








 该文通过问卷调查分析现代青年人的婚育意愿,发现性别、年龄、学历及各类文化参与度对其有显著影响。数据显示,女性和高学历者、喜欢二次元和新竞技文化的人群婚育意愿较低,而年龄越大、偶像、宠物、音乐艺术文化参与度越高,婚育意愿越强。逻辑回归模型验证了这些发现,其中性别、年龄和文化参与度的变量对婚育意愿有显著相关性。
该文通过问卷调查分析现代青年人的婚育意愿,发现性别、年龄、学历及各类文化参与度对其有显著影响。数据显示,女性和高学历者、喜欢二次元和新竞技文化的人群婚育意愿较低,而年龄越大、偶像、宠物、音乐艺术文化参与度越高,婚育意愿越强。逻辑回归模型验证了这些发现,其中性别、年龄和文化参与度的变量对婚育意愿有显著相关性。
如今中国的人口生育率已经是越来越低,年轻人的婚育愿望也越来越低。这对社会老龄化以及发展产生了巨大的危害,探索现代人们的婚育意愿的影响因素是很有必要的。
本次案例采用问卷的形式收集数据,从年龄,性别,学历还有各种艺术,文化,游戏,追星,宠物的参与程度来分析是否会影响到人的婚育意愿。
首先来看一下收集到的数据,长这个样子:
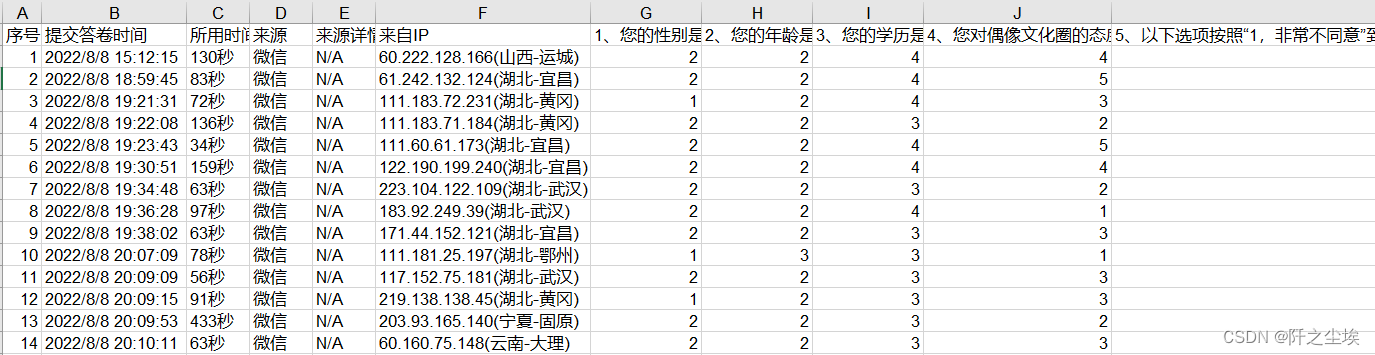
需要这代码演示数据的同学可以参考:数据
导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
