







文章目录
UC Irvine Machine Learning新网站的数据使用方法
新网站 https://archive.ics.uci.edu/ :
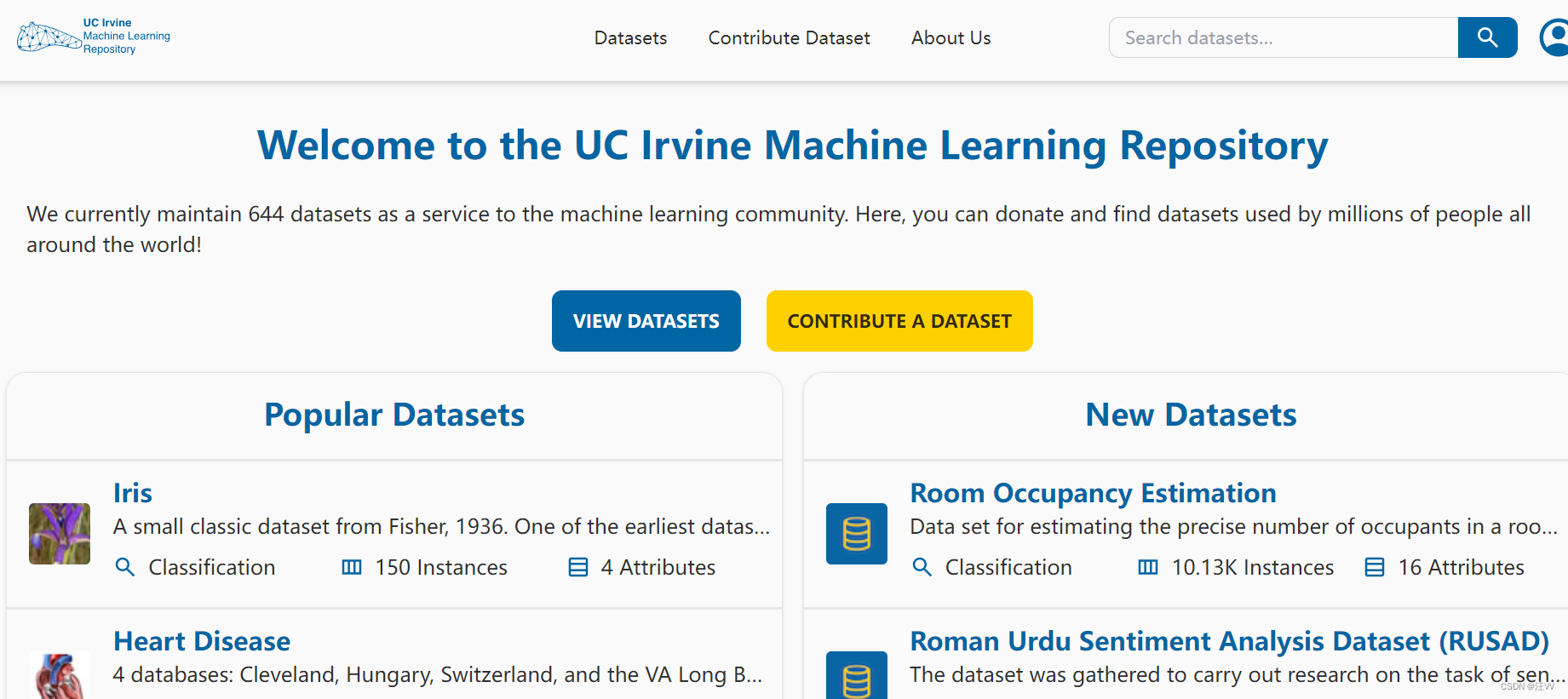
pd.read_csv()读取网站数据
由于新版网站没有Data Folder
老版的的使用方法:
