






onnx onnxruntime cuda cudnn对应关系
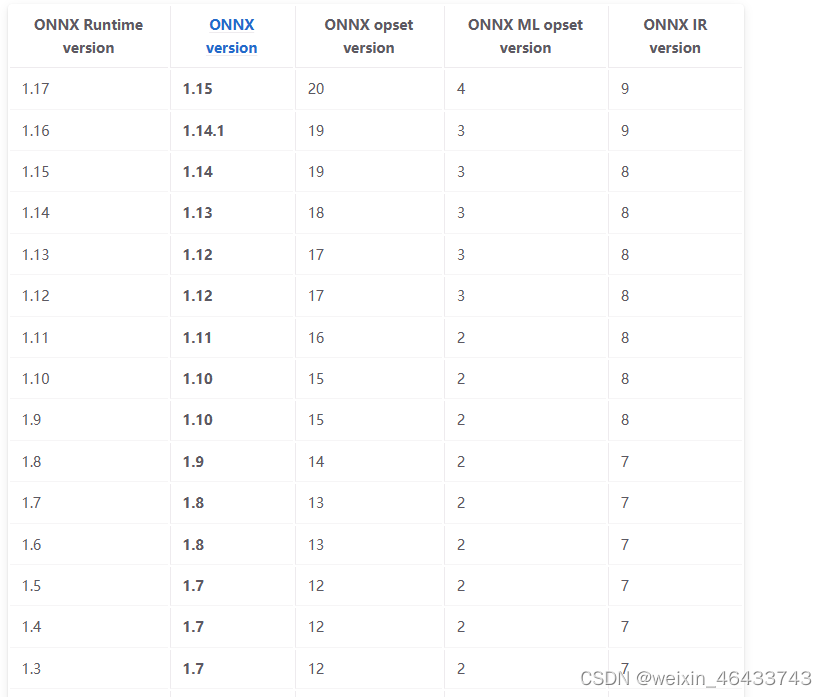
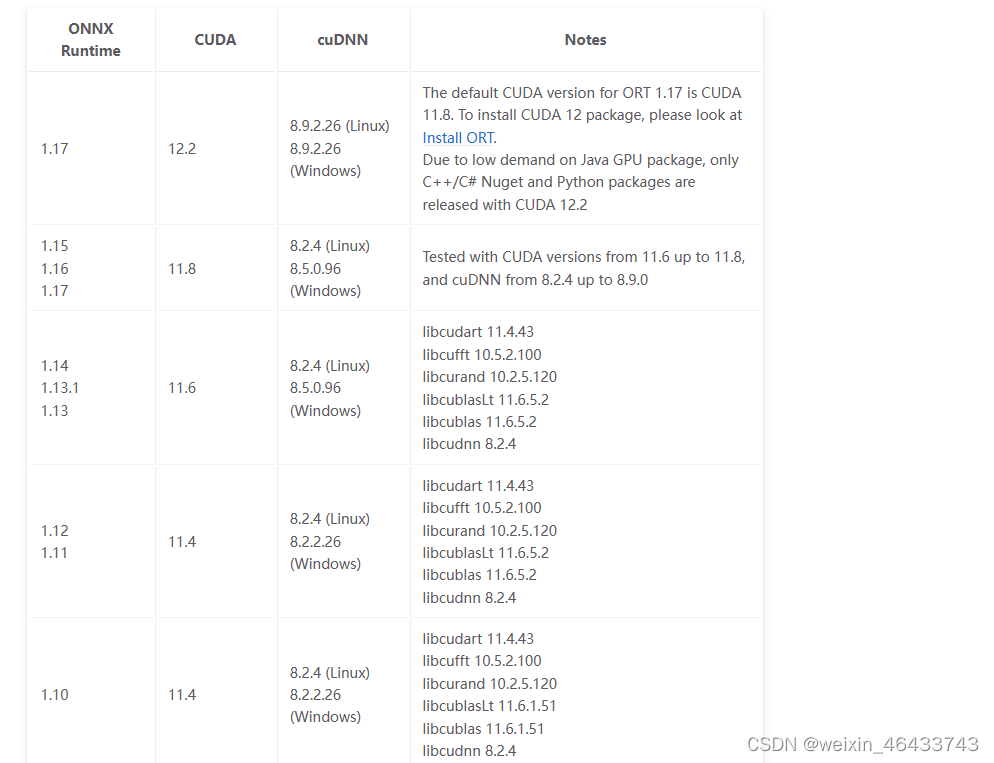
/*onnx 1.12 onnxruntime 1.13.1 cuda 11.6 cudnn 8.5.0.96 */
Ort::SessionOptions session_options;
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "yolov8-onnx");
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
std::vector<std::string> providers = Ort::GetAvailableProviders();
std::vector<std::string>::iterator cudaproviders;
for (cudaproviders = providers.begin(); cudaproviders != providers.end(); ++cudaproviders)
{
std::cout << *cudaproviders << std::endl;
if ((*cudaproviders) == "CUDAExecutionProvider")
break;
}
if (cudaproviders != providers.end())
{
OrtCUDAProviderOptions cudaOption;
cudaOption.device_id = 0;//gpu设备id
cudaOption.arena_extend_strategy = 0;//内存分配和释放策略 0:默认
cudaOption.cudnn_conv_algo_search = OrtCudnnConvAlgoSearchExhaustive;//卷积算法搜索策略,表示在初始化时,进行全面搜索以找到最优的卷积算法,可能会在初始化时增加时间开销,但在推理过程中提高性能
cudaOption.gpu_mem_limit = SIZE_MAX;//设置gpu内存上限,SIZE_MAX无上限
cudaOption.do_copy_in_default_stream = 1;//是否在默认流中进行内存复制。1 表示启用这个选项。启用这个选项可以简化内存管理,但在某些情况下可能会影响性能(例如,当有多个流时)
session_options.AppendExecutionProvider_CUDA(cudaOption);
}
Ort::Session session_(env, onnx_path_name, session_options);














 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