sns.set_style("darkgrid",{"font.sans-serif":['KaiTi', 'Arial']})读取数据,并且整理,然后查看前五行
spss=pd.read_excel('177219894_2_青年群体亚文化圈层参与与婚育意愿调查_131_131.xlsx')
data=spss.iloc[:,6:-1]
data.head()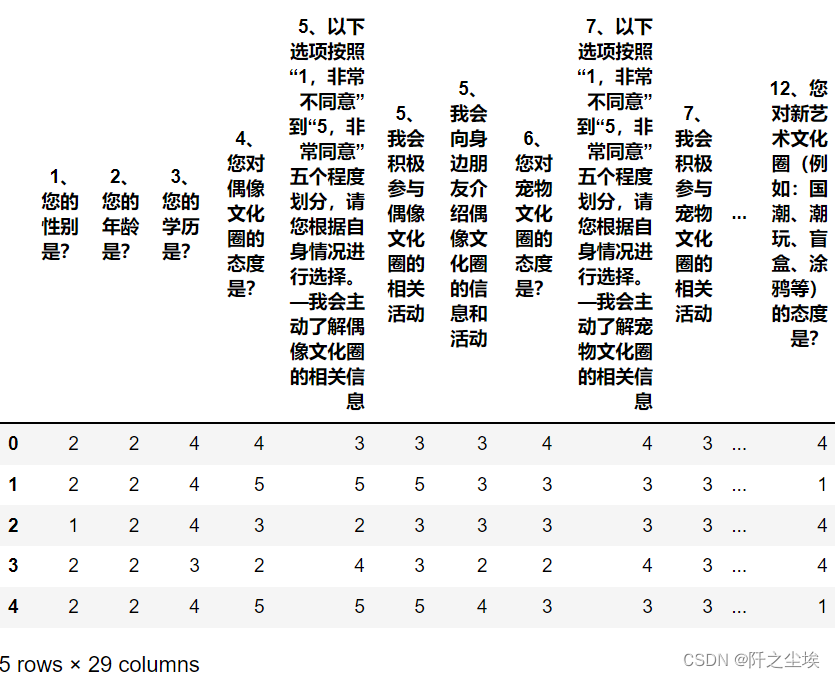
整理数据
df=pd.DataFrame()
df['性别']=data.iloc[:,0]
df['年龄']=data.iloc[:,1]
df['学历']=data.iloc[:,2]
df['偶像文化圈参与度']=data.iloc[:,3:7].sum(axis=1)
df['宠物文化圈参与度']=data.iloc[:,7:11].sum(axis=1)
df['二次元文化圈参与度']=data.iloc[:,11:15].sum(axis=1)
df['新舞音文化圈参与度']=data.iloc[:,15:19].sum(axis=1)
df['新艺术文化圈参与度']=data.iloc[:,19:23].sum(axis=1)
