







Focal and Global Knowledge Distillation for Detectors
Abstract
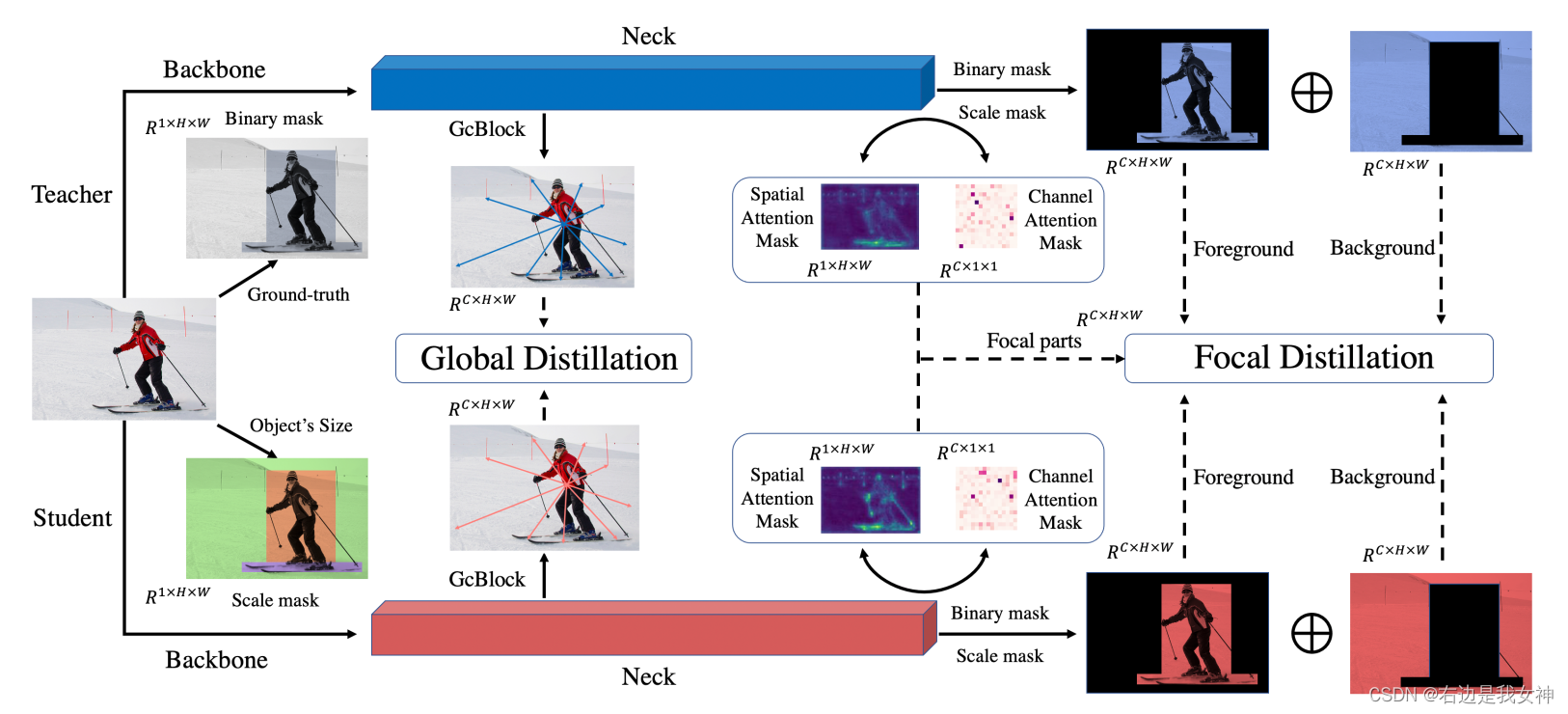
在目标检测当中,老师的特征和学生的特征在不同的区域有很大的变化,尤其是在前景和背景中。因此,如果我们平等地蒸馏,特征图之间的差异会恶化结果。(PS:目标检测中的蒸馏会比对教师模型和原模型的特征图)
翻译:前景不好学,背景很好学,如果这两部分内容进行一样地教授,效果不大好。
因此,我们提出了聚焦且全局蒸馏。聚焦蒸馏分割前景和背景,强迫学生关注教师的关键像素及通道;全局蒸馏则重建不同像素之间的关系,并将这一知识传递给学生。
Method
通常而言,教师和学生之间的蒸馏过程如下所示:
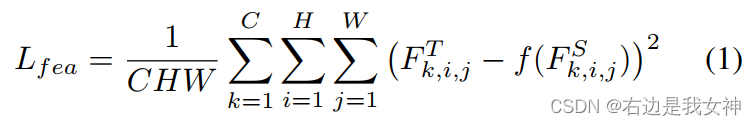
f是调整通道,用于让教师特征和学生特征的通道保持一致。
这样一种方法平等地对待所有部分并且缺乏不同像素之间全局关系的蒸馏。
Focal Distillation
首先设置一个区分前景和背景的mask:
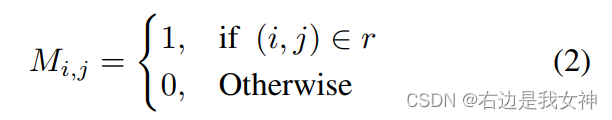
其中r表示GT boxes。
不同大小的目标会有不一样的损失,为了平衡这一问题,本文采用了一个规模化的mask:

