






决策树
决策树比较适合分析离散数据
如果是连续数据要先转成离散数据再做分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ByvvtMsM-1665306861964)(C:\Users\25016\AppData\Roaming\Typora\typora-user-images\image-20221003223436971.png)]](https://img-blog.csdnimg.cn/e910b9cd268944b4b49d01b5faa162c1.png)
决策树算法:
-
70年代后期至80年代,Quinlan开发了ID3算法
-
Quinlan改进了ID3算法,称为C4.5算法
-
1984年,多位统计学家提出了CART算法
熵概念
1948年,香农提出了“信息熵”的概念
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要了解大量的信息——》信息量的度量就等于不确定性的多少。
信息熵的计算
信息熵公式:
H
[
x
]
=
−
∑
x
p
(
x
)
l
o
g
2
p
(
x
)
H[x] = -\sum_xp(x)log_{2}p(x)
H[x]=−x∑p(x)log2p(x)
假如有一个普通骰子A,扔出1-6的概率都是1/6
有一个骰子B,扔出6的概率为50%,扔出1-5的概率为10%
有一个骰子C,扔出6的概率为100%
骰子A:
−
(
1
6
⋅
l
o
g
2
1
6
)
⋅
6
≈
2.585
-(\frac{1}{6}\cdot log_{2}\frac{1}{6}) \cdot 6 \approx 2.585
−(61⋅log261)⋅6≈2.585
骰子B:
−
(
1
10
⋅
l
o
g
2
1
10
)
⋅
5
−
1
2
⋅
l
o
g
2
1
2
≈
2.161
-(\frac{1}{10} \cdot log_2\frac{1}{10})\cdot 5 -\frac{1}{2}\cdot log_2\frac{1}{2}\approx2.161
−(101⋅log2101)⋅5−21⋅log221≈2.161
骰子C:
−
1
⋅
l
o
g
2
1
=
0
-1\cdot log_21 =0
−1⋅log21=0
ID3算法
决策树会选择最大化信息增益来对结点进行划分。信息增益计算:
I
n
f
o
(
D
)
=
−
∑
i
=
1
m
p
i
l
o
g
2
(
p
i
)
I
n
f
o
A
(
D
)
=
∑
j
=
1
v
∣
D
j
∣
∣
D
∣
⋅
I
n
f
o
(
D
j
)
G
a
i
n
(
A
)
=
I
n
f
o
(
D
)
−
I
n
f
o
A
(
D
)
Info(D) = -\sum_{i=1}^{m}p_ilog_2(p_i) \\ Info_A(D) = \sum_{j=1}^v\frac{|D_j|}{|D|}\cdot Info(D_j) \\ Gain(A) = Info(D) - Info_A(D)
Info(D)=−i=1∑mpilog2(pi)InfoA(D)=j=1∑v∣D∣∣Dj∣⋅Info(Dj)Gain(A)=Info(D)−InfoA(D)
选择根结点-ID3算法
信息增益:
G
a
i
n
(
A
)
=
I
n
f
o
(
D
)
−
I
n
f
o
A
(
D
)
Gain(A) = Info(D) - Info_A(D)
Gain(A)=Info(D)−InfoA(D)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qfbNtAnm-1665306861966)(C:\Users\25016\AppData\Roaming\Typora\typora-user-images\image-20221009110211406.png)]](https://img-blog.csdnimg.cn/19ebed78c40b4cc995df8cf49d959be2.png)
I n f o ( D ) = − 9 14 l o g 2 ( 9 14 ) − 5 14 l o g 2 ( 5 14 ) = 0.940 Info(D) = -\frac{9}{14}log_2(\frac{9}{14})-\frac{5}{14}log_2(\frac{5}{14})=0.940 Info(D)=−149log2(149)−145log2(145)=0.940
I n f o a g e ( D ) = 5 14 ⋅ ( − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 ) + 4 14 ⋅ ( − 4 4 l o g 2 4 4 − 0 4 l o g 2 0 4 ) + 5 14 ⋅ ( − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 ) = 0.694 Info_age(D) = \frac{5}{14}\cdot(-\frac{2}{5}log_2\frac{2}{5}-\frac{3}{5}log_2\frac{3}{5})\\ + \frac{4}{14}\cdot(-\frac{4}{4}log_2\frac{4}{4}-\frac{0}{4}log_2\frac{0}{4}) \\ + \frac{5}{14}\cdot(-\frac{3}{5}log_2\frac{3}{5}-\frac{2}{5}log_2\frac{2}{5}) \\ = 0.694 Infoage(D)=145⋅(−52log252−53log253)+144⋅(−44log244−40log240)+145⋅(−53log253−52log252)=0.694