df['新竞技文化圈参与度']=data.iloc[:,23:27].sum(axis=1)
df['婚育意愿']=data.iloc[:,27:29].sum(axis=1)
df['婚育意愿']=df['婚育意愿'].where(df['婚育意愿']==999,np.where(df['婚育意愿']>=6,1,0))
#将婚育意愿2-6映射为0 ,7-10为1 将婚育意愿值为2到6映射为0,表示低的婚育意愿。7到10表示为1——即高婚育意愿¶
描述性统计
df.describe() #描述性统计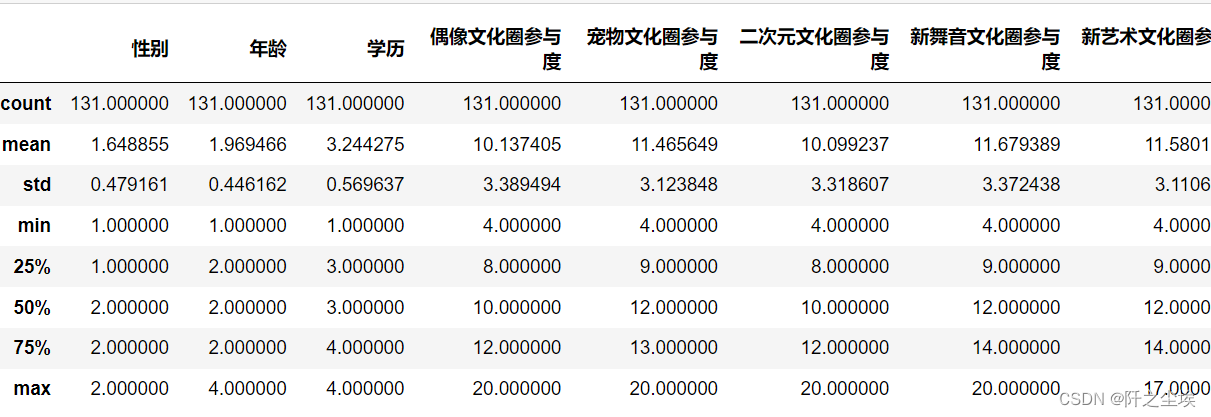
存一下
df.to_excel('清洗后的数据.xlsx',index=False) #存一下清洗整理后的数据整理为前上述9个特征变量x,最后一个婚育意愿为被解释变量y
描述性统计,画图查看收集数据人群的分布
性别年龄学历分布
#性别年龄学历分布
column = df.columns
fig = plt.figure(figsize=(7,2.5), dpi=150)
for i in range(3):
plt.subplot(1,3, i + 1) # 1行3列子图