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
除了已知的链接可以使用,其他任意数据已经不能通过该方法了(我在新网站里找了半天也没找到 Data Folder)。
例如:
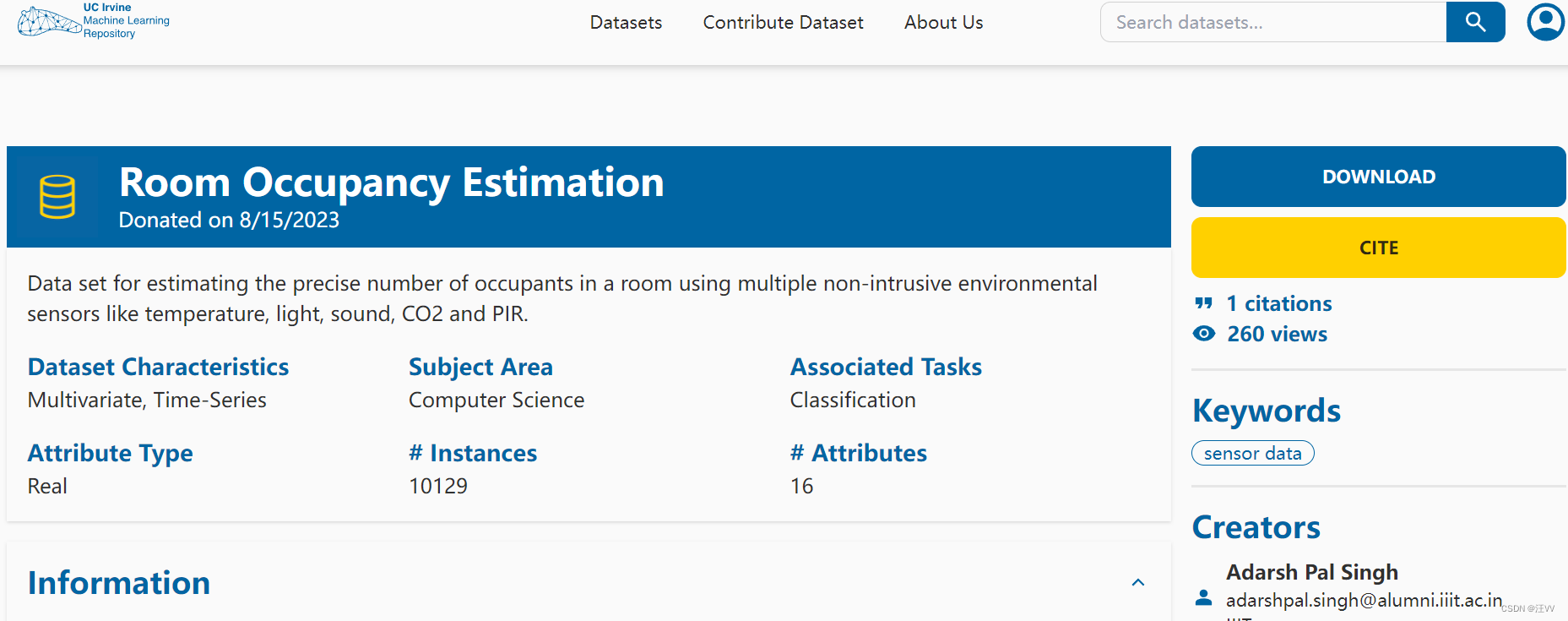
所以只能尝试下载,
下载后的数据类似于:
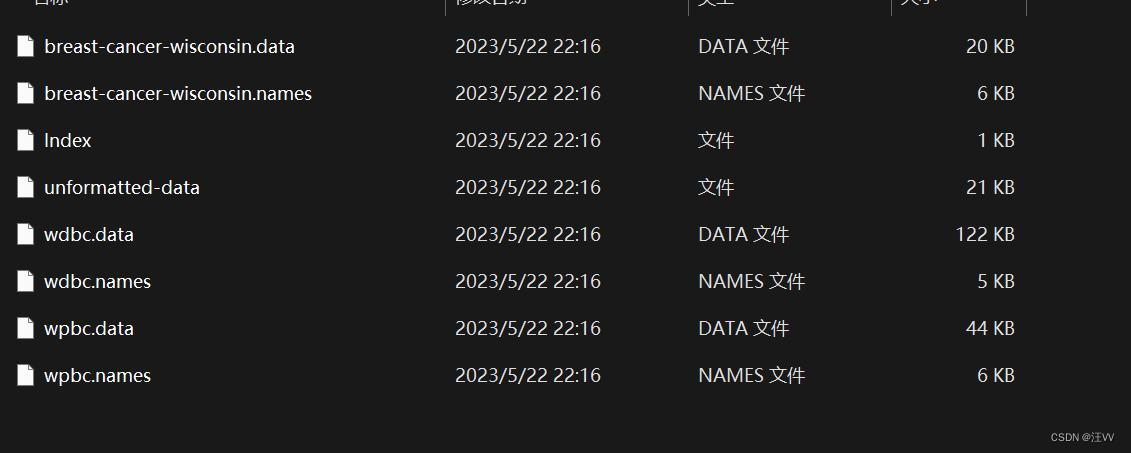
该如何使用呢?