G a i n ( a g e ) = I n f o ( D ) − I n f o A ( D ) = 0.940 − 0.694 = 0.246 Gain(age) = Info(D) - Info_A(D) = 0.940 - 0.694 = 0.246 Gain(age)=Info(D)−InfoA(D)=0.940−0.694=0.246
类似:
Gain(income) = 0.029
Gain(student) = 0.151
Gain(credit_rating) = 0.048
选择信息增益最大的为根结点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CNhrMig1-1665306861966)(C:\Users\25016\AppData\Roaming\Typora\typora-user-images\image-20221009111931206.png)]](https://img-blog.csdnimg.cn/5178a76182bf44628f1789d483f40709.png)
C4.5算法
信息增益的方法倾向于首先选择因子数较多的变量
信息增益的改进:增益率
S
p
l
i
t
I
n
f
o
A
(
D
)
=
−
∑
i
=
1
v
∣
D
j
∣
∣
D
∣
⋅
l
o
g
2
(
∣
D
j
∣
∣
D
∣
)
G
r
a
i
n
R
a
t
e
(
A
)
=
G
r
a
i
n
(
A
)
S
p
l
i
t
I
n
f
o
A
(
D
)
SplitInfo_A(D) = -\sum_{i=1}^{v}\frac{|D_j|}{|D|}\cdot log_2(\frac{|D_j|}{|D|})\\ GrainRate(A) = \frac{Grain(A)}{SplitInfo_A(D)}
SplitInfoA(D)=−i=1∑v∣D∣∣Dj∣⋅log2(∣D∣∣Dj∣)GrainRate(A)=SplitInfoA(D)Grain(A)
决策树实战
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
#读入数据
Dtree = open(r'AllElectronics.csv', 'r')
reader = csv.reader(Dtree)
#获取一行数据
headers = reader.__next__()
print(headers)
# 定义两个列表
featureList = []
labelList = []
for row in reader:
# 把label存放到labelList
labelList.append(row[-1])
rowDict = {}
for i in range(1, len(row)-1):
#建立一个数据字典
rowDict[headers[i]] = row[i]
# 把字典存入到list
featureList.append(rowDict)
print(featureList)
# 把数据转换为01表示
vec = DictVectorizer()
x_data = vec.fit_transform(featureList).toarray()
print("x_data" + str(x_data))
# 打印标签名称
print(vec.get_feature_names())
print("labelList" + str(x_data))
#把label转换为01表示
lb = preprocessing.LabelBinarizer()
y_data = lb.fit_transform(labelList)
print('y_data:' + str(y_data))
# 创建决策树分类器
model = tree.DecisionTreeClassifier(criterion='entropy')
#输入数据建立模型
model.fit(x_data, y_data)
#测试
x_test = x_data[0]
print('x_test:' + str(x_test))
predict = model.predict(x_test.reshape(1, -1))
print('predict:' + str(predict))
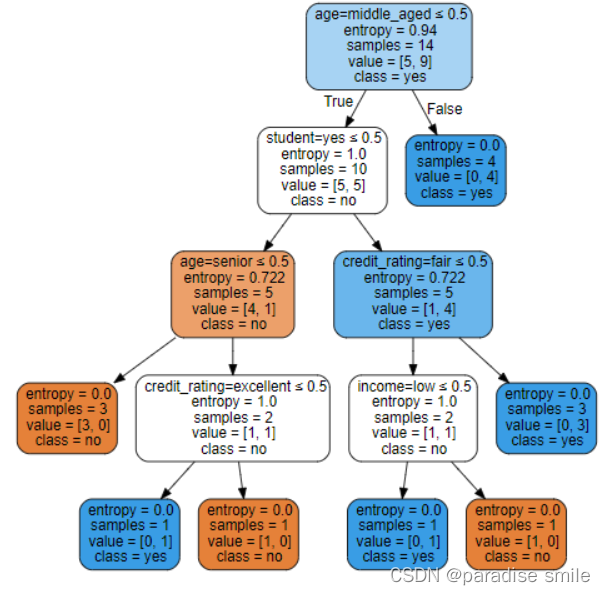
绘制决策树图
import graphviz
dot_data = tree.export_graphviz(model, out_file = None,
feature_names = vec.get_feature_names(),
class_names = lb.classes_,
filled=True,
rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render('computer')
graph















 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