df[column[i]].value_counts().plot.pie(title=f'{column[i]}数量对比')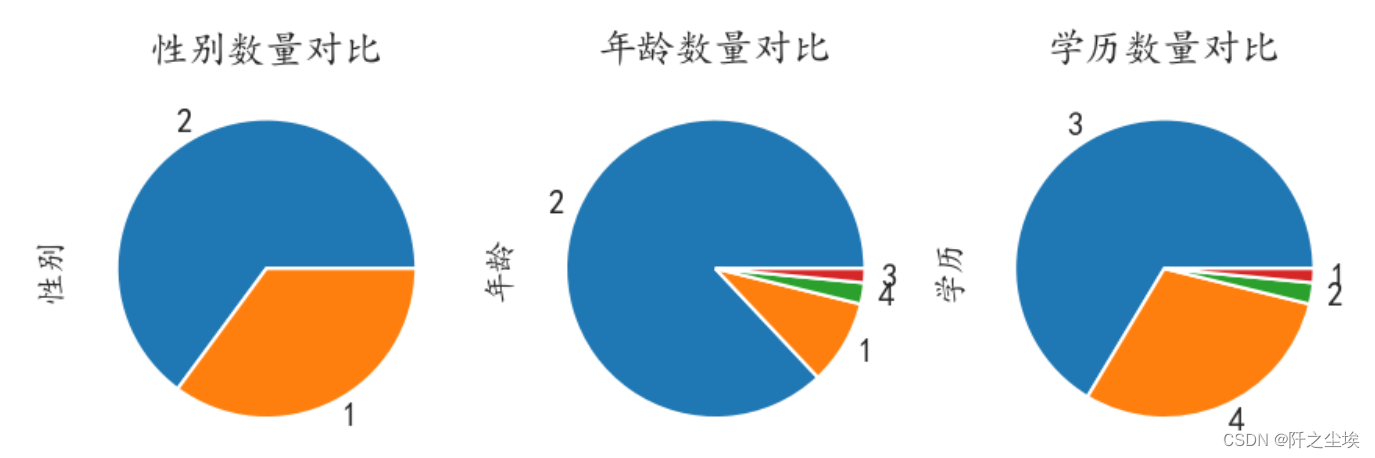
性别2表示女性,1表示男性。年龄2表示21-27年龄区间,学历3表示本科。
可以描述一下收集到的问卷中女性多......都是21-27岁年轻人.....本科生研究生比较多等等
画图查看自变量x的分布特点¶
箱线图
column = df.columns
fig = plt.figure(figsize=(10,10), dpi=128) # 指定绘图对象宽度和高度
for i in range(9):
plt.subplot(3,3, i + 1) # 2行3列子图
sns.boxplot(data=df[column[i]], orient="v",width=0.5) # 箱式图
plt.ylabel(column[i], fontsize=12)
plt.tight_layout()
plt.show()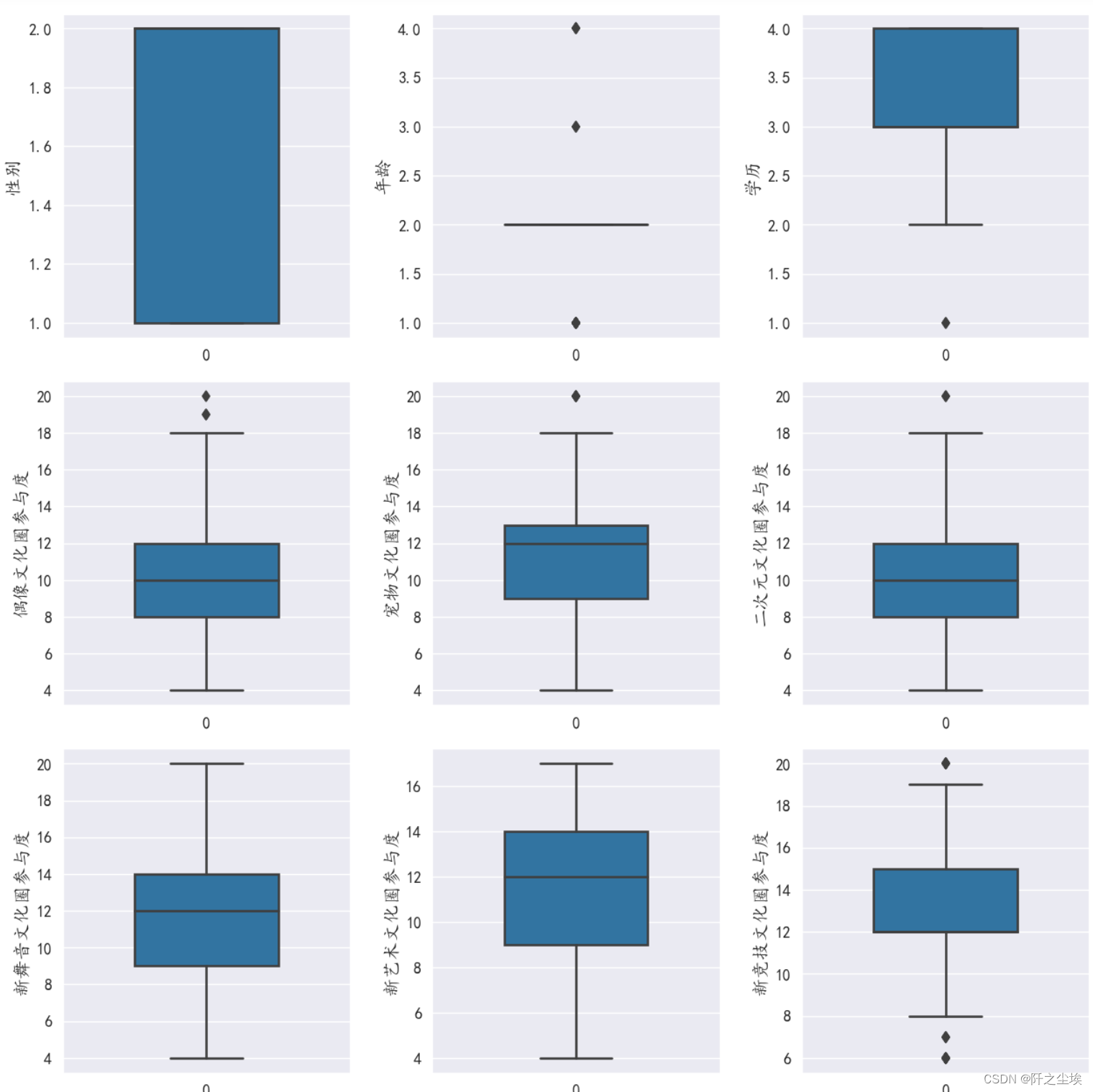
年龄都集中在第二个区间,其他变量虽然有的有异常值,但是都还好,分布较为均匀¶
核密度图
fig = plt.figure(figsize=(10,10), dpi=128) # 指定绘图对象宽度和高度
