






1、混淆矩阵
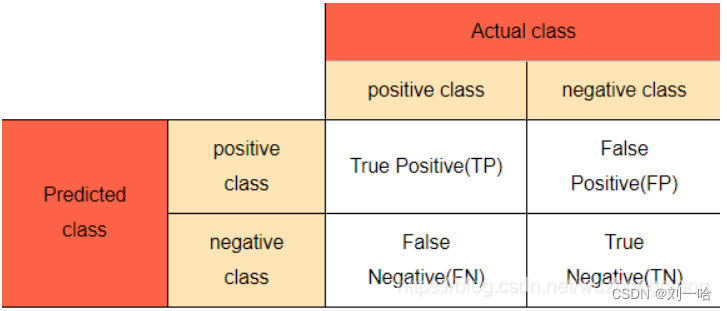

2、准确率

在数据集不平衡时,准确率将不能很好地表示模型的性能。可能会存在准确率很高,而少数类样本全分错的情况,此时应选择其它模型评价指标。
3、精确率(查准率)和召回率(查全率)

positive class的精确率表示在预测为positive的样本中真实类别为positive的样本所占比例;positive class的召回率表示在真实为positive的样本中模型成功预测出的样本所占比例。
4、F1和Fβ

在β=1时,Fβ就是F1值,此时Fβ认为精确率和召回率一样重要;当β>1时,Fβ认为召回率更重要;当0<β<1时,Fβ认为精确率更重要。除了F1值之外,常用的还有F2和F0.5。
5、iou

6、例子
例1



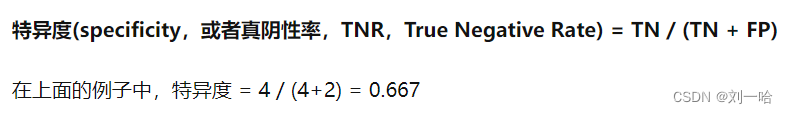

例2——(多类别)

我们将尝试计算 A 类的TP(True Positive)、FP(False Positive)、False Positive 和 FN(False Negative)的值
TruePositive(A):它告诉实际值和预测值相同。 A 类的TP只不过是实际值和预测值相同,这意味着单元格 1 的值为 15。
FalsePositive(A):它告诉实际值是负的,在我们的例子中它是 B 类和 C 类,但模型预测它是正的,即 A 类。它是除了 TP 值之外的相应列的值的相加。
FalsePositive(A) = (单元格 4 + 单元格 7):7+2=9
TrueNegative(A):实际值和预测值的含义相同,对于 A:B 类和 C 类是负分类。 它是所有非A行和列的值相加。
TrueNegative(A) = (单元格 5 + 单元格 6 + 单元格 8 + 单元格 9):15 + 8 +3 + 45= 71
FalseNegative(A):实际值在我们的例子中是正的,它是 A 类,但模型预测它是负的,即 B 类和 C 类。可以通过除 TP 值之外的相邻行来计算的。
FalseNegative(A) = (单元格 2 + 单元格 3): 2 + 3= 5
常用指标
现在是计算 A 类的 Precision、Recall 和 Accuracy 的时候了。
精度Precision:“模型认为正确且确实是正确的样本占模型认为正确的所有样本的概率”
Precision (A) = 正确预测 / 总预测 = 15/24 = 0.625
召回Recall :“模型认为正确且确实是正确的样本占模型认为正确的所有样本的概率”
Recall (A)= 正确分类 / 总实际值 = 15/20 = 0.75
正确率Accuracy :被分对的样本数除以所有的样本数
Accuracy (A) = 正确分类的总数 / 实际分类的总数 = (15 + 15+ 45)/100 = 0.75
iou = TP/(FP+TP+FN)=15/(7+2+15+2+3)= 0.5172
参考:
https://www.csdn.net/tags/NtjaUgxsMDMyOTctYmxvZwO0O0OO0O0O.html
https://www.csdn.net/tags/MtTaEgxsMzUxNDAyLWJsb2cO0O0O.html















 7456
7456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









