





摘要
深度神经网络 (DNN) 中的稀疏性已被广泛研究以压缩和加速资源受限环境中的模型。它通常可以分为非结构化细粒度稀疏性(将分布在神经网络中的多个个体权重归零)和结构化粗粒度稀疏性(修剪神经网络的子网络块)。细粒度稀疏可以实现高压缩比,但对硬件不友好,因此速度增益有限。另一方面,粗粒度的稀疏性不能同时在现代 GPU 上实现明显的加速和良好的性能。在本文中,我们第一个研究从头开始训练(N:M)细粒度结构化稀疏网络,该网络可以在专门设计的 GPU 上同时保持非结构化细粒度稀疏性和结构化粗粒度稀疏性的优势。
具体来说,一个(2 : 4)稀疏网络可以在 Nvidia A100 GPU 上实现 2 倍加速而不降低性能。此外,我们提出了一种新颖有效的成分,一种稀疏精炼的直通估计器(SR-STE),以减轻优化过程中由普通 STE 计算的近似梯度的负面影响。我们还定义了一个度量,即稀疏架构发散 (SAD),以测量训练过程中稀疏网络的拓扑变化。最后,我们用 SAD 证明了 SR-STE 的优势,并通过对各种任务进行综合实验证明了 SR-STE 的有效性。
第四节 方法
N:M细粒度结构化稀疏性
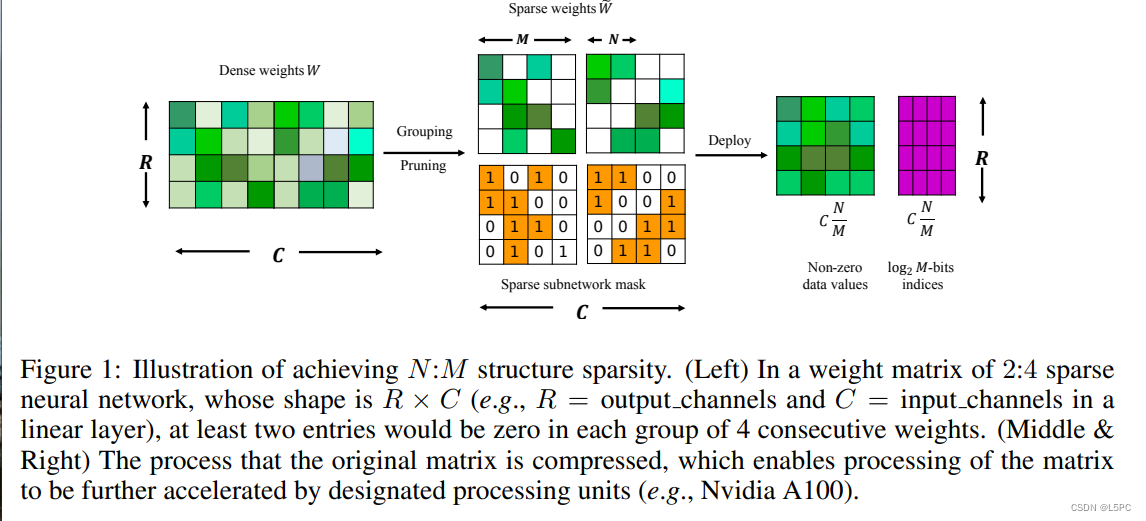
在这里,我们定义了训练具有 N:M 细粒度结构化稀疏性的神经网络的问题。具有 N:M 稀疏性的神经网络满足在网络的每组 M 个连续权重中,最多有 N 个具有非零值的权重。图 1 说明了一个 2:4 的稀疏网络。一般来说,我们的目标是训练一个 N:M 稀疏神经网络:

其中 D 表示观察到的数据,L 表示损失函数,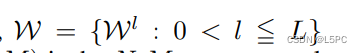 表示 L 层神经网络的参数,S(W, N, M) 是 N:M 稀疏神经网络参数。
表示 L 层神经网络的参数,S(W, N, M) 是 N:M 稀疏神经网络参数。
训练 N:M 稀疏网络的直通估计器 (STE)
训练 N:M 稀疏网络的直接解决方案是简单地扩展直通估计器 (STE) (Bengio et al., 2013) 以执行在线基于幅度的修剪和稀疏参数更新,如图 2(a) 所示. STE 广泛用于模型量化(Rastegari 等人,2016 年),因为没有 STE 的量化函数是不可微的,并且使用 STE 优化的网络在仔细设置下具有良好的性能(Yin 等人,2019 年)。在 STE 中,在训练过程中保持一个密集的网络。在前向传播期间,我们将密集权重 W 投影到满足 N:M 稀疏性的稀疏权重 中。令 w ⊂ W 为 W 中的一组连续 M 个参数, ![]() 中的对应组。 w 的投影可以表示为:
中的对应组。 w 的投影可以表示为:
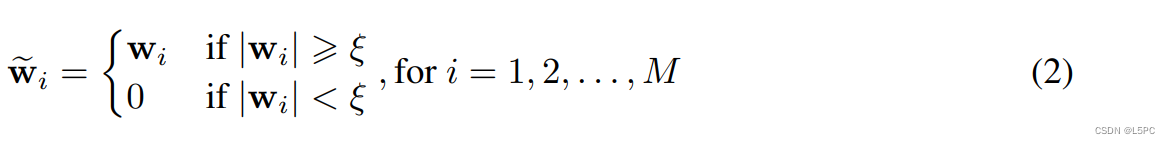
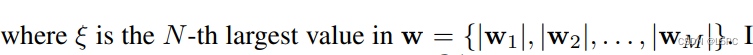 .直观地说,这个投影函数 S(·) 通过在每个连续的 M 参数组中将具有最低有效绝对值的 N 个参数设置为零,同时保持其他参数与以前相同,从而产生稀疏参数 Wf。前向传递中 N:M 稀疏子网络的即时计算如图 1 所示。
.直观地说,这个投影函数 S(·) 通过在每个连续的 M 参数组中将具有最低有效绝对值的 N 个参数设置为零,同时保持其他参数与以前相同,从而产生稀疏参数 Wf。前向传递中 N:M 稀疏子网络的即时计算如图 1 所示。
在反向传播期间不可微的投影函数 S(·) 动态生成 N:M 稀疏子网络。为了在反向传播过程中获得梯度,STE 在稀疏子网络 Wf 的基础上计算子网络的梯度![]() ,可以直接反向投影到密集网络作为密集参数的近似梯度。密集网络的近似参数更新规则(参见附录中的图 2(a))可以表示为
,可以直接反向投影到密集网络作为密集参数的近似梯度。密集网络的近似参数更新规则(参见附录中的图 2(a))可以表示为

其中 Wt 表示迭代 t 的密集参数,γt 表示学习率
使用 STE 的动态修剪分析















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