for i in range(9):
plt.subplot(3,3, i + 1) # 2行3列子图
sns.kdeplot(data=df[column[i]],color='blue',shade= True)
plt.ylabel(column[i], fontsize=12)
plt.tight_layout()
plt.show()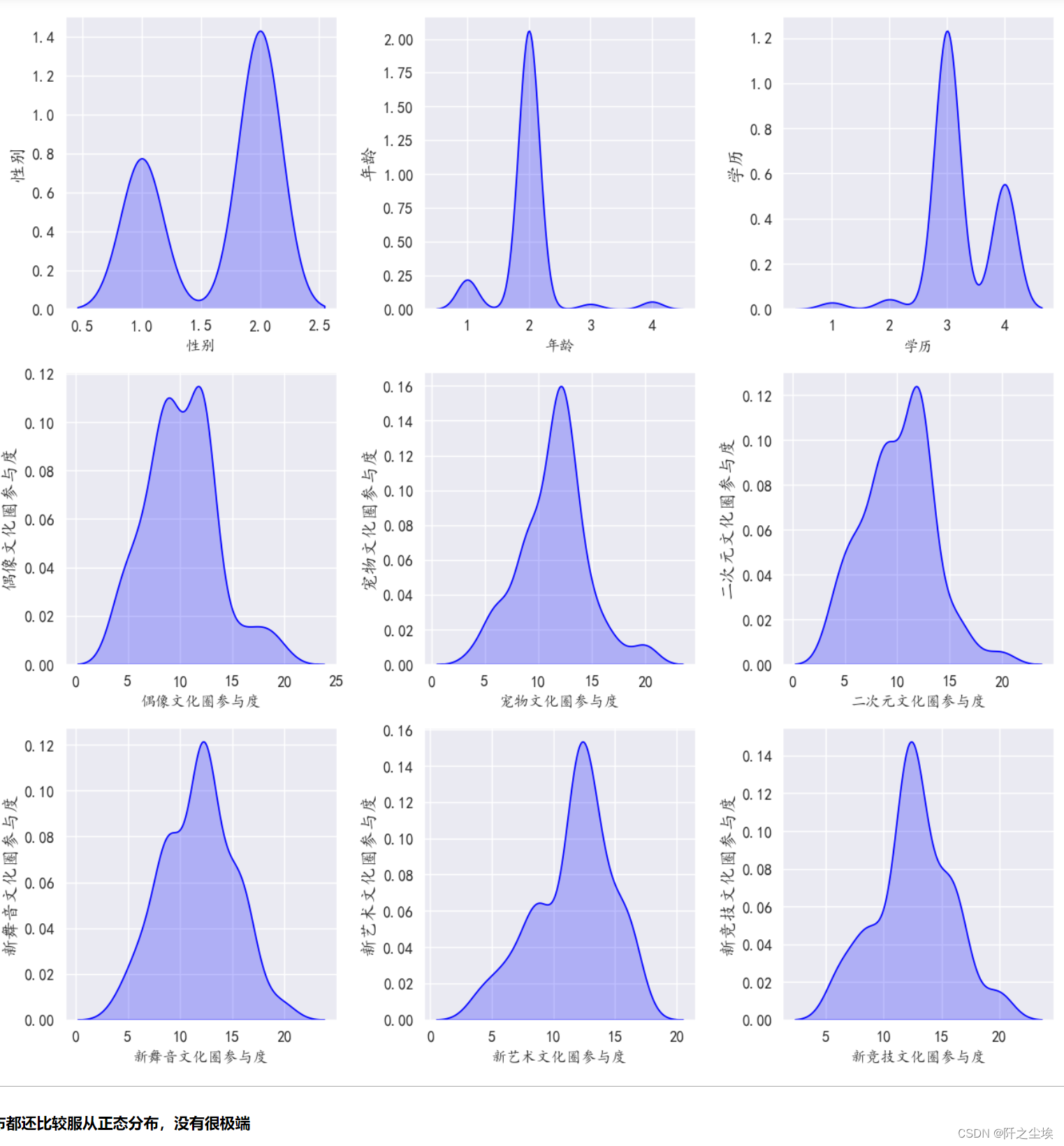
分布都还比较服从正态分布,没有很极端
下面对y分不同的类时画x的小提琴图
fig = plt.figure(figsize=(10,10), dpi=128) # 指定绘图对象宽度和高度
for i in range(9):
plt.subplot(3,3, i + 1) # 2行3列子图
ax = sns.violinplot(x='婚育意愿',y=column[i],width=0.8,saturation=0.9,lw=0.8,palette="Set2",orient="v",inner="box",data=df)
plt.xlabel((['婚育意愿等级']),fontsize=12)
plt.ylabel(column[i], fontsize=12)
plt.tight_layout()