先下载数据,然后其中的.data数据就是想要的,使用pd.read_csv()就可以了。
data = pd.read_csv('../data/breast_cancer_wisconsin_original/breast-cancer-wisconsin.data')
机器学习的部分数据获取类型
pd.read_csv()
- 读取本地csv文件
facebook = pd.read_csv('../data/FBlocation/train.csv')
- 老版uc i ml网站的一些网址
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=names)
- 新版网站数据集需要先下载
data = pd.read_csv('../data/breast_cancer_wisconsin_original/breast-cancer-wisconsin.data')
使用sklean.datasets中自带的数据集
from sklearn.datasets import load_iris
iris = load_iris()
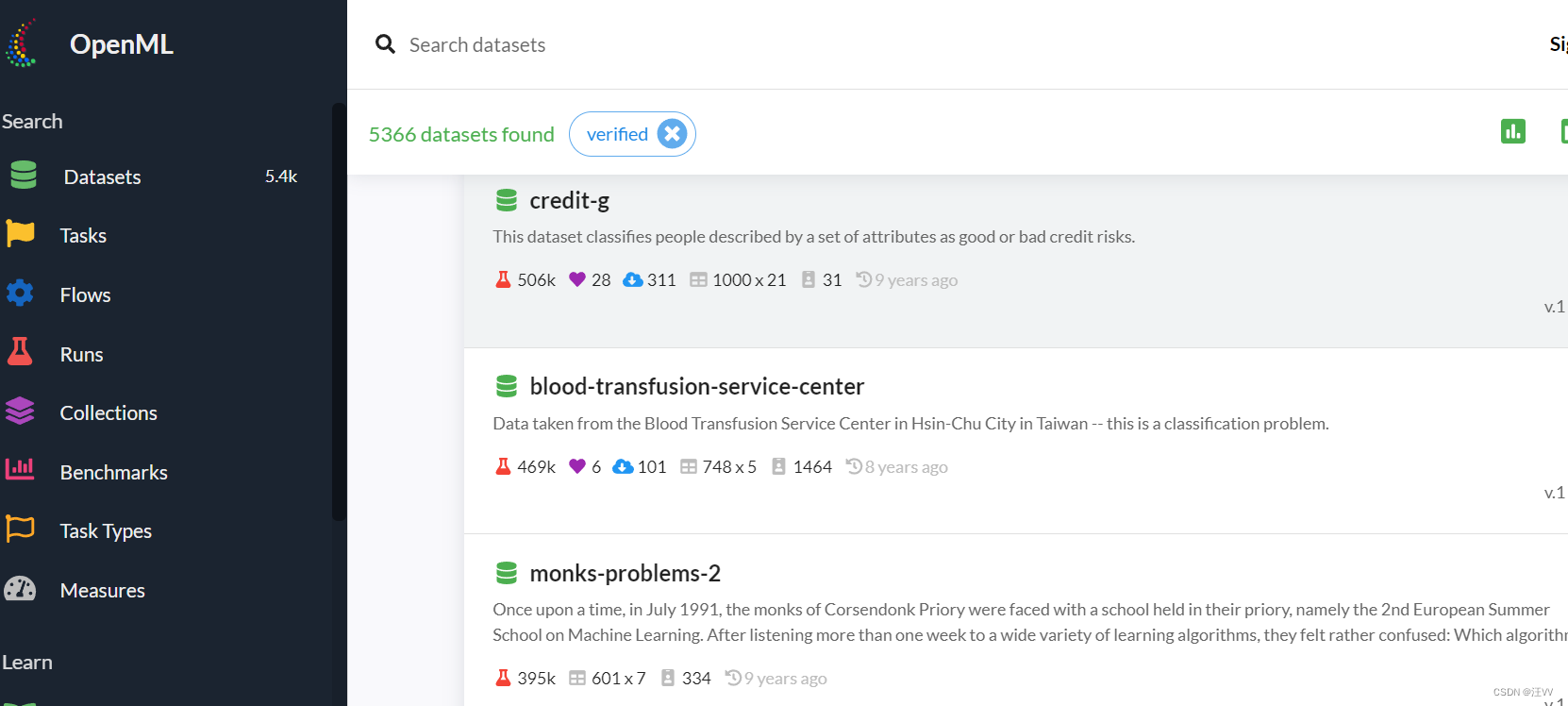
openml数据集
数据集网站:https://www.openml.org/search?type=data&status=active
from sklearn.datasets import fetch_openml
data = fetch_openml(data_id=853)
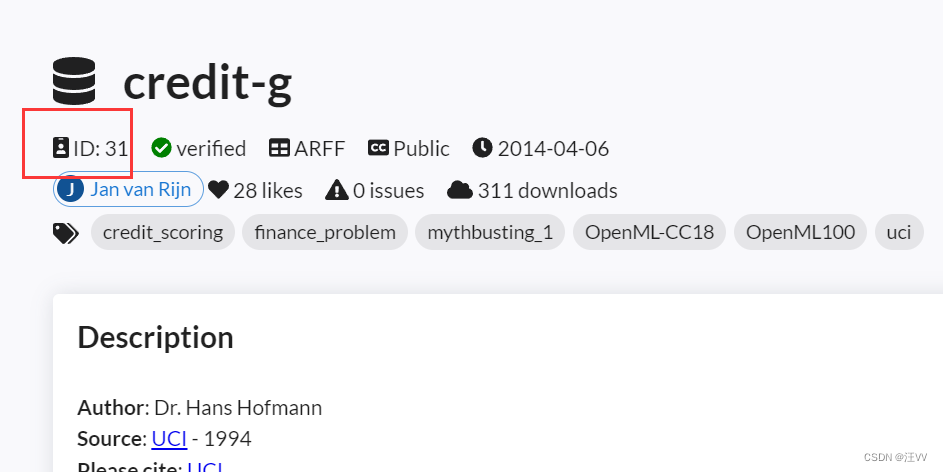
# 其中的data_id是网站中每个数据集的独特标号















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









