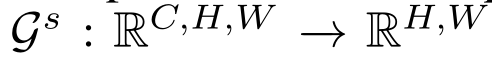
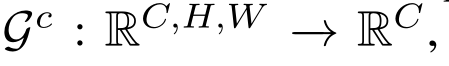
特征中每个元素的绝对值意味着它的重要性,我们通过对通道维度上的绝对值求和来构造Gs,通过对宽度和高度维度上的绝对值求和来构造Gc
I,j,k表示A在高度、宽度和通道尺寸上的ith、jth、kth
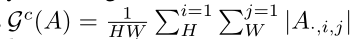
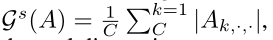
注意力引导蒸馏中使用的空间注意力掩模Ms和通道注意力掩模Mc
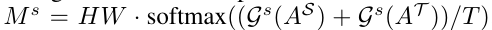
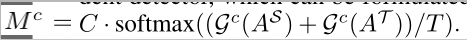
上标S和T是用来区分学生和老师,T就是Hinton那篇论文的temperature
注意力导向的蒸馏损失LAGD由两部分组成——注意力转移损失LAT和注意力掩码损失LAM
attention-guided distillation loss = attention transfer loss + attention-masked loss
LAGD = LAT + LAM
LAT 用于鼓励学生模型模仿教师模型的空间和通道注意力,可表述为:

LAM用于鼓励学生通过Ms和 Mc掩盖的L2范数损失来模仿教师模型的特征,该损失可表述为:
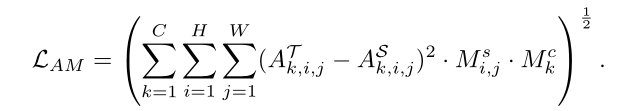
NON-LOCAL DISTILLATION
非局部模块是一种通过捕捉全局关系信息来提高神经网络性能的有效方法。
在本文中,我们应用非局部模块来捕获图像中像素之间的关系,该关系可以被公式化为:
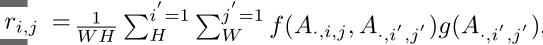
i,j是要计算其响应的输出位置的空间索引。
i ',j’是列举所有可能位置的空间索引。
f 是用于计算两个像素的关系的成对函数,
g是用于计算单个像素的表示的一元函数。
现在,我们可以将建议的非局部蒸馏损失LNLD引入到学生和教师的关系信息之间的L2损失中,该L2损失可以被公式化为:
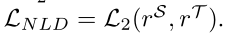
OVERALL LOSS FUNCTION
我们引入三个超参数α,β,γ来平衡不同的蒸馏损失。总蒸馏损失可表述为:
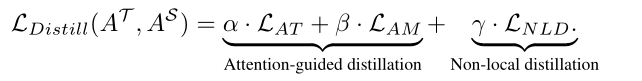
EXPERIMENT
4.1 EXPERIMENTS SETTINGS
这里原文可以具体看看细节,这里作者预训练模型且微调了,这里两级的检测和一级的检测的超参数给定。
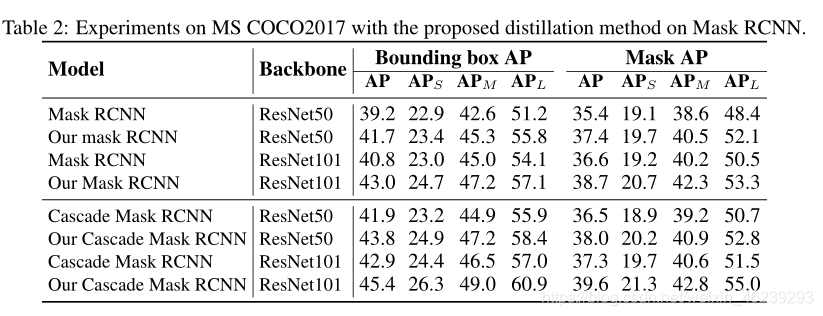
4.2 EXPERIMENT RESULTS

4.3 ABLATION STUDY AND SENSITIVITY STUDY
-
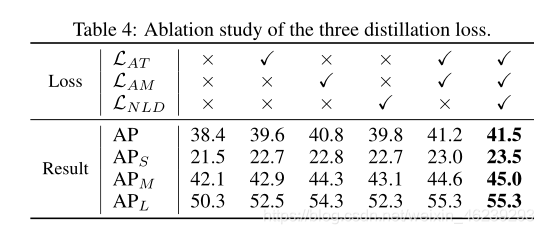
Ablation study:
attention-guided distillation (LATand LAM) and non-local distillation (LNLD) 一起用效果会更好
-
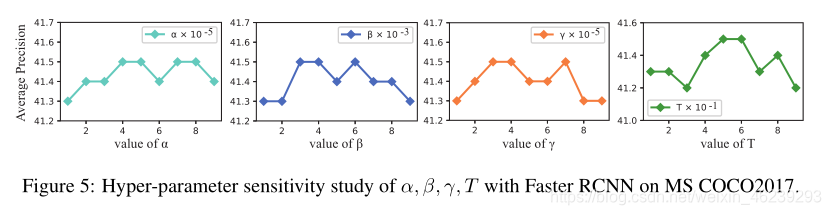
Sensitivity study on hyper-parameters:
indicating that our methods are not sensitive to the choice of hyper-parameters
-
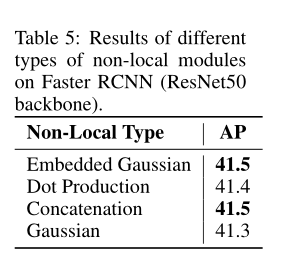
Sensitivity study on the types of non-local modules:
indicating our methods are not sensitive to the choice of non-local modules
DISCUSSION

CONCLUSION
为了提高目标检测模型的性能,本文提出了两种知识提取方法,包括注意引导提取和非局部提取。
注意力引导蒸馏利用注意力机制从整个特征图中找到关键像素和通道,然后使学生能够更多地关注这些关键像素和通道,而不是整个特征图。
非局部提取蒸馏使得学生不仅能够学习单个像素的信息,还能够学习由非局部模块捕获的不同像素之间的关系。
通过9种模型的实验,包括两阶段模型、一阶段模型、无锚模型和基于锚的模型。此外,我们还对目标检测中的师生关系进行了研究。
我们的实验表明,教师和学生的平均成绩之间有很强的正相关关系。高AP教师检测器在知识提炼中起着至关重要的作用。这种观察与之前图像分类中的结论有很大不同,在图像分类中,一个非常高精度的教师模型可能会损害知识提炼的性能。














 2791
2791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