plt.show()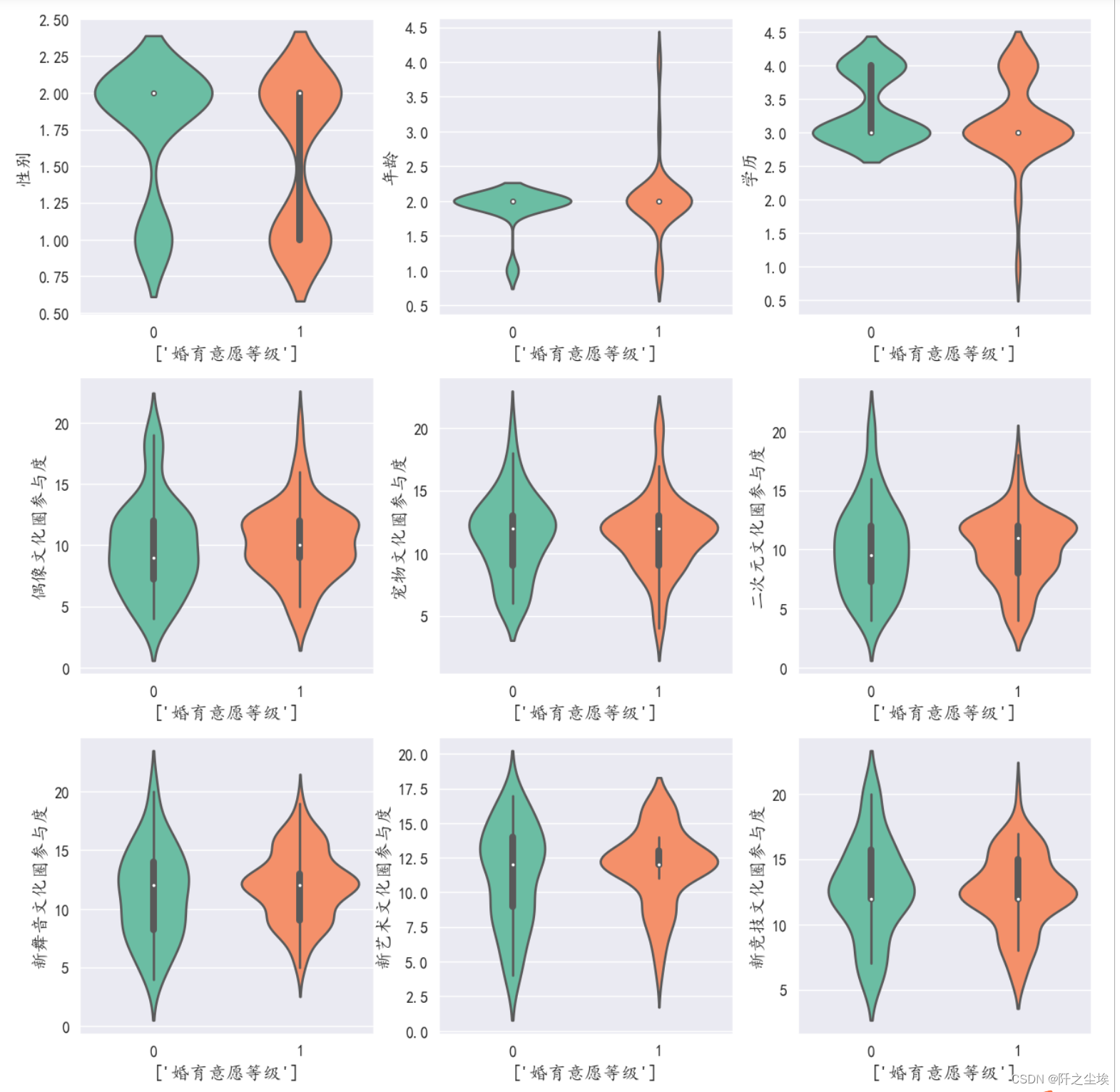
可以分类看出一些结论,比如从第一个图性别上来看,婚育意愿等级为0,也就是婚育意愿等级低的,大多数性别取值都为2,也就是不愿意婚育的人女性偏多。而婚育意愿等级高的性别比例较为均衡 ,男性跟女性都有。
从第二个图年龄来看,婚育意愿等级为0,也就是婚育意愿等级低的人群中年龄取值为2的很多,也就是在21岁到27岁这部分年轻人的婚育意愿都比其他年龄的区间段的人低。
从学历上来看,学历越低的人群,婚育意愿越高。
.......其他的变量类似这样分析,
画皮尔逊相关系数热力图
corr = plt.subplots(figsize = (8,8),dpi=128)
corr= sns.heatmap(df.corr(),annot=True,square=True)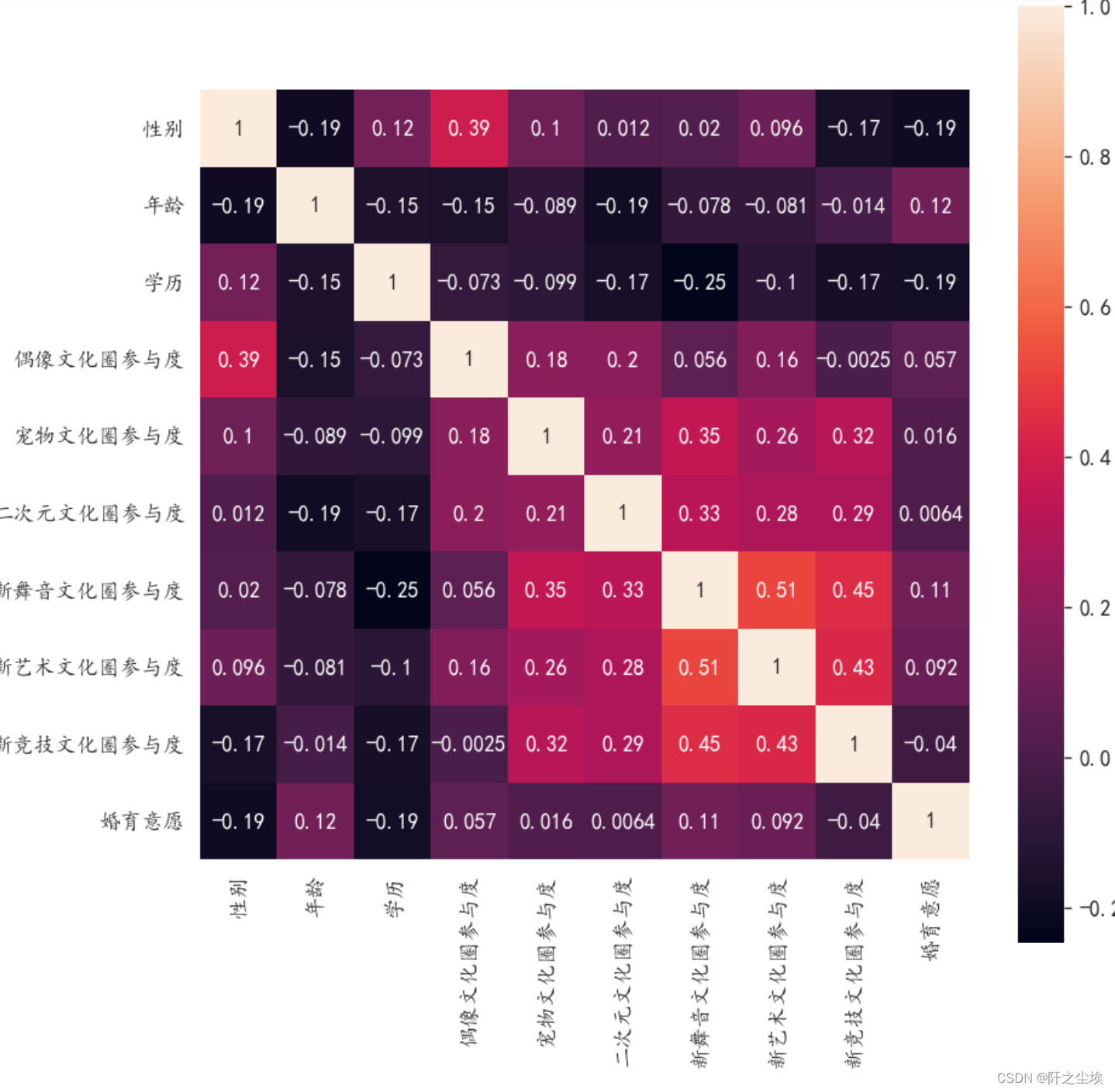
很多x之间的相关系数都不是很高。说明模型应该不会出现多重共线性问题。 和婚育意愿正相关性最高的变量是年龄,说明年龄越大的人婚育意愿越强烈。 和婚育意愿负相关性最高的变量是性别和学历,说明女性(取值为2)比男性(取值1)婚育意愿低。学历越高婚育意愿越低
开始逻辑回归
导入包,取出X和y,数据标准化,写出回归方程式
