






背景
生成或者爬取大量的html数据后,提升大模型的OCR能力需要将数据转化为JPG文件。
最开始尝试用 selenium.webdriver.chrome.options来进行快照,但是不仅资源占用不释放,而且html的动画也会影响效果。
后面找到了snapshot_selenium这个库,使用 pyecharts 和 snapshot_selenium 来生成 HTML 文件的截图。
代码原理
功能实现
- 无头浏览器设置:配置了 Chrome 无头模式和其他优化设置。
- 文件路径处理:定义了 HTML 文件的目录,并创建了截图和错误文件夹。
- 错误处理:达到最大重试次数后,文件被移动到错误文件夹
代码实现
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
import os
import shutil
import time
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from tqdm import tqdm
# 设置无头浏览器模式并优化Chrome设置
def get_chrome_options():
chrome_options = ChromeOptions()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.page_load_strategy = 'normal' # 增加页面加载策略
return chrome_options
# 文件夹路径
folder_path = r'error_files\error_files'
# 获取所有HTML文件
html_files = [f for f in os.listdir(folder_path) if f.endswith('.html')]
# 定义截图和错误文件夹路径
screenshot_folder = os.path.join(folder_path, 'snapshot')
error_folder = os.path.join(folder_path, 'error_files')
# 创建文件夹
os.makedirs(screenshot_folder, exist_ok=True)
os.makedirs(error_folder, exist_ok=True)
# 最大重试次数
max_retries = 1
# 处理每个HTML文件
for html_file in tqdm(html_files):
html_file_path = os.path.join(folder_path, html_file)
screenshot_path = os.path.join(screenshot_folder, os.path.splitext(html_file)[0] + ".png")
for attempt in range(max_retries):
try:
# 启动Chrome浏览器
service = ChromeService(ChromeDriverManager().install())
options = get_chrome_options()
browser = Chrome(service=service, options=options)
# 生成截图
make_snapshot(snapshot, html_file_path, screenshot_path, driver=browser)
# 关闭浏览器
browser.quit()
# 显式释放资源
del browser
del service
print(f"Processed: {html_file},success")
break # 成功处理后跳出重试循环
except Exception as e:
print(f"Error processing {html_file} on attempt {attempt + 1}/{max_retries}: {e}")
if attempt == max_retries - 1:
# 将出错文件移动到错误文件夹
error_file_path = os.path.join(error_folder, html_file)
shutil.move(html_file_path, error_file_path)
print(f"Failed to process {html_file} after {max_retries} attempts. Copied to error_files.")
# 缓解CPU负担
time.sleep(0.1)输出结果
大多数html能完美渲染成JPG图片,但是仍然存在数据缺失的数据。
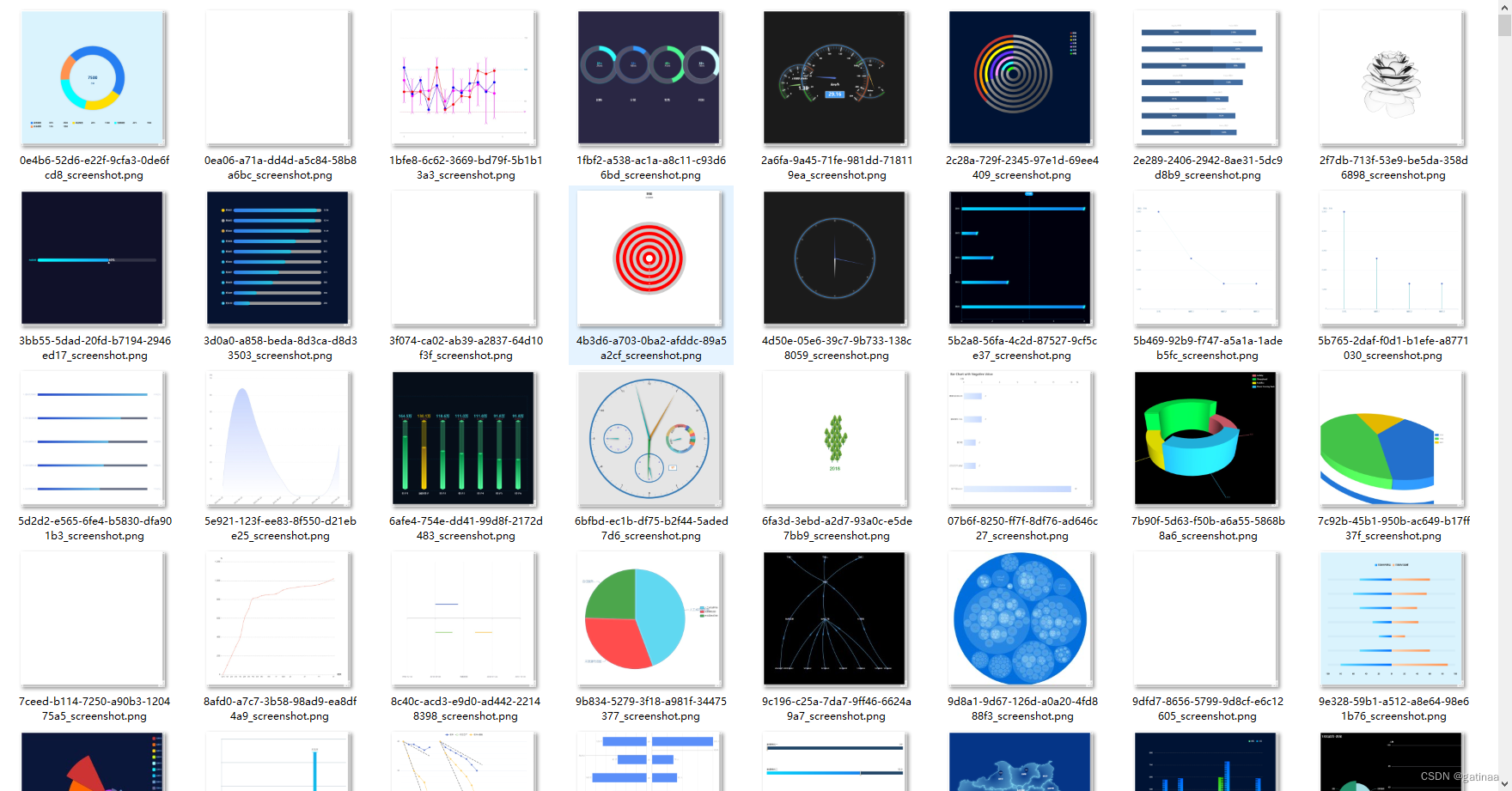
后续处理
有些是不能正常渲染的数据,后续需要进行数据清洗,进行筛选。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