Hr、Wr表示GT框的大小,
SENet和CBAM给出结论:关注重要的像素和通道有助于基于CNN的模型得到更好的结果。这里计算了像素或者通道层面的绝对平均值:
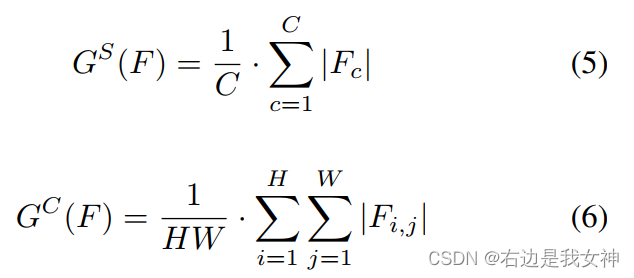
之后得到注意力图:
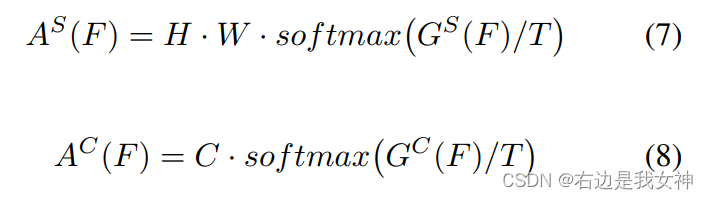
最终,我们的特征图损失如下:
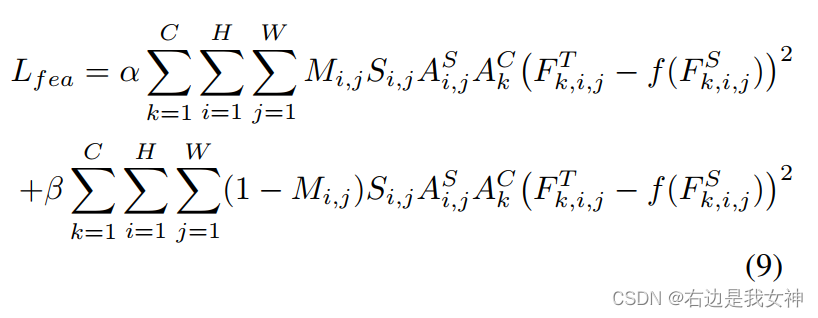
其中的注意力mask采用的是教师模型的。
除此之外,还对学生得到的注意力图和教师的注意力图进行损失计算,其中l是L1loss:
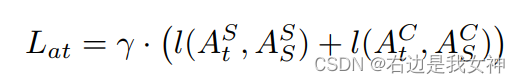
Global Distillation
采用GcBlock来捕捉全局关系信息,并以此进行蒸馏:
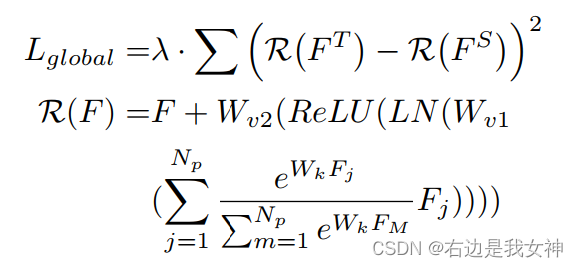
对每一像素的一种重新赋值。
Decoupled Knowledge Distillation
logit蒸馏 和 特征蒸馏
前者计算量小且语义程度高,后者反之。理论来说高维语义特征的效果应该更加好,但事实却不是如此。
实验表明:只有应用NCKD才能获得与经典KD相当甚至更好的结果。
上述实验揭示了logit蒸馏效果不好的原因:经典的KD损失是高度耦合的形式。NCKD损失带有的权重与teacher在目标预测上的置信度是负相关的,即大的预测分数会带来小的权重。值得一提的是,训练样本的置信度普遍较高。
另外,如果训练数据越难,TCKD带给学生的提升就越大。
TCKD适合教难的,NCKD适合教简单的。但是一遇到简单的样本,在经典的KD损失中,NCKD的能力会被抑制。
Co-advise: Cross Inductive Bias Distillation
- 决定学生能力提升的不是教师的能力而是教师给予的归纳偏置;
- 不同归纳偏置的给予可以带来更好的能力提升;
- token与教师的对齐有助于学习。


















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