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import statsmodels.api as sm
X=df.iloc[:,:-1]
y=df.iloc[:,-1]
#标准化,方便可以对比系数
scaler = StandardScaler()
scaler.fit(X)
X_s = scaler.transform(X)
X_s=pd.DataFrame(X_s,columns=X.columns)
all_columns = "+".join(df.columns[:-1])
print('x是:'+all_columns+'\n')
formula = '婚育意愿——' + all_columns
print('逻辑回归方程为:'+formula)
拟合模型
model=sm.Logit(y,X_s)
results=model.fit() 展示模型系数
pd.DataFrame(results.params, columns=['Coefficient']).style.highlight_min()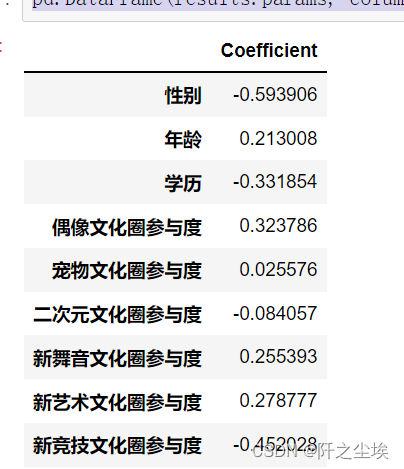
从回归系数可以看出,对于婚育意愿影响最大的是性别,并且是负相关。说明性别取为女性的样本人群更不愿意婚育。
还有学历和二次元文化参与度,新竞技文化参与度都是负的,说明学历越高,越喜欢二次元,越喜欢搞新竞技,就越不愿意婚育。
其他的变量——年龄,偶像文化,宠物文化,音乐艺术参与度,和婚育都是成正相关。说明年龄越大,还有偶像宠物音乐艺术文化参与度越高,越愿意婚育。
查看模型整体信息
results.summary()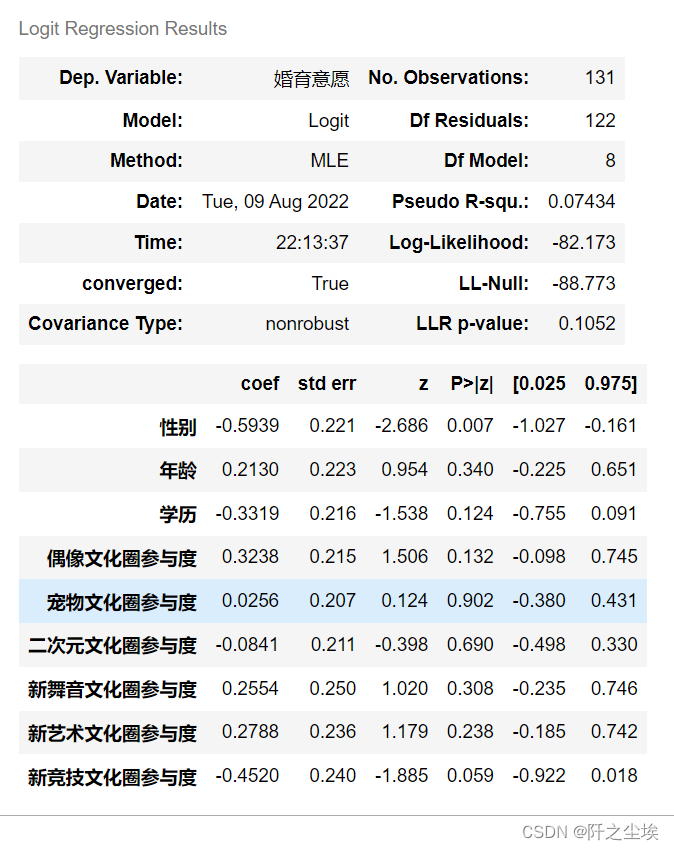
从逻辑回归的显著性来看,和前面结论一致。在p=0.1的显著性水平下,只有性别和新竞技文化参与度是通过了显著性检验。
说明性别和新经济文化参与度对于婚育意愿影响程度是有具有显著性影响的,并且都是负影响。即女性更不愿意婚育,越喜欢弄新竞技文化的人群就越不愿意婚育。
结论
结论是性别是最大的影响因素,女性更不喜欢婚育,婚育意愿比男性更低。
20-27岁的年轻人比其他年龄段的人更不喜欢婚育。
学历越高越不喜欢婚育。
然后是越喜欢打电子竞技的人具有更低的婚育欲望。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)


















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











